Data Distribution with MariaDB Xpand
This page is part of MariaDB's Documentation.
The parent of this page is: Architecture of MariaDB Xpand
Topics on this page:
Overview
MariaDB Xpand uses a shared-nothing architecture to distribute data between all nodes. Xpand's shared-nothing architecture provides important benefits, including read and write scaling and storage scalability.
Distributed SQL
MariaDB Xpand provides distributed SQL capabilities that support modern massive-workload web applications which require strong consistency and data integrity.
A distributed SQL database consists of multiple database nodes working together, with each node storing and querying a subset of the data. Strong consistency is achieved by synchronously updating each copy of a row.
MariaDB Xpand uses a shared-nothing architecture. In a shared-nothing distributed computing architecture nodes do not share the same memory or storage. Xpand's shared-nothing architecture provides important benefits, including read and write scaling, and storage scalability.
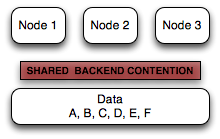
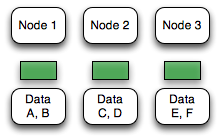
Shared Disk vs. Shared Nothing
Distributed database systems fall into two major categories of data storage architectures: (1) shared disk and (2) shared nothing.
Shared Disk Architecture | Shared Nothing Architecture |
|---|---|
| 
|
Shared disk approaches suffer from several architectural limitations inherent in coordinating access to a single central resource. In such systems, as the number of nodes in the cluster increases, so does the coordination overhead. While some workloads can scale well with shared disk (e.g., small working sets dominated by heavy reads), most workloads tend to scale very poorly -- especially workloads with significant write load.
Xpand uses the shared nothing approach because it's the only known approach that allows for large-scale distributed systems.
Xpand Basics
Xpand has a fine-grained approach to data distribution. The following table summarizes the basic concepts and terminology used by our system. Notice that unlike many other systems, Xpand uses a per-index distribution strategy.
Distribution Concepts Overview
Xpand Distribution Concepts | |
|---|---|
Representation | Each table contains one or more indexes. Internally, Xpand refers to these indexes as representations of the table. Each representation has its own distribution key (also known as a partition key or a shard key), meaning that Xpand uses multiple independent keys to slice the data in one table. This is in contrast to most other distributed database systems, which use a single key to slice the data in one table. Each table must have a primary key. If the user does not define a primary key, Xpand will automatically create a hidden primary key. The base representation contains all of the columns within the table, ordered by the primary key. Non-base representations contain a subset of the columns within the table. |
Slice | Xpand breaks each representation into a collection of logical slices using consistent hashing. By using consistent hashing, Xpand can split individual slices without having to rehash the entire representation. |
Replica | Xpand maintains multiple copies of data for fault tolerance and availability. There are at least two physical replicas of each logical slice, stored on separate nodes. Xpand supports configuring the number of replicas per representation. For example, a user may require three replicas for the base representation of a table, and only two replicas for the other representations of that table. |
Independent Index Distribution
Xpand distributes data between nodes using independent index distribution:
Each table is divided into representations that correspond to the table's Primary Key and each secondary index. Each representation has its own distribution key based on the index.
Each representation is divided into logical slices by hashing the distribution key.
Each slice is stored as multiple physical replicas. Each replica for a slice is stored on a different node to ensure fault tolerance.
Since each index has its own representation, Xpand's query optimizer can support a broad range of distributed query evaluation plans.
Example Table with Multiple Representations
The following example table consists of a primary key and two indexes, so Xpand creates three representations:
CREATE TABLE test.xpand_dist_example (
id BIGINT PRIMARY KEY,
col1 INT,
col2 INT,
col3 VARCHAR(64),
KEY k1 (col2),
KEY k2 (col3, col1)
);
Let's assume that our example table contains some data:
INSERT INTO test.xpand_dist_example
(col1, col2, col3)
VALUES
(16, 36, "january"),
(17, 35, "february"),
(18, 34, "march"),
(19, 33, "april"),
(20, 32, "may");
SELECT * FROM test.xpand_dist_example;
+----+------+------+----------+
| id | col1 | col2 | col3 |
+----+------+------+----------+
| 1 | 16 | 36 | january |
| 2 | 17 | 35 | february |
| 3 | 18 | 34 | march |
| 4 | 19 | 33 | april |
| 5 | 20 | 32 | may |
+----+------+------+----------+
In the following sections, this example table is used to show how Xpand distributes and balances data.
