
A hurricane in New York, a wildfire in California, a flood in Germany or a record heatwave in the UK – whether its mother earth showing off or something more mundane, are you ready for it? There are several different ways to ensure both availability and recoverability for cloud applications, which I review in detail in this article in Disaster Recovery Journal, Creating Cloud Applications that Survive the Big One. In this blog, I will drill down into the data layer and discuss different levels of availability and recoverability that MariaDB’s distributed SQL database, Xpand, provides.
First, remember that there is a cost to everything. Ensuring availability requires redundancy. Ensuring recoverability requires sending data over a geographic distance. Redundancy, transmission, and storage will cost in terms of both money and performance. ALL applications that perform some important service must tolerate some failure. At the basic level, a machine outage should not bring down the entire service. However, more mission-critical applications require even more stringent fault tolerance in case of multiple simultaneous failures or outages that affect a wider area. In the following sections, we examine various fault tolerance levels built into distributed SQL databases such as Xpand.
High Availability Level 1: Fault Tolerance
Distributed SQL databases are architecturally both scalable and available. To deploy MariaDB Xpand, you need at least three nodes. Xpand automatically stores and maintains data redundantly, ensuring multiple copies of each slice are stored, concurrently updated and synchronously committed. If a node is lost, no data is lost. Given that there are multiple redundant copies of the same data, every update will simultaneously update all copies. That way it is guaranteed that regardless of which node serves up data, it will always be consistent throughout the cluster. This is the basic level of high availability built into distributed SQL databases like Xpand.
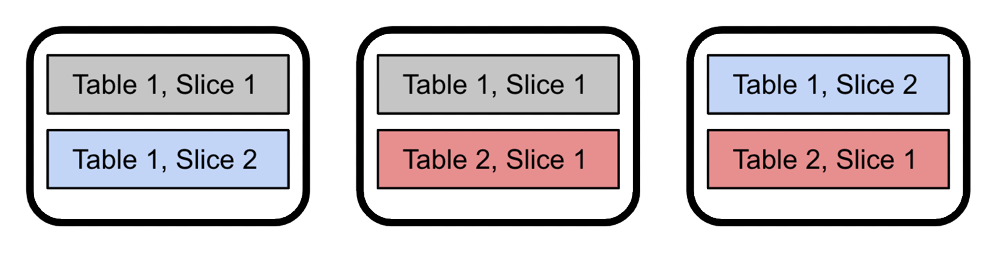
High Availability Level 2: Zone Loss
Individual nodes do go down from time to time due to hardware issues or minor operating glitches. However, at times there is an issue in the entire system. In 2021, there was an issue with all of AWS’s us-east-1, a datacenter in Virginia. It was the storage layer network of the entire availability zone (AZ). Many internet services went down during this event. It was not just a single node that was lost but almost any node using EBS for storage in that whole AZ.
To survive such a large scale failure scenario, Xpand can ensure availability across availability zones, that way a zone failure will not take down the entire operation. When a row is inserted into Xpand it is assigned to a “slice” and there is always at least one replica of the slice. That slice lives on one node, the replica of the slice lives on another node. When configured for multiple availability zones the replica never lives in the same AZ as the primary copy of the slice. If a whole AZ goes down, the database lives on. The same concept applies in self-hosted databases with multiple datacenters or racks. This zone awareness is the next level of availability Xpand provides.
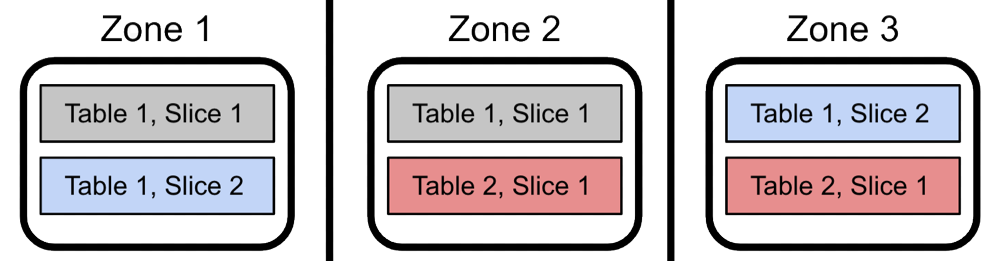
High Availability Level 3: Multizone
Losing a node or availability zone is rare. Losing two copies of the data at the same time is even more rare. With Xpand, it can be configured to handle two simultaneous failures instead of one. Meaning it can provide two replicas of each slice even in two additional AZs. While a configuration could support more replicas, not every region has more than 3 AZs. Also, there is a cost to making more copies of the data and coordinating writes. Multiple AZ/node fault tolerance is an additional level of availability from Xpand.
High availability is achieved through simple policy decisions. Xpand will handle the slicing and data placement to ensure resilience across node and zone failures based on the max failures setting. Data is concurrently updated to speed performance, yet commits are synchronous, ensuring updates are applied to all or none of the copies. A failure can transparently fail over to another node that contains the data with no fear of data loss. With the use of a smart load balancer to redistribute traffic to surviving nodes, failover is automatic and requires no special application or operations handling.

Disaster recovery Level 1: Backups
Not every disaster is natural. Some of the biggest ones are man-made. Remember, a configuration error took Facebook down. If an application changes data incorrectly, this is not a database system issue. In order to restore the correct data, good old-fashioned backups are required.
Xpand goes much further than that with parallel online backups. It can keep the whole system performing efficiently while a backup is taken and kept far away from the production system. The backup maintains transactional data integrity. Backup and restore is the basic level of disaster recovery.
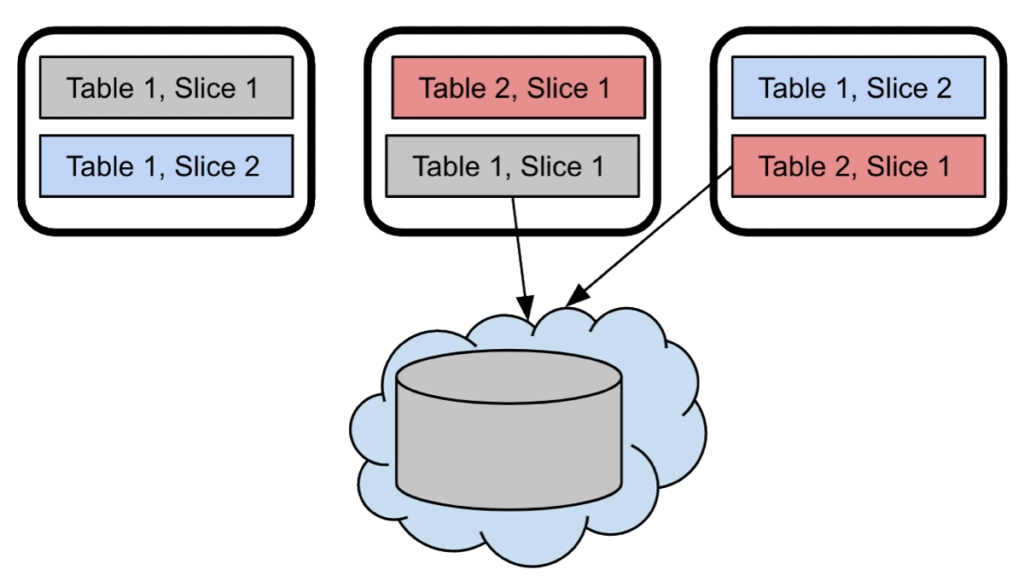
Disaster Recovery Level 2: Dual Region Replication
Bad stuff happens. Bomb cyclones kill the power in late fall and early winter. Temperatures can drop 50 degrees in a day! It can even freeze in Savannah, where I live! It is possible to lose an entire region, though Amazon claims this has never happened. It has happened on other cloud services however. Global companies must deal with a variety of providers and disaster situations often times all at once.
Xpand provides scalable parallel replication. All the data can be copied from one cluster to another in real-time. Parallel replication is asynchronous to avoid latency issues but maintains transactional integrity. If an issue takes down a region, everything can automatically fail over to a second region. Xpand can harness abundant compute and network bandwidth of the entire source and target clusters, avoiding bottlenecks other databases incur with scale-up systems and serial replication.
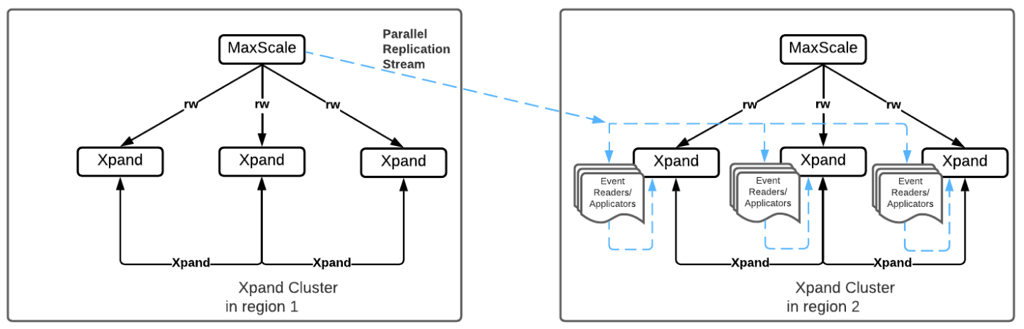
Disaster Recovery Level 3: Multiregion Replication
In general, it is best to keep data and code near each other and the end-user. So even if your data is in San Jose, it makes more sense to have a second region in Portland than, say Virginia. However, if something really bad happens on one coast, then it may make sense to fail over to Ohio or some other region. Xpand can replicate in parallel to multiple regions while maintaining transactional integrity. If your application needs to scale, replicating to multiple geographies also needs to scale, making it even more important to be able to utilize the entire compute and network bandwidth available on source and target clusters to replicate data faster, resulting in low replication lag.
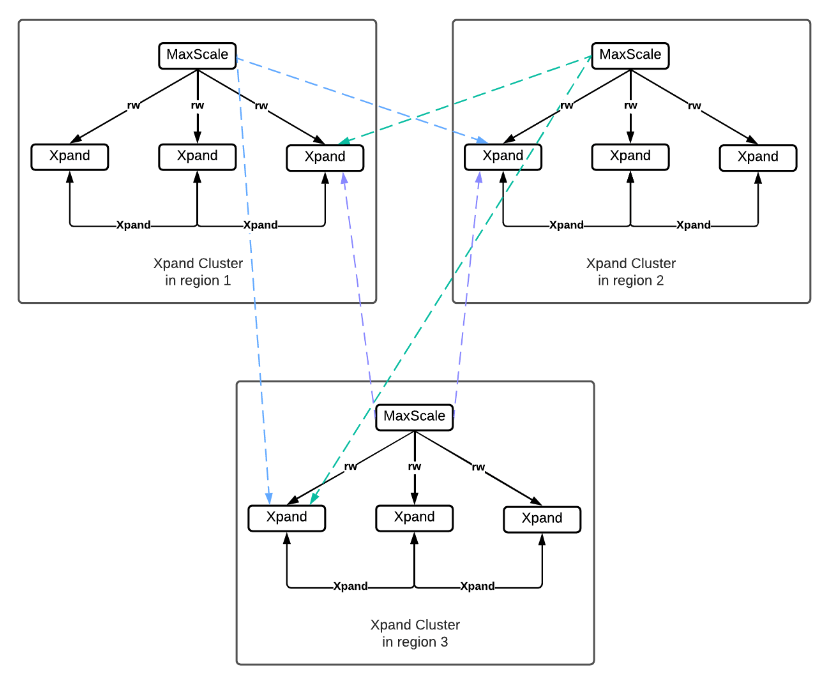
Edge Cases
It is possible to have two active regional clusters that replicate bidirectionally so long as data does not conflict. It can be useful to have geographically local clusters while ensuring redundancy. Bidirectional replication is, however, an edge case that should only be used if absolutely required and changes are unable to conflict.
Ultimately Xpand is the secret sauce to ensure a critical cloud application survives “The Big One” no matter what it is. By combining zone aware high availability, cross regional replication and parallel online backups, Xpand is able to handle multiple faults and recover quickly in the event the unthinkable happens. Not all of this is cheap, copying data across regions is how cloud service providers make real money. However, for the applications that really needs it, it is essential. Pick the right combination that works for your data, application and budget!
Start your journey on Xpand
If you need a high performance, elastically scalable database or just want to kick the tires of a distributed SQL database here is a place to start:
- Check out the Xpand documentation
- Ask questions on the MariaDB Community Slack
- Contact us