
More often than not, replicas are deployed for high availability and/or read scaling. If the primary fails, one of the replicas is promoted to primary. If there are lots of reads, and that’s almost always the case, replicas are added to scale out. Ideally, writes are routed to the primary and reads are load balanced across the replicas. It’s the most efficient way to utilize the resources available.
RDS, Azure Database and Cloud SQL all provide you with individual endpoints for database instances, one for the primary and one for each replica. If you want to load balance reads, you have to create multiple connections (one for each replica) and do it yourself. If you want to execute writes on the primary and reads on the replicas (i.e., read/write splitting), you have to create an additional connection to the primary and do it yourself.
Not fun. Not cool.
With MaxScale, an advanced database proxy for MariaDB Enterprise Server, you don’t have to worry about it. MaxScale performs read load balancing and read/write splitting for you – it’s what we call transparent query routing. Developers shouldn’t have to be concerned about the physical infrastructure (i.e., database topology). Why should they? Maybe there is one replica, maybe there are five. Maybe the DBAs added a replica last night, maybe they removed two. It shouldn’t matter, and applications shouldn’t have to account for it.
That’s the great thing about MaxScale. It abstracts away the underlying database infrastructure and deployment topology. Maybe it’s a standalone database. Maybe it’s a replicated database. Maybe it’s a clustered database. Who cares? Especially in the cloud.
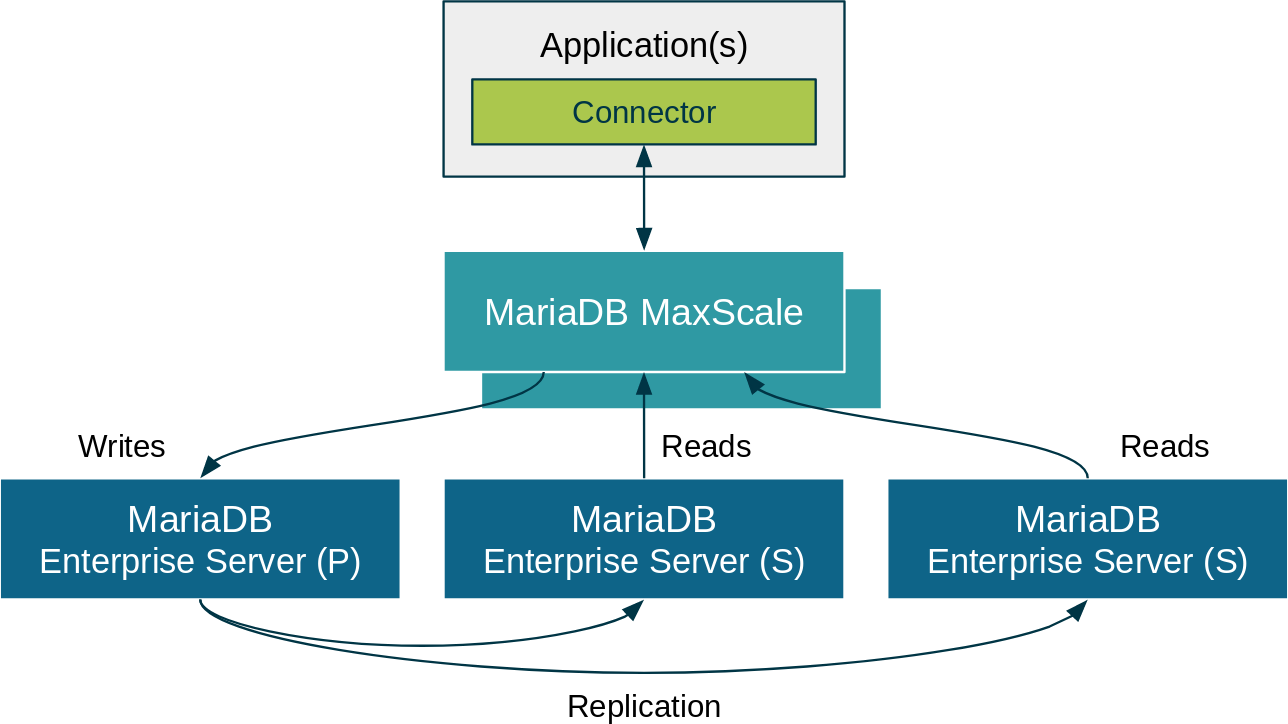
So, why is it you can take advantage of transparent query routing on premises, but not in the cloud? Because RDS, Azure Database and Google Cloud SQL don’t have MaxScale. If only there was a DBaaS with MaxScale and transparent query routing. If only we could soar higher with the ultimate MariaDB cloud. Hold on, hello there SkySQL!
Yes, we’ve brought the power of MaxScale to SkySQL.
After you create a replicated database, you’re provided a hostname and two ports, one read and one read/write. You only need the read/write port as it does read load balancing too. But, if you have read-only applications (e.g., BI/reporting), the read port may come in handy. Easy peasy.

You might be asking yourself, did Shane just share the hostname and port of his database?
Why yes, yes I did. By default, SkySQL databases are not accessible. You have to whitelist the IP addresses (or ranges) of any clients and application servers requiring access. And the only IP address I’ve whitelisted is the one for my laptop at home. Good luck. 😉
Back to the topic at hand, you’ll see the two ports: 5001 for read/write splitting (writes to primary, reads load balanced across replicas) and 5002 for read-only load balancing. My database has two replicas, but the applications connecting to it don’t have to be concerned about it. I could add two more replicas tomorrow, and no application changes would be required to take advantage of them. MaxScale would simply, and automatically, begin routing reads to them.
And if the primary fails, no big deal. MaxScale will automatically promote a replica and begin routing writes to it (and load balancing reads across the remaining replicas). If you’ve ever suffered from the unpredictable failover time of RDS, you know why. RDS failover is based on DNS propagation so you don’t have to change the endpoint hostname. It’s almost transparent, but it takes time. With MaxScale, on the other hand, it’s immediate – no DNS propagation required.
But, I don’t want to stray too far off topic. I have something else in mind planned for HA. Stay tuned.