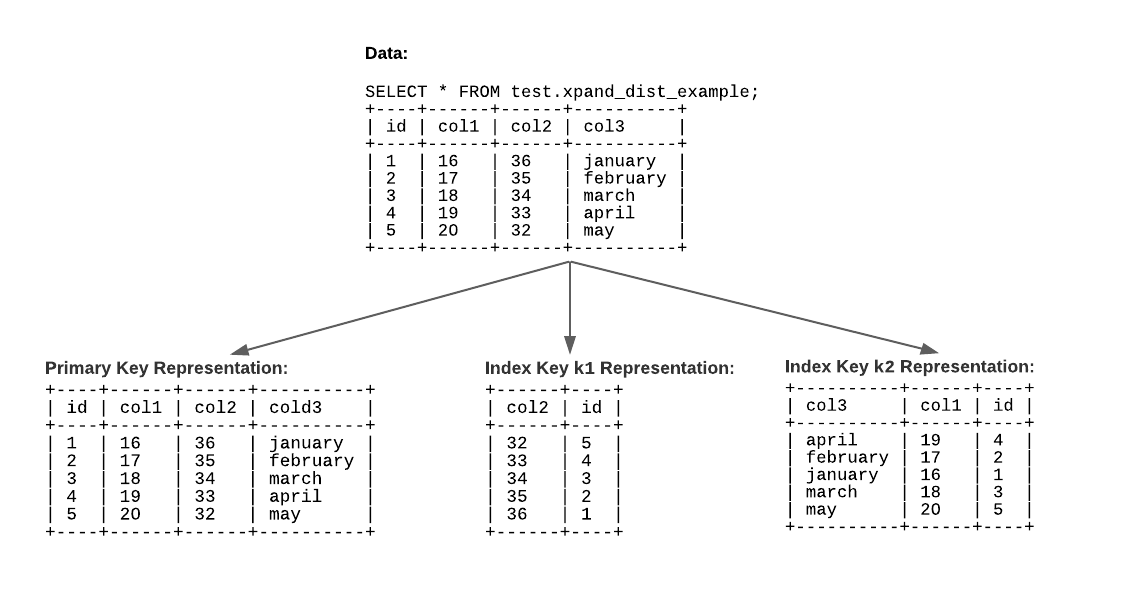
Representations
Xpand divides each table into a representation for each index on the table. Each representation has a different distribution key defined by the index associated with the representation. The Primary Key produces the base representation, which contains all columns in the table. Other indexes produce other representations, which contain the indexed columns. Slices of each representation contain different rows. Xpand hashes the distribution key to determine which slice a row belongs to.
The example table consists of a primary key and two secondary indexes, so it has three representations:
The base representation uses the primary key column as the distribution key. The slices for this representation contain all table columns.
The
k1representation uses thecol2column as the distribution key. The slices for this representation also contain the primary key column.The
k2representation uses thecol3andcol1columns as the distribution key. The slices for this representation also contain the primary key column.
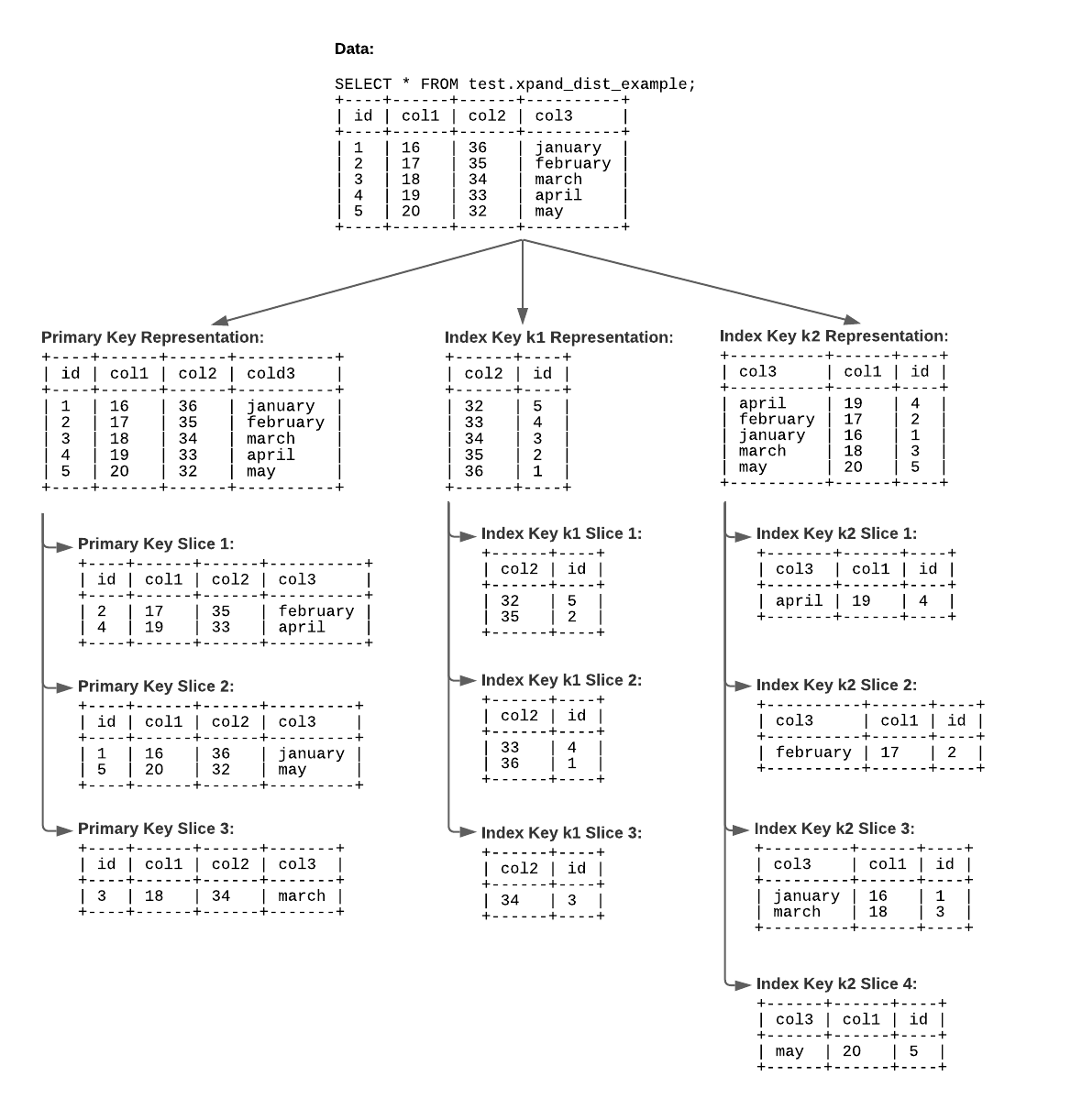
Slices
Xpand horizontally divides each representation into slices:
The slice for a given row is determined by applying a consistent hashing algorithm on the distribution key.
Each representation is sliced independently.
Each representation of the same table can have a different number of slices.
By default, each representation starts with one slice per node. However, the initial number of slices for a table can be configured using the
SLICEtable option.If a slice gets too large, Xpand automatically splits the slice into multiple slices. The maximum slice size is based on the
rebalancer_split_threshold_kbsystem variable. By default, the maximum size is 8 GB.
The example table consists of three representations, and each representation has a different number of slices:
Replicas
Xpand writes slices to disk as replicas. Xpand maintains multiple copies of each slice.
In the default configuration, Xpand automatically maintains two replicas of each slice on disk. However, Xpand can be configured to maintain more replicas using the
REPLICAStable option or by setting MAX_FAILURES .Each replica for a given slice is stored on a different node.
Replicas are distributed among the nodes for redundancy and to balance reads, writes, and disk usage.
Xpand can make new replicas available online, without suspending or blocking writes to the slice.
