Scaling Joins with MariaDB Xpand
This page is part of MariaDB's Documentation.
The parent of this page is: Parallel Query Evaluation for MariaDB Xpand
Topics on this page:
Overview
Xpand uses concurrent parallelism, pipeline parallelism, and massively parallel processing (MPP) strategies to scale joins:
Xpand uses concurrent parallelism to execute the same fragment of a query on different slices in parallel. A different node or CPU core operates on each slice.
Xpand uses pipeline parallelism to execute different fragments of a query on different slices in parallel. A different node or CPU core executes each fragment.
Xpand uses massively parallel processing (MPP) strategies to coordinate query execution and minimize data transmission between nodes.
Xpand minimizes the data transmission for joins. As the number of rows in a join increases, the number of hops per row does not increase. Each row in a join only requires a maximum of 3 hops. The data transmission can have an impact on performance if many large joins are being executed concurrently, so it is very important to have sufficient network bandwidth and minimal network latency between nodes.
Compatibility
Information provided here applies to:
MariaDB Xpand 5.3
MariaDB Xpand 6.0
MariaDB Xpand 6.1
Scaling Joins
Joins require more data movement. However, Xpand is able to achieve minimal data movement because:
Each representation (table or index) has its own distribution, therefore we look up which node/slice to go to next, removing broadcasts.
There is no central node orchestrating data motion. Data moves to the node needing it next. This reduces hops to the minimum possible, given the data distribution.
Example Tables
The following example tables will be used to show how Xpand evaluates queries in the following sections:
CREATE TABLE test.bundler (
id INT PRIMARY KEY AUTO_INCREMENT,
name CHAR(60) DEFAULT NULL
);
CREATE TABLE test.donation (
id INT PRIMARY KEY AUTO_INCREMENT,
bundler_id INT,
amount DOUBLE,
KEY bundler_key (bundler_id, amount)
);
Since the first table has a primary key and no secondary index, Xpand creates 1 representation. Since the second table has a primary key and a secondary index, Xpand creates 2 representations.
Representation | Index | Table | Distribution Key |
|---|---|---|---|
| Primary Key |
|
|
| Primary Key |
|
|
| Key |
|
|
Example Query
Let's look at a query that gets the name and amount for all donations collected by the particular bundler, known by id = 15.
sql> SELECT name, amount from bundler b JOIN donation d on b.id = d.bundler_id WHERE b.id = 15;
The SQL optimizer will look at the relevant statistics including quantiles, hot lists, etc. to determine a plan. The concurrency control for the query is managed by the starting node (that has the session), called the GTM (Global Transaction Manager) node for that query. It coordinates with Local Transaction Manager running on each node. For details see "Concurrency Control for MariaDB Xpand". The chosen plan has the following logical steps:
Start on GTM node
Lookup nodes/slices where
_id_primary_bundlerhas(b.id = 15)and forward to that nodeRead
b.id,namefrom the representation_id_primary_bundlerLookup nodes/slice where
_bundler_key_donationhas(d.bundler_id = b.id = 15)and forward to that nodeJoin the rows and forward to GTM node
Return to user from GTM node
The key here is in Step #4. For joins, when the first row is read, there is a specific value for the join column. Using this specific value, the next node (which might be itself) can be looked up precisely.
Let's see this graphically. Each returned row has gone through the maximum of three hops inside the system. As the number of returned rows increases, the work per row does not. Rows being processed across nodes and rows on the same node running different fragments, use concurrent parallelism by using multiple cores. The rows on the same node and same fragment use pipeline parallelism between them.
Note
We'll assume we have three nodes. For clarity, the three nodes are drawn multiple times to depict every stage of query evaluation.
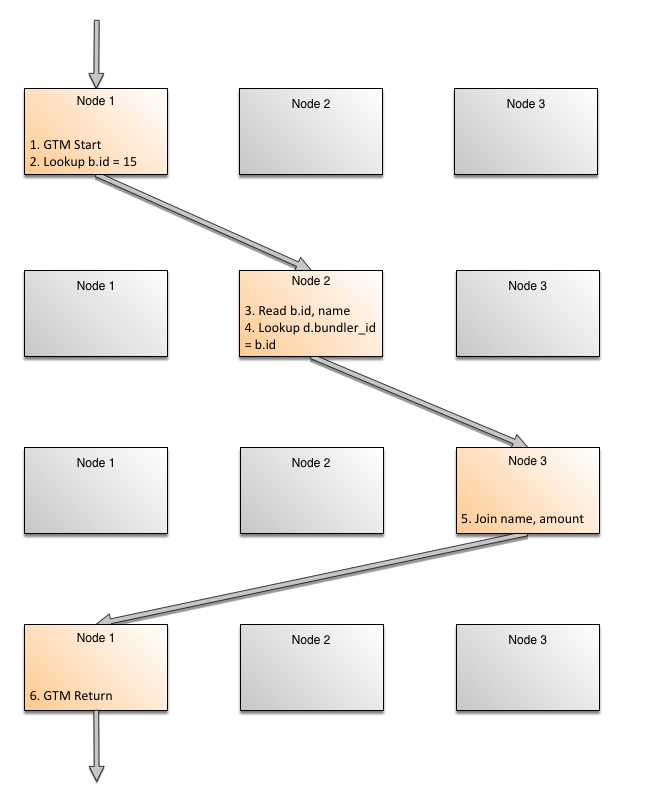
Now that we have seen the path of a single row, let's assume we didn't have the b.id=15 condition. The join will now run in parallel on multiple machines since b.id is present on multiple nodes. Let's look at another view, this time the nodes are drawn once, and the steps flow downward in chronological order. Please note that while the forwarding for join shows that rows may go to any node, this is in context of the entire sets of rows. One single row is usually only forwarded to one node.
