
MariaDB MaxScale は以下のような特長を持つデータベースproxyですが,
- Read/Write Splitter
- SQLファイアウォール
- データマスキング
- 自動フェイルオーバー
反面,MaxScale ノード/インスタンスがダウンした場合に単一障害点(SPOF)になりえます。
そこで今回は MaxScale を2ノード構成とし,その上位に Keepalived を配した構成における MaxScale のフェイルオーバーについて解説致します。
テスト環境
- CentOS 7.6.1810
- MaxScale 2.3.4 GA
- Keepalived 1.3.5
Keepalived とは
Keepalived は高可用性(HA)/ロードバランシングのためのルーティングツールです。今回は MaxScale を実行している2台のサーバー間で IPフェイルオーバーを設定します。アクティブ MaxScale に障害が発生した場合、スタンバイ MaxScale に仮想IP(VIP)をフェイルオーバーします。
下図にアーキテクチャを示します。各 MaxScale ノードでは MaxScale と Keepalived を実行し,クライアント/アプリケーションは Keepalived が管理する仮想IP(VIP)に接続します。
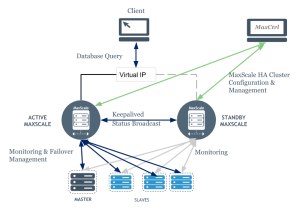
各 Keepalived(MaxScale)ノードは常にステータスをブロードキャストし,互いに通信します。片方のノードが他ノードより高い優先順位でステータスメッセージを受信しない場合,そのノードはVIPを要求しマスターになります。
現 MASTERノードが停止した場合,他方のノードは新MASTERとなり,VIPへのトラフィックは新MASTERに向けられ,オリジナルのMASTERノードへの接続は切断されます。再びオリジナルMASTERがオンラインになった場合,再度VIPを要求し、バックアップノードとの接続を切断します。
MaxScale は Keepalived のステータスには関知せず,シングルノード構成と場合と同様にバックエンドDBサーバを監視,クライアント接続を待機します。クライアントはVIPを介して接続しているため,MaxScaleとバックエンドDB間の接続は実IPを使用し,VIPの影響を受けません。
Keepalived の設定
MaxScale は Keepalived のための特殊な設定を必要としませんが,双方のノードで実行されている必要があり,MaxScale の設定は同様に設定する必要があります。MaxScale の service 設定では,クライアントがどちらの MaxScale ノードに接続したかを明確にするために version_string をノード毎に異なる値に設定することを推奨いたします。
プライマリ MaxScale ノードの R/Wスプリッター serviceの設定例
[Read-Write-Split-Service] type=service router=readwritesplit version_string=PrimaryMaxScale
Keepalived は双方のノードで priority を異なる値に設定する必要があります。プライマリ・ノードでは /etc/keepalived/keepalived.conf を次のように設定します(priority 150)。
vrrp_instance VI_1 {
state MASTER
interface eth1
virtual_router_id 51
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass mypass
}
virtual_ipaddress {
192.168.2.230
}
}
ここで,
- state : 双方のノードで MASTER
- virtual_router_id と auth_pass は同一
- interface : 使用されるネットワークインタフェース
- priority : どちらがMASTERになるべきかを決定するための優先度。ここではプライマリ・ノードを150にする
- advert_int : 他のKeepalived ノードに自分の存在を”アドバタイズ”する時間間隔。ここでは1秒
- virtual_ipaddress(VIP) は Keepalived ノードが利用しようとする仮想IPアドレス。VIPが同一LAN内にあり、LAN内の他ホストが利用していないIPアドレスである必要があります。
セカンダリ・ノード用の keepalived.conf の例を以下に示します(priority 100)。
vrrp_instance VI_1 {
state MASTER
interface eth1
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass mypass
}
virtual_ipaddress {
192.168.2.230
}
}
MaxScale のヘルスチェック(死活監視)
MaxScale が Keepalived MASTERノードで稼働中であることを確認するには,ヘルスチェック・スクリプトを定期的に実行する必要があります。ヘルスチェック・スクリプトがエラーを返すと,ステータス・ブロードキャストを停止し,VIPを放棄します。
これにより他ノードが MASTERステータスを取得し,VIPを割り当てることができます。
例えばプライマリ・ノードでは次のように設定します。
参考: Keepalived Check and Notify Scripts
vrrp_script chk_myscript {
script "/home/vagrant/is_maxscale_running.sh"
interval 5 # check every 5 seconds
fall 2 # require 2 failures for KO
rise 2 # require 2 successes for OK
}
vrrp_instance VI_1 {
state MASTER
interface eth1
virtual_router_id 51
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass mypass
}
virtual_ipaddress {
192.168.2.230
}
track_script {
chk_myscript
}
}
is_maxscale_running.sh の例:
#!/bin/bash
fileName="maxctrl_output.txt"
rm $fileName
timeout 5s maxctrl list servers > $fileName
to_result=$?
