High Level Architectural Overview for MariaDB Xpand
This page is part of MariaDB's Documentation.
The parent of this page is: Architecture of MariaDB Xpand
Topics on this page:
Overview
MariaDB Xpand is a clustered RDBMS that ensures ACID compliance for transaction processing while simultaneously providing easy scalability and fault tolerance. An Xpand cluster is comprised of three or more nodes (networked homogeneous servers).
Xpand utilizes a shared nothing architecture. Each node within a cluster can perform any read or write. To add capacity to your database, simply add more nodes.
The primary components of Xpand that help achieve performance and scale are:
The Global Transaction Manager (GTM), which coordinates the processing of a given transaction.
The Rebalancer, which automatically distributes data across the cluster.
The Sierra Database Engine, which determines an optimal query execution plan and then executes that plan on distributed data.
The diagram below shows how a typical query is processed by Xpand.

Global Transaction Manager
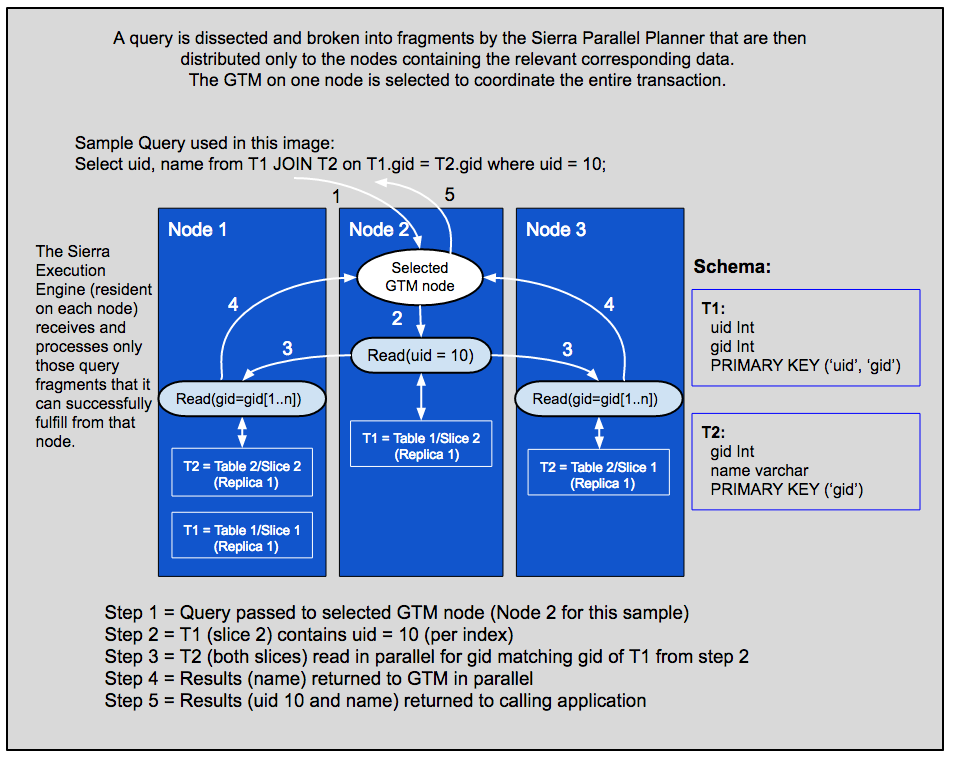
Query processing within Xpand begins when one node of the cluster is selected as the Global Transaction Manager (GTM), typically via a load balancer that distributes connections across the cluster. The GTM then manages all aspects of that transaction by directing each step of query execution, confirming that each step completes successfully, then collecting and finalizing the query results before returning them to the caller.
Xpand compiles queries into executable query fragments that the GTM distributes to the appropriate node(s) for execution. As intermediate results become available, they are returned to the GTM. Once all query fragments have been executed successfully, the GTM finalizes the results and returns them to the client, application, or user.