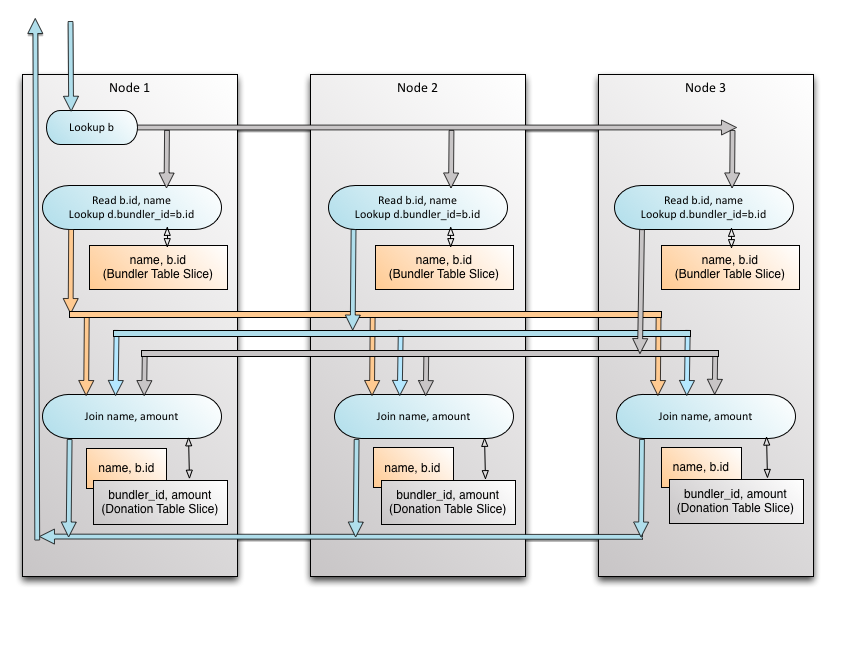
Joins with Massively Parallel Processing (Xpand)
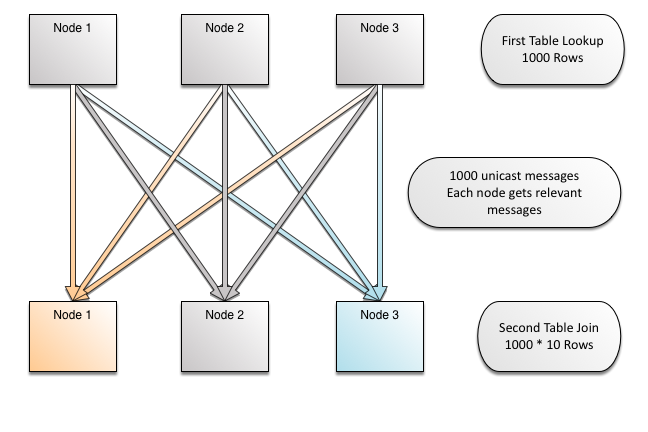
For a single row, we can see how Xpand is able to precisely forward it by using a unicast. Now, let's zoom out and see what a large join means at a system level, and how many rows are forwarded in a cluster. Each node is getting only the rows that it needs. The colors on the receiving nodes match those on the arrows - this is to indicate that rows are flowing correctly to nodes where they will find matching data for successful join.
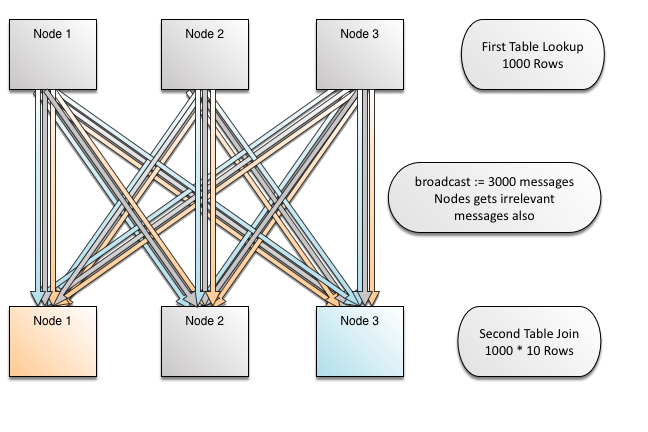
Joins with Broadcast (Competition)
None of our competitors have independent distribution for indexes. All sharding-like approaches distribute indexes according to the primary key. So, given an index on column like bundler_id in the previous example, the system has no clue where that key goes, since distribution was done based on donation.id. This leads to broadcasts, and therefore N way joins do not scale linearly. Notice in the image that broadcasts are shown by nodes getting rows (arrows) of their color - which are the ones that will find matching data for join, and of other colors - where the lookup will show no matching data. Oracle and MySQL cluster do broadcasts like this.
Joins with Single Query Node (Competition)
Xpand uses Massively Parallel Processing (MPP) to leverage multiple cores across nodes to make a single query go faster. Some competing products use a single node to evaluate the query, which leads to a limited speed-up of the query as the volume of data increases. This includes Oracle RAC and NuoDB, neither of which can use cores across multiple nodes to evaluate a join. All the data here needs to flow to a single node that evaluates a single query.

Most competitors are unable to match the linear scaling of joins that Xpand provides. This is because they either broadcast in all cases (except when join is on primary key) or that only a single node ever works on evaluating a single query (other nodes send data over). This allows Xpand to scale better than the competition, giving it a unique value proposition in transactional analytic space (OLAP).