Parallel Query Evaluation for MariaDB Xpand
This page is part of MariaDB's Documentation.
The parent of this page is: Evaluation Model for MariaDB Xpand
Topics on this page:
Overview
MariaDB Xpand features parallel query evaluation:
Xpand provides linear scalability of reads and writes by ensuring that single row selects and inserts are executed with only 0 or 1 hop
Xpand provides excellent scalability of joins by minimizing data transfer between nodes
Xpand compiles queries into fragments and uses a massively parallel processing (MPP) strategy to execute different fragments on different nodes concurrently
Compatibility
Information provided here applies to:
MariaDB Xpand 5.3
MariaDB Xpand 6.0
MariaDB Xpand 6.1
Parallelism
Xpand executes queries in parallel using several different kinds of parallelism.
Xpand achieves very efficient parallel query evaluation for multiple reasons:
While data is distributed among all nodes, all nodes know the location of every slice, so any node can forward an operation to any slice's node with only 0 or 1 hop.
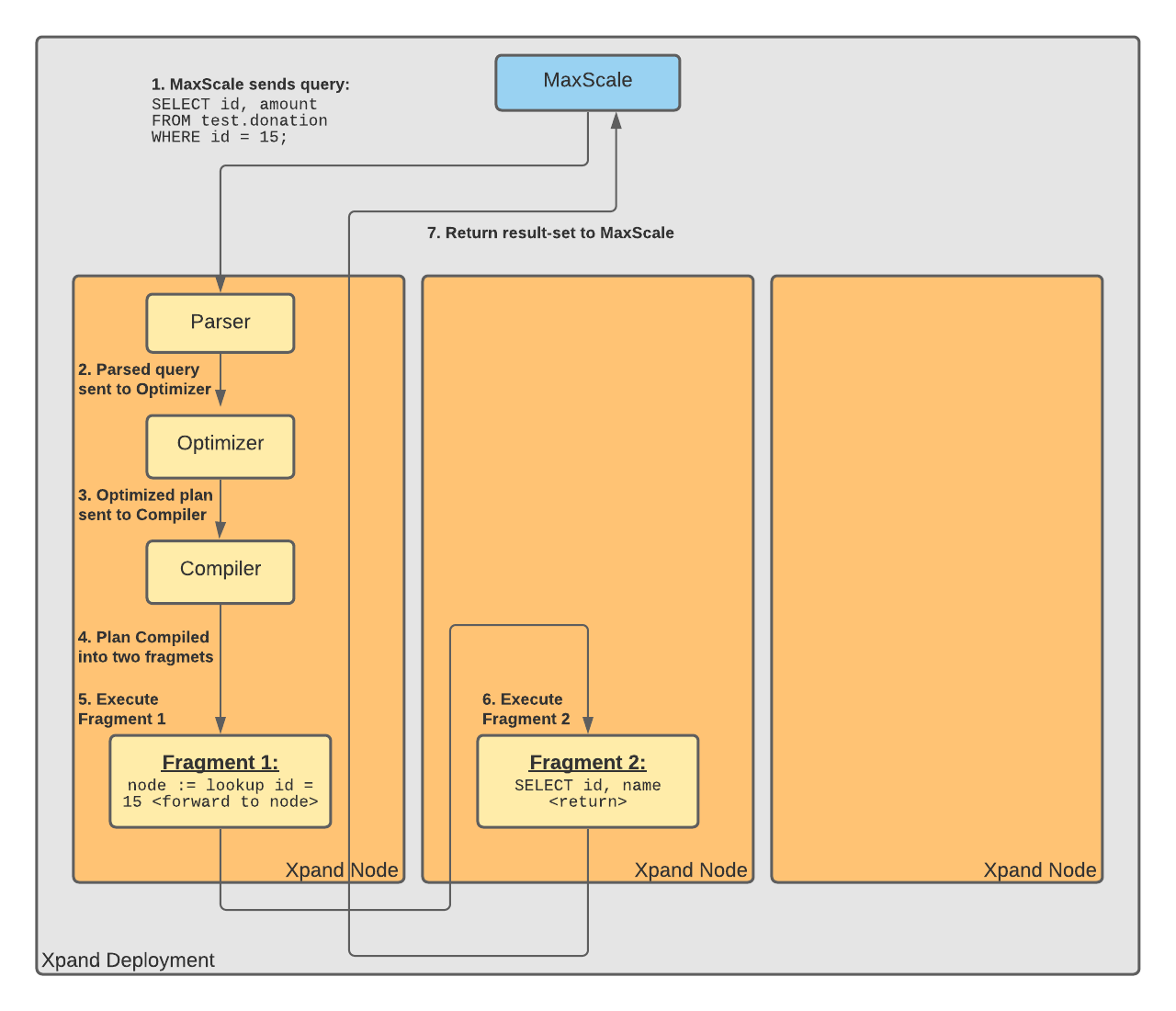
The query optimizer compiles a query into fragments that are analogous to a collection of functions
The first function looks up where the value resides
The second function reads the correct value from the correct slice
The following graphic shows how this works for a simple SELECT statement:
Concurrent Parallelism
Concurrent Parallelism is when two entities can perform the exact same task in parallel.