The example table consists of two replicas for each slice with the default configuration:
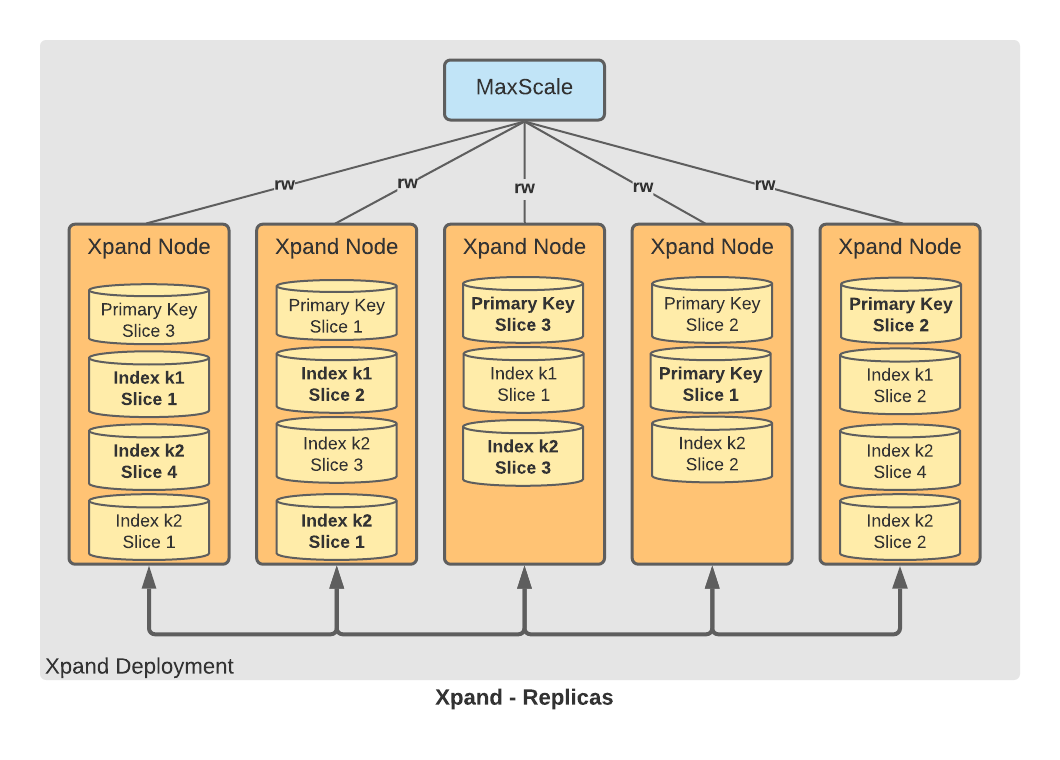
When the REPLICAS table option is set to ALLNODES, Xpand maintains a replica of each slice on each node. This provides the maximum in fault tolerance and read performance, but at the expense of write performance and disk usage.
When Xpand is configured to maintain additional physical replicas, Xpand's overhead increases for updates to logical slices, because each additional replica is updated synchronously when the slice is updated. Each additional replica requires the transaction to perform:
Additional network communication to transfer the updated data to the node hosting the replica
Additional disk writes to update the replica on disk
In some cases, the additional overhead can decrease throughput and increase commit latency, which can have negative effects for the application. If you choose to configure Xpand to maintain additional replicas, it is recommended to perform performance testing.
Consistent Hashing
Xpand uses consistent hashing for data distribution. Consistent hashing allows Xpand to dynamically redistribute data without rehashing the entire data-set.
Xpand hashes each distribution key to a 64-bit number. It then divides the space into ranges. Each range is owned by a specific slice. The table below illustrates how consistent hashing assigns specific keys to specific slices.
Slice | Hash Range | Key Values |
|---|---|---|
| min-100 |
|
| 101-200 |
|
| 201-max |
|
Xpand assigns each slice to a node based on data capacity and to balance the load for reads, writes, and disk usage:
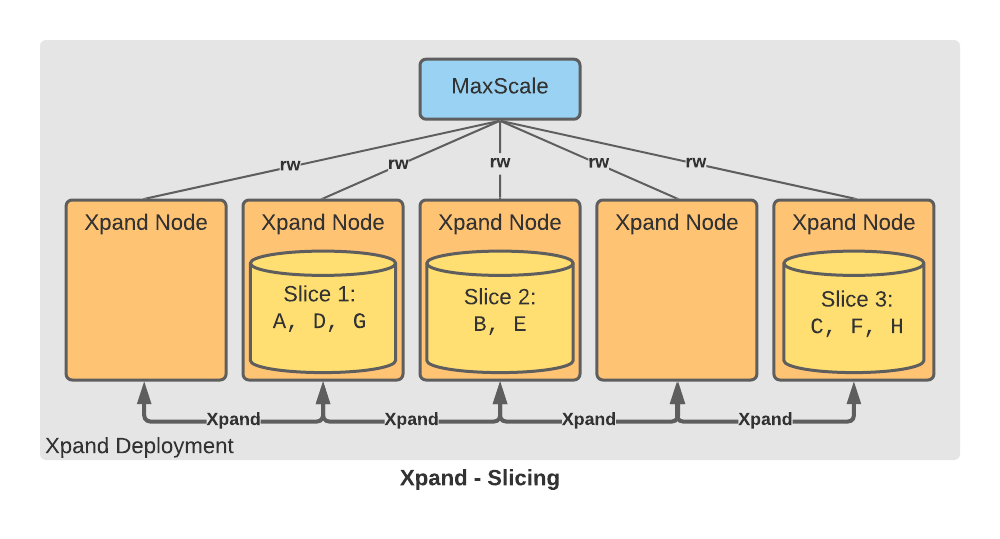
If a slice grows larger than rebalancer_split_threshold_kb (by default, 8 GB), the Rebalancer automatically splits the slice into multiple slices and distributes the original rows between the new slices.