if [ $to_result -ge 1 ]
then
echo Timed out or error, timeout returned $to_result
exit 3
else
echo maxctrl success, rval is $to_result
echo Checking maxctrl output sanity
grep1=$(grep server1 $fileName)
grep2=$(grep server2 $fileName)
if [ "$grep1" ] && [ "$grep2" ]
then
echo All is fine
exit 0
else
echo Something is wrong
exit 3
fi
fi
MaxScale active/passive設定
MaxScale を複数稼働させていて,なおかつ MariaDB Monitor(mariadbmon) の auto_failover / auto_rejoin を有効にしている場合,MaxScale 間でMariaDB Monitor が競合しますので,BACKUPノードでは auto_failover / auto_rejoin を無効にする必要があり,グローバル設定の passive パラメータで制御することができます。
MASTER(Active) ノードでは,
maxctrl alter maxscale passive false
により,passive=false (active) に設定,反対に BACKUP(Standby) ノードでは,
maxctrl alter maxscale passive true
により,passive=true に設定します。
passive=true になると,auto_failover=false / auto_rejoin=false となり,自動 failover / rejoin を行いません。
MaxScale のフェイルオーバーテスト
プライマリ・ノードを reboot ,再起動中に MaxScale がセカンダリに自動 フェイルオーバーするかテストしてみます。
セカンダリ・ノードの /var/log/messages:
Mar 13 20:37:43 mxs2 Keepalived_vrrp[8390]: VRRP_Instance(VI_1) Transition to MASTER STATE Mar 13 20:37:44 mxs2 Keepalived_vrrp[8390]: VRRP_Instance(VI_1) Entering MASTER STATE Mar 13 20:37:44 mxs2 Keepalived_vrrp[8390]: VRRP_Instance(VI_1) setting protocol VIPs. Mar 13 20:37:44 mxs2 Keepalived_vrrp[8390]: Sending gratuitous ARP on eth1 for 192.168.2.230 Mar 13 20:37:44 mxs2 Keepalived_vrrp[8390]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs on eth1 for 192.168.2.230 Mar 13 20:37:44 mxs2 Keepalived_vrrp[8390]: Sending gratuitous ARP on eth1 for 192.168.2.230 Mar 13 20:37:44 mxs2 Keepalived_vrrp[8390]: Sending gratuitous ARP on eth1 for 192.168.2.230 Mar 13 20:37:44 mxs2 Keepalived_vrrp[8390]: Sending gratuitous ARP on eth1 for 192.168.2.230 Mar 13 20:37:44 mxs2 Keepalived_vrrp[8390]: Sending gratuitous ARP on eth1 for 192.168.2.230 Mar 13 20:37:49 mxs2 Keepalived_vrrp[8390]: Sending gratuitous ARP on eth1 for 192.168.2.230 Mar 13 20:37:49 mxs2 Keepalived_vrrp[8390]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs on eth1 for 192.168.2.230 Mar 13 20:37:49 mxs2 Keepalived_vrrp[8390]: Sending gratuitous ARP on eth1 for 192.168.2.230 Mar 13 20:37:49 mxs2 Keepalived_vrrp[8390]: Sending gratuitous ARP on eth1 for 192.168.2.230 Mar 13 20:37:49 mxs2 Keepalived_vrrp[8390]: Sending gratuitous ARP on eth1 for 192.168.2.230 Mar 13 20:37:49 mxs2 Keepalived_vrrp[8390]: Sending gratuitous ARP on eth1 for 192.168.2.230 Mar 13 20:38:01 mxs2 Keepalived_vrrp[8390]: VRRP_Instance(VI_1) Received advert with higher priority 150, ours 100 Mar 13 20:38:01 mxs2 Keepalived_vrrp[8390]: VRRP_Instance(VI_1) Entering BACKUP STATE Mar 13 20:38:01 mxs2 Keepalived_vrrp[8390]: VRRP_Instance(VI_1) removing protocol VIPs.
プライマリ・ノードがシャットダウンされた直後にセカンダリ・ノードが MASTER STATE に移行し,プライマリ・ノードの reboot が完了すると,セカンダリ・ノードが再び BACKUP STATE になっていることが確認できます。
まとめ
今回は SPOF を回避するために MaxScale を複数稼働させ,Keepalived を用いて片方の MaxScale がダウンした場合に高速自動フェイルオーバーする MaxScale の高可用構成について解説いたしました。DNS設定などでフェイルオーバーするロードバランサーなどと比較してより高速に切り替わることが確認できました。
参考 Knowledge Base ページ: MaxScale 2.3 Failover with Keepalived and MaxCtrl