Rebalancer
Distributed processing would not be possible nor necessary if Xpand's data had not previously been distributed throughout the cluster. To accomplish this, Xpand utilizes a patented data distribution methodology that is administered by its Rebalancer. The Rebalancer arranges data within the cluster to ensure that reads and writes are always balanced. It also guarantees that multiple copies (replicas) of data are maintained throughout the cluster to ensure fault tolerance. If a node is lost due to an unexpected failure, no data will be lost. The Rebalancer will automatically ensure that redundant replicas are created and maintained. It further accommodates the changing size of a cluster by re-balancing data to new nodes as they are added and moving data off nodes that are marked for removal, all while the database remains online.
The Rebalancer uses a consistent hashing algorithm to assign each table row to a given "slice" of that table and provides a map of all slices to every node. This allows Xpand to quickly and easily ascertain the location of relevant data. The Rebalancer runs continuously in the background without interfering with ongoing production processing.
Although data is sliced and distributed to numerous nodes of a cluster, a database table will always appear as a single logical unit to an application. Clustrix uses a simple SQL interface and no special application programming is necessary to access data distributed throughout a Xpand cluster.
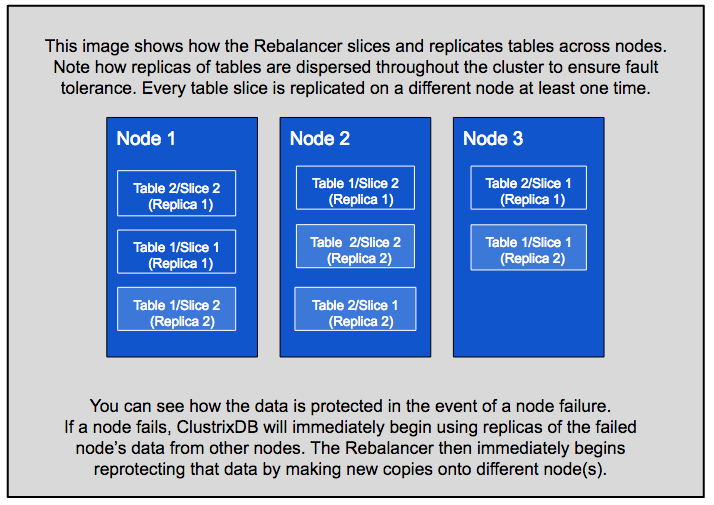
For additional information, see "MariaDB Xpand Rebalancer".
Sierra Database Engine
Sierra is the SQL engine of Xpand that handles query planning and execution. It has been specifically designed to work in a distributed, shared nothing environment while facilitating access to distributed data as efficiently as possible. The Sierra Database Engine consists of two parts:
The Sierra Parallel Planner determines an optimal execution plan for a SQL statement.
The Sierra Distributed Execution Engine executes query fragments based on those plans and provides intermediate results.
Sierra Parallel Planner
Sierra Parallel Planner is a cost-based optimizer that uses probability statistics, data volumes, indices, and overhead of query operators to determine the most efficient query plan. A key differentiating feature of Xpand's planner is that it determines this plan while taking into account the distribution of the data across the cluster.
Sierra Distributed Execution Engine
Once the Sierra Planner determines the optimal plan for a query, it is compiled into machine-executable query fragments. Those compiled query fragments are then executed across different nodes in the cluster, providing efficiency and increased concurrency of execution. Once execution on each node is complete, the results are returned to the GTM node, which then combines the partial results and returns the final result set to the user.
Selected aggregate processing is also distributed. When advantageous, computations are fragmented and distributed the same as other queries except that partial aggregates (SUM, MAX, MIN, AVG, etc.) are calculated on each node's distributed data first. The intermediate results are then coalesced by the GTM to produce the final result.
Let's look one final time at the query distribution in Xpand - this time with the distributed data in place.

Conclusion
Xpand uses automatic data distribution, a sophisticated query planner, and a distributed execution model to provide scalability and concurrency in an ACID compliant RDBMS. To accomplish this, Xpand utilizes many of the same techniques used by other Massively Parallel Processing (MPP) databases: It uses Paxos for distributed transaction resolution, and Multi-Version Concurrency Control (MVCC) to prevent transaction conflicts. With the aid of the major components outlined above, Xpand provides this distributed execution with a simple SQL interface while also providing scalability, efficiency, and fault tolerance.