For example, let's say that slice 2 has grown larger than rebalancer_split_threshold_kb:
Slice | Hash Range | Key Values | Size |
|---|---|---|---|
| min-100 |
| 768 MB |
| 101-200 |
| 8354 MB (too large) |
| 201-max |
| 800 MB |
Note the increased size of slice 2 in the diagram:
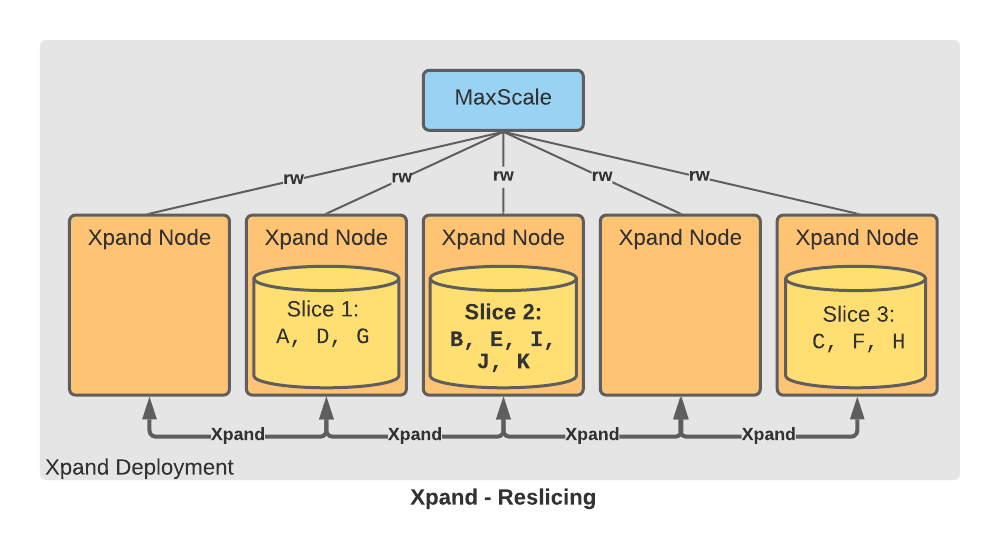
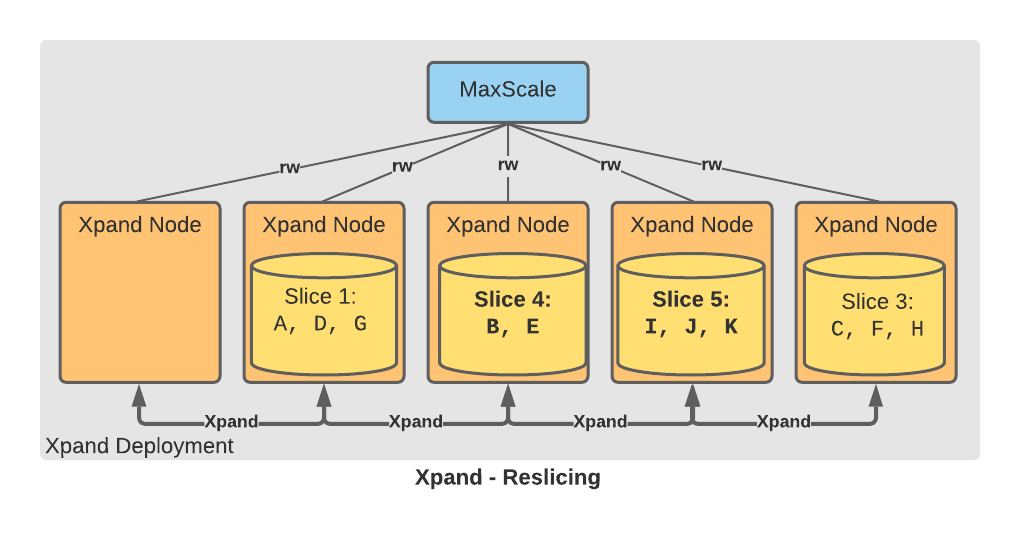
The Rebalancer automatically detects that the split threshold has been exceeded, so it schedules a slice-split operation. During the slice-split operation, the hash range for slice 2 is divided into two ranges, which are associated with two new slices called slice 4 and slice 5. After the data is moved to slice 4 and slice 5, slice 2 is removed:
Slice | Hash Range | Key Values | Size |
|---|---|---|---|
| min-100 |
| 768 MB |
| 201-max |
| 800 MB |
| 101-150 |
| 4670 MB |
| 151-200 |
| 4684 MB |
The Rebalancer does not modify slice 1 or slice 3. The Rebalancer only modifies the slices being split, which allows for very large data reorganizations to proceed in small chunks.
