Scaling Simple Queries with MariaDB Xpand
This page is part of MariaDB's Documentation.
The parent of this page is: Parallel Query Evaluation for MariaDB Xpand
Topics on this page:
Overview
Xpand uses concurrent parallelism and massively parallel processing (MPP) strategies to scale simple queries:
Xpand uses concurrent parallelism to execute the same fragment of a query on different slices in parallel. A different node or CPU core operates on each slice.
Xpand uses massively parallel processing (MPP) strategies to coordinate query execution and minimize data transmission between nodes.
Simple queries include the following:
Xpand evaluates simple queries on a single CPU core on a single node at a time. However, different CPU cores or different nodes can evaluate different simple queries concurrently. As more nodes are added to Xpand, more CPU cores and more memory are available to evaluate simple queries concurrently.
When more nodes are added, Xpand's network overhead does not increase for simple queries:
A simple read-only query will always read the slice from the ranking replica. Every simple read-only query requires 0 or 1 hop.
A simple write query will always update every replica of the slice. Every simple write query requires a maximum number of hops equal to the number of replicas (by default, 2) plus 1.
Due to the sophisticated design, Xpand has tendency to scale linearly for simple queries as more nodes are added.
Compatibility
Information provided here applies to:
MariaDB Xpand 5.3
MariaDB Xpand 6.0
MariaDB Xpand 6.1
Example Tables
The following example tables will be used to show how Xpand evaluates queries in the following sections:
CREATE TABLE test.bundler (
id INT PRIMARY KEY AUTO_INCREMENT,
name CHAR(60) DEFAULT NULL
);
CREATE TABLE test.donation (
id INT PRIMARY KEY AUTO_INCREMENT,
bundler_id INT,
amount DOUBLE,
KEY bundler_key (bundler_id, amount)
);
Since the first table has a primary key and no secondary index, Xpand creates 1 representation. Since the second table has a primary key and a secondary index, Xpand creates 2 representations.
Representation | Index | Table | Distribution Key |
|---|---|---|---|
| Primary Key |
|
|
| Primary Key |
|
|
| Key |
|
|
Scaling Simple Queries
Here, we define simple queries as point selects and inserts.
Example Query
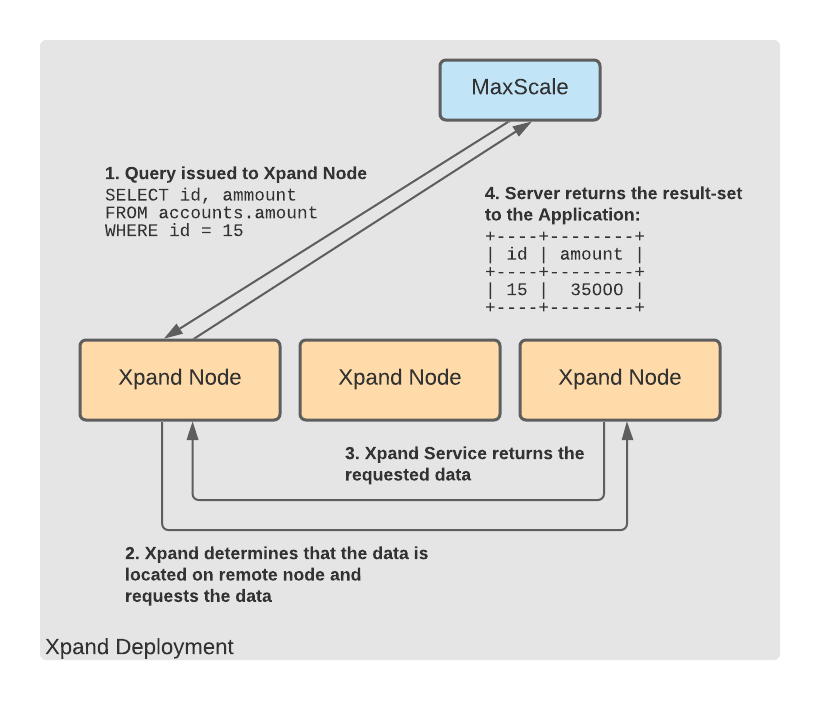
For example, consider the following SELECT statement. Let's consider a simple read (a simple write follows the same path):
sql> SELECT id, amount FROM donation WHERE id = 15;
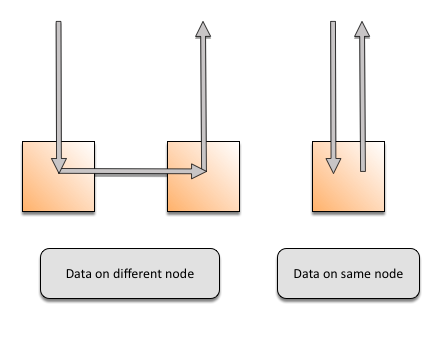
The data will be read from the ranking replica. This can either reside on the same node or require one hop. The diagram below shows both cases. As dataset size and the number of nodes increase, the number of hops that one query requires (0 or 1) does not change. This allows linear scalability of reads and writes. Also, if there are two or more replicas (which is normally the case) there will be at least one hop for writes (since both replicas cannot reside on the same node).
Query Compilation to Fragments
Now, let's dig a little bit deeper to understand how query fragmentation works. Queries are broken down during compilation into fragments that are analogous to a collection of functions. For additional information, please see "Query Optimizer for MariaDB Xpand". Here we'll focus on the logical model. Below, you can see the simple query compiled into two functions. The first function looks up where the value resides and the second function reads the correct value from the container on that node and slice and returns it to the user (the details of concurrency etc. have been left out for clarity).

At a high level, Xpand evaluates the simple query in the following way:
A node receives the query.
The optimizer compiles a query plan comprised of fragments.
The first fragment determines the node that owns the ranking replica for the slice that contains the relevant row (
id=15).The second fragment reads the row from the ranking replica of the slice.
If the original node owns the ranking replica, it reads the row from the slice.
If another node owns the ranking replica, the original node forwards the request to the other node. The other node reads the row from the slice and then returns the row to the original node.
The original node returns the results.
The following graphic shows how the data flows: