
The latest release of MariaDB SkySQL comes packed with exciting new features that streamlines and boosts the productivity of DBAs, data engineers, and application developers. Start with a single node or scale out as demand grows. When the need arises, run advanced analytics and machine learning workloads on production data without requiring the data to move to a separate system.
This blog walks through the new SkySQL release and its features. Note that some of the features are still in tech preview.
Productivity and cost savings for DBAs
The primary goal of the cloud is to reduce costs and expand the user base for applications and data. While this is undoubtedly true for CapEx costs, as cloud environments enable the quick and cost-effective deployment of servers, many have discovered that OpEx can become an issue as they begin using cloud services for various activities. Whether for development, testing, or production, it is often difficult and painful to determine the appropriate amount of resources required to meet demand. Failure to plan ahead could result in significant financial losses if demand is not met, while over-provisioning could result in wasted resources and unnecessary expenses. This is particularly true for transaction databases that require predictable performance, latency, and response times to meet the needs of demanding applications. Additionally, most organizations have business use cases where workloads experience unexpected or periodic spikes in demand that can significantly exceed predicted workload forecasts.
To alleviate the challenges associated with resource planning, SkySQL introduced two exciting features. As a DBA, use manual scale operations to add more nodes, CPU/memory, or storage, or rely on the intelligent predictive algorithm built into SkySQL to determine the scaling requirements and automatically scale the necessary resources to meet demand. Furthermore, this release also supports ARM-based instances, which provides 25% better performance and are less expensive than comparable Intel processors.

Fig: Self-service and autonomous scale support
Please refer to our documentation for more information: https://mariadb.com/docs/skysql-new-release-dbaas/service-management/nr-autonomous/
New Terraform Provider
Nowadays, DevOps teams are the main users of cloud resources and they prefer using an “Infrastructure as Code” framework, such as Terraform, to streamline their workflows. By integrating their CI/CD pipelines with their application deployment code, it becomes simpler for DevOps to fix any issues from testing to production environments while increasing productivity and reducing code variability.
New in this release, DevOps engineers can effortlessly deploy any of the supported SkySQL database configurations using the SkySQL Terraform provider. Consistency in the deployment scripts facilitates meeting the requirements of data processing, whether it’s for small test databases or large-scale analytical processing applications. We invite you to try the SkySQL Terraform provider from the link below.
Try the SkySQL Terraform provider: https://registry.terraform.io/providers/mariadb-corporation/skysql/latest
Corporate chargeback and ROI calculation
Opening up cloud resource access to various departments and individual developers increases productivity, but for many large corporations, it also creates unnecessary wastage in cost management. Cloud resources deployed in Dev/Test and User Testing environments are often left running after their intended use, resulting in significant financial losses for organizations without proper accounting.
SkySQL provides a solution to this problem by making it easier to create teams that can deploy databases and trace usage to a particular department for chargeback. For advanced scenarios, organizations can use the REST API to obtain detailed usage and billing metrics, allowing for internal chargeback or cost/ROI calculation and making it easier to figure out charges.
Developer Agility
MariaDB databases can store and process JSON documents using the SQL programming language. With SkySQL, we’ve added the ability to seamlessly connect an existing MongoDB applications to SkySQL and gradually transition a MongoDB application to MariaDB.
Fig: Easily deploy NoSQL support
In addition, SkySQL introduces a new and user-friendly Query Editor, making it easier to load and execute queries on your SkySQL databases without the need for external tools or command line interfaces.
Fig: Built in SQL Query Editor
Serverless Analytics powered by Apache Spark: Zero-ETL required and pay-for-use
Many organizations operate hundreds, or even thousands, of databases to support a variety of applications – from simple shopping carts to complex, internet-scale IoT applications and decision support systems. Often, these applications require combining data from multiple sources, including simple databases, traditional data warehouses, and modern data lakes. One approach to this challenge is to use database services from hyperscalers, which involves moving data between different databases or storage systems using complex data pipelines and message buses, leading to prohibitively high costs and complexity.
In the new release of SkySQL, we added Serverless Analytics that enables Apache Spark to be deployed with one click and at zero initial cost. This feature enables in-place, zero-ETL required analytics, allowing adhoc or advanced analytics on production data instantly. No need for complex data pipelines or transformations. Best of all, get started without paying a single cent and only pay for what is used.
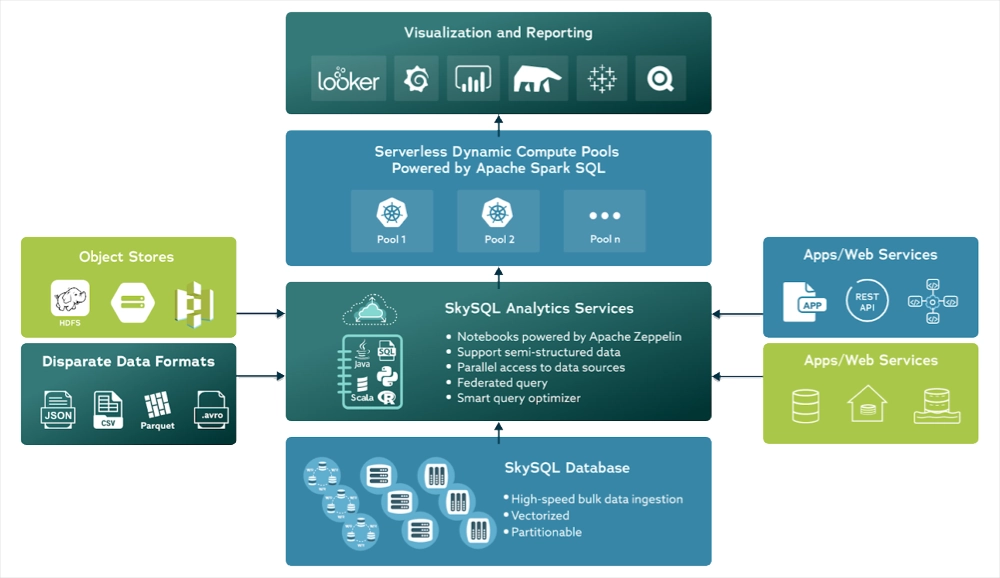
In addition, SkySQL also incorporates a built-in data science Notebook that utilizes Apache Zeppelin. This enables data engineers and analysts to create notebooks with ease, harnessing the power of Spark through a user-friendly graphical interface. The Notebook is pre-loaded with various examples that demonstrate ways to run analytics on data stored in SkySQL. It can also be used for discovering schema, running queries on data stored in S3, and federating queries to join data in SkySQL and S3, thus facilitating corporate big data use cases.