Single Key vs. Independent Index Distribution
It's easy to see why table-level distribution provides very limited scalability. Imagine a schema dominated by one or two very large tables (billions of rows). Adding nodes to the system does not help in such cases since a single node must be able to accommodate the entire table.
Why does Xpand use independent index distribution rather than a single-key approach? The answer is two-fold:
Independent index distribution allows for a much broader range of distributed query plans that scale with cluster node count.
Independent index distribution requires strict support within the system to guarantee that indexes stay consistent with each other and the main table. Many systems do not provide the strict guarantees required to support index consistency.
Let's examine a specific use case to compare and contrast the two approaches. Imagine a bulletin board application where different topics are grouped by threads, and users are able to post into different topics. Our bulletin board service has become popular, and we now have billions of thread posts, hundreds of thousands of threads, and millions of users.
Let's also assume that the primary workload for our bulletin board consists of the following two access patterns:
Retrieve all posts for a particular thread in post id order.
For a specific user, retrieve the last 10 posts by that user.
We could imagine a single large table that contains all of the posts in our application with the following simplified schema:
-- Example schema for the posts table.
sql> CREATE TABLE thread_posts (
post_id bigint,
thread_id bigint,
user_id bigint,
posted_on timestamp,
contents text,
primary key (thread_id, post_id),
key (user_id, posted_on)
);
-- Use case 1: Retrieve all posts for a particular thread in post id order.
-- desired access path: primary key (thread_id, post_id)
sql> SELECT *
FROM thread_posts
WHERE thread_id = 314
ORDER BY post_id;
-- Use case 2: For a specific user, retrieve the last 10 posts by that user.
-- desired access path: key (user_id, posted_on)
sql> SELECT *
FROM thread_posts
WHERE user_id = 546
ORDER BY posted_on desc
LIMIT 10;
Single Key Approach
With the single key approach, we are faced with a difficult decision: Which key do we choose to distribute the posts table? As you can see with the table below, we cannot choose a single key that will result in good scalability across both use cases.
Distribution Key | Use case 1: posts in a thread | Use case 2: top 10 posts by user |
|---|---|---|
thread_ | Queries that include the | Queries that do not include the |
user_ | Queries that do not include the | Queries that include a |
One possibility with such a system could be to maintain a separate table that includes the user_id and posted_on columns. We can then have the application manually maintain this index table.
However, that means that the application must now issue multiple writes, and accept responsibility for data consistency between the two tables. And imagine if we need to add more indexes? The approach simply doesn't scale. One of the advantages of a database is automatic index management.
Independent Index Key Approach
Xpand will automatically create independent distributions that satisfy both use cases. The DBA can specify to distribute the base representation (primary key) by thread_id, and the secondary key by user_id. The system will automatically manage both the table and secondary indexes with full ACID guarantees.
For more detailed explanation consult our "Evaluation Model for MariaDB Xpand" section.
Cache Efficiency
Unlike other systems that use master-slave pairs for data fault tolerance, Xpand distributes the data in a more fine-grained manner as explained in the above sections. Our approach allows Xpand to increase cache efficiency by not sending reads to secondary replicas.
Consider the following example. Assume a cluster of 2 nodes and 2 slices A and B, with secondary copies A' and B'.
Read from both copies | Read from primary copy only | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| ||||||||||||
If we allow reads from both primary and secondary replicas, then each node will have to cache contents of both A and B. Assuming 32GB of cache per node, the total effective cache of the system becomes 32GB. | By limiting the reads to primary replica only, we make node 1 responsible for A only, and node 2 responsible for B only. Assuming 32GB cache per node, the total effective cache footprint becomes 64GB, or double of the opposing model. |