Xpand uses concurrent parallelism to execute the same fragment of a query on different slices in parallel. A different node or CPU core operates on each slice.
For example, if a query reads every slice for a table, Xpand can read every ranking replica for every slice in parallel.
Pipeline Parallelism
Pipeline Parallelism is when two entities can perform different stages of a task in parallel.
Xpand uses pipeline parallelism to execute different fragments of a query on different slices in parallel. A different node or CPU core executes each fragment.
For example, if a query joins two tables, Xpand optimizes the operation by creating a pipeline. While Xpand is reading the next row from the first table, another node or CPU core will be joining the previous row in the first table with the corresponding row in the second table in parallel.
Massively Parallel Processing (MPP)
Xpand uses massively parallel processing (MPP) strategies. Massively parallel processing (MPP) is a programming strategy that allows an operation to be coordinated among multiple CPU cores on one or more hosts. The operation is split into multiple distinct tasks, and multiple CPU cores handle each task in parallel.
Xpand uses MPP strategies to coordinate query execution between nodes. Different fragments of a query can be executed on different nodes. When a query is executed on a node, the Global Transaction Manager (GTM) on the same node manages the concurrency of the query by communicating with other nodes that are executing fragments of the query. On those nodes, the Local Transaction Manager (LTM) on each node manages the local part of the query.
Xpand also uses MPP strategies to minimize data transmission between nodes for most queries. When the query optimizer compiles a query into fragments, it creates two fragments for each database lookup. The first fragment looks up the node that contains the slice with the specified value, and the second fragment reads the value from the correct slice on that node. This method allows very complicated queries to scale with minimal network overhead:
A simple read-only query will always read the slice from the ranking replica. Every simple read-only query requires 0 or 1 hop.
A simple write query will always update every replica of the slice. Every simple write query requires a maximum number of hops equal to the number of replicas (by default, 2) plus 1.
A join query will always read the joined slice from the ranking replica. As the number of rows in a join increases, the number of hops per row does not increase. Each row in a join only requires a maximum of 3 hops.
Xpand also uses MPP strategies to optimize aggregate operations by performing as much of the aggregation as possible in a distributed manner. Each node performs a partial aggregation on its local data. At the end of the operation, the original node combines all of the data and performs the final aggregation.
Query Evaluation Procedure
In the Xpand Topology, the application connects to MariaDB MaxScale, which routes the connection to a MariaDB Xpand node:
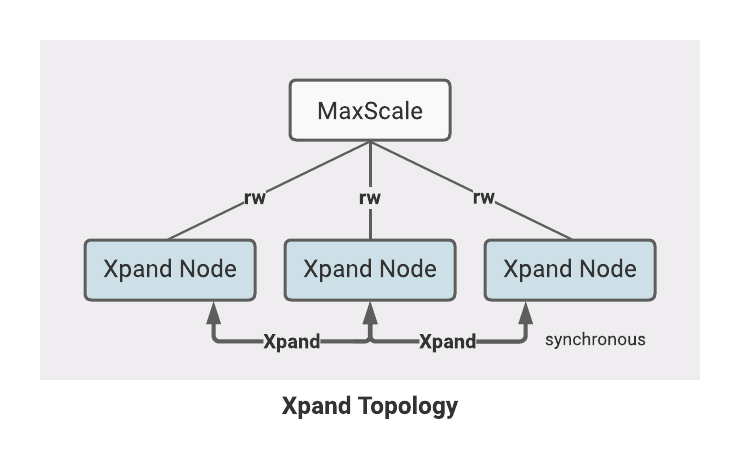
MaxScale uses the Xpand Monitor (
xpandmon) to determine which Xpand nodes are healthy and able to receive connectionsMaxScale receives a new connection from the user or application.
MaxScale uses the
ReadConnRouteRouter to select a specific Xpand node to receive the connectionMaxScale receives an SQL query over the connection
MaxScale routes the query to the Xpand node associated with the connection
Xpand associates the query with a session on the Xpand node that receives the query from MaxScale. This node acts as the Global Transaction Manager (GTM) for the query.
Xpand parses the query, then sends it through the query optimizer and planner, choosing the optimal execution plan based on internal statistics.
Xpand compiles the plan, breaking it into smaller query fragments, then runs code optimizations.
Xpand runs the compiled query fragments in a distributed way across the Xpand nodes.
The Xpand node that received the query collects the responses from the other nodes and returns the result-set.
MaxScale receives the result-set and passes it back to the user or application.
Scaling Queries
MariaDB Xpand uses strategies to optimize certain types of queries. For details on some of these optimizations, choose a type of query: