
This blog post begins a three part series to create and customize your own asynchronous MariaDB replication client. With the release of MariaDB Community Server 10.8.1, the mariadb-binlog command line utility now supports both 1) filtering events by GTID ranges through –start-position and –stop-position, and 2) validating a binary log’s ordering of GTIDs through –gtid-strict-mode. This blog post showcases these new features to create a basic replication client using the mariadb-binlog and mariadb command-line tools. Part 2 of this series will extend this replication client with basic parallelization using four new event filtering command-line options added in MariaDB Community Server 10.9.1. Part 3 will be released pending MDEV-26982, which will provide scripting support to monitor the progress of our replication client.
Background on GTIDs
A large amount has been written that highlights the value of MariaDB’s Global Transaction IDentifiers (GTID), but to quickly summarize a few main ideas:
- Using GTIDs to represent replication state allows for explicit crash safety and easy server topology changes.
- Replay consistency can be validated by ensuring that sequence numbers are monotonically increasing within a given domain.
- Event execution can be parallelized at the domain-level, as independent data streams can be tagged with different domain ids.
To provide a quick background on GTIDs, a GTID uniquely identifies a transaction using three positive integers: a domain id, a server id, and a sequence number (formatted as <domain_id>-<server_id>-<seq_no>). The domain id groups together a series of transactions into a data stream. The server id identifies the server that generated the transaction. The sequence number provides a unique identifier for the transaction in the data stream; and if –gtid-strict-mode is enabled, a relative position of the GTIDs in the stream. A data stream can then be represented using a series of GTIDs with the same domain id, where the GTIDs of later transactions have larger sequence numbers. The last transaction applied within a data stream can be identified by the last GTID applied. Following this logic, the state of a MariaDB server can be represented by a list of GTIDs; each with a unique domain id that represents that latest transaction applied in its data stream.
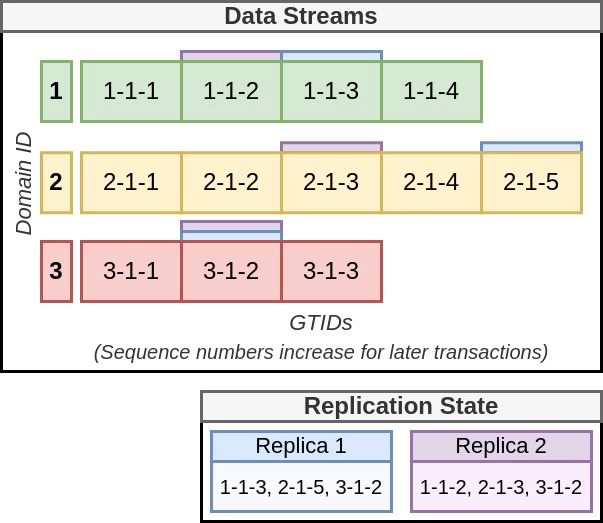
Figure 1: Using GTIDs to represent replication state with 2 replicas
To illustrate, figure 1 shows how GTIDs can be used to consistently replicate transactions and maintain replication state. Specifically, using three data streams, we show how two out-of-date replicas can provide their current replication state, expressed as a GTID list, to a primary server to receive and apply only their missing transactions. The first data stream is colored green and has domain id 1. The second data stream is colored yellow and identified by domain id 2. The third data stream is colored red and identified by domain id 3. Each data stream originated from the same server (server id 1), and begins with sequence number 1 and increases sequentially with each transaction. The data streams from domain 1,2, and 3 are composed of four transactions, five transactions, and three transactions, respectively. This results in the latest GTID state of all data streams represented as the list 1-1-4,2-1-5,3-1-3 because it represents the last transaction available in each domain. In this example, however, the replicas are behind, i.e. they have not yet applied the latest available transactions. The replication state of the first replica server, replica 1 (the blue box at the bottom right of the figure), is 1-1-3,2-1-5,3-1-2 and has blue tabs above the GTID boxes in the streams to represent the server’s last transactions applied. The replication state of replica 2 (colored purple) is 1-1-2,2-1-3,3-1-2 and has purple tabs above the GTID boxes in the streams to represent the server’s last transactions applied. It can be seen that replica 1 is missing one event from both domains 1 and 3, but is up-to-date for domain 2. Replica 2 is missing two events from both domains 1 and 2, and one event from domain 3. Then, to efficiently receive these missing transactions, the replicas need only to notify the primary server of their current replication state. This allows the primary to only provide unseen events. In this example, the primary server would provide the events for GTIDs 1-1-4 and 3-1-3 to replica 1, and 1-1-3,1-1-4,2-1-4,2-1-5, and 3-1-3 to replica 2.
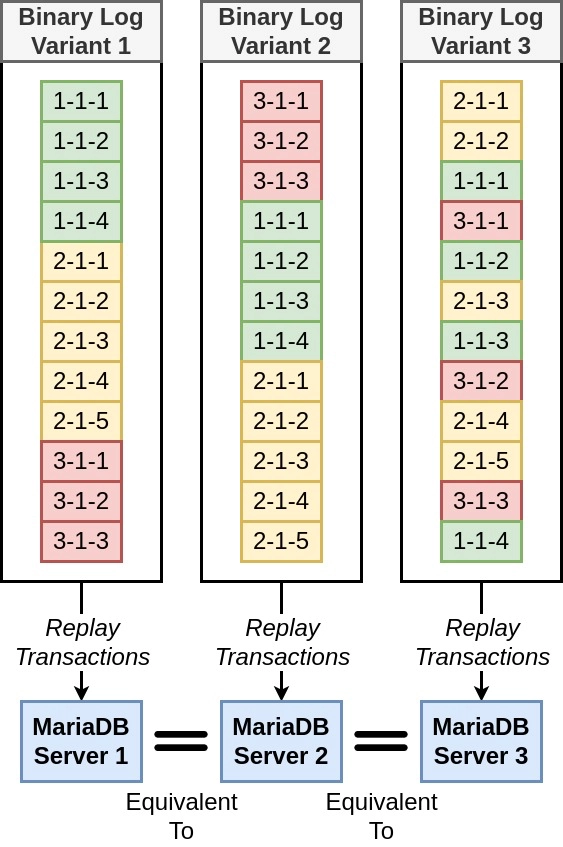
Figure 2: As long as different binary logs contain the same events and the events within a domain are ordered monotonically, their replay will lead to MariaDB servers with equivalent state
As a MariaDB primary server executes transactions, to facilitate replication, each new transaction is appended into the binary log along with its respective GTID, where the domain id, server id, and sequence numbers are taken from the system variables gtid_domain_id, server_id, and gtid_seq_no (which is initialized to 1 and automatically incremented after each new transaction). More specifically, the goal of the binary log is to facilitate replay of its transactions on another server, known as a replica, such that after replay, the data on the replica will be consistent with that of the primary. Where transactions from the same domain id are expected to be ordered within a binary log, transactions from differing domain ids can be interspersed non-deterministically. In other words, as long as the transactions within a single domain id are ordered monotonically, the replay of binary log’s transactions on a replica will result in a state equivalent to that of the primary server, irrespective of if any transactions from other domain ids are executed in-between. Figure 2 illustrates this concept with three binary logs constructed using the same data streams from figure 1. In particular, in the first binary log variant, all of the transactions from domain 1 begin the log, followed by domain 2, and finished by domain 3. In the second variant, the transactions from domain 3 begin the log, followed by domain 1, and ending with domain 2. In the third variant, the transactions from the domains are interspersed throughout the log; however, within each domain, the ordering remains in-tact. Replaying each of these binary log variants on different MariaDB servers of empty state will result in equivalent states between the servers. This replay is supported in two ways. The first approach is the traditional replication workflow, i.e., using the MariaDB Daemon, mariadbd, and is described in the previous paragraph. The second approach is the focus of this blog post, and is done by using the command-line tool mariadb-binlog. More specifically, we use mariadb-binlog to decode a binary log’s transactions for execution via the command-line tool mariadb.
The release of MariaDB Community Server 10.8.1 extended mariadb-binlog to utilize the GTIDs within a binary log to both represent replication state (point 1 above) and ensure data consistency within a domain (point 2 above). This blog post shows how these features can be used to help create a custom replication client using the command-line. Specifically, the –start-position argument represents the current replication state, such that mariadb-binlog will only output events occurring after the sequence number for each provided GTID. The –stop-position argument represents the desired end replication state, such that mariadb-binlog will not output any events occurring after each provided GTID within a domain. The –gtid-strict-mode argument ensures that all events within a domain are strictly ordered by their sequence number, such that mariadb-binlog will exit on error if a lesser sequence number is processed. This blog post highlights how these options can be used to help create an asynchronous command-line replica.
The Design
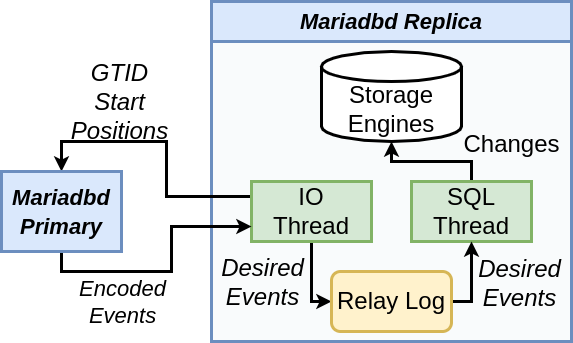
Figure 3: Traditional Mariadbd replication workflow
Before creating our replication client, we first analyze the replication workflow from within a MariaDB server to help draw similarities. Figure 3 details this workflow, which consists of three main components. The Mariadbd Primary is the MariaDB daemon process which the replica aims to mimic. We separate the Mariadbd Replica (blue box on the right), into two sub-components: the IO Thread and the SQL Thread. The IO thread starts the replication process with a request to the primary server for events after its current GTID state (i.e. the value stored in the gtid_slave_pos global variable). After receiving them, the IO thread decides which events should be replicated (e.g. those which are included in optional filters, DO_DOMAIN_IDS, etc), and buffers them into its local relay log.The relay log is a file which shares the same format as the binary log, and simply serves to hold events which are yet to be replicated. The SQL thread executes these buffered events to propagate the data changes into its local storage engines. Once all events from the primary server have been executed by the replica’s SQL thread, their state should be equivalent.
Component MariaDB Server Command-line Replica
Event Source MariaDB Primary Server MariaDB primary server, existing binary logs, existing relay logs
Event Reader IO Thread mariadb-binlog command-line tool
Event Executor SQL Thread mariadb command-line tool
Table 1: Comparing MariaDB server replication components against our command-line client
Generally speaking, this replication process can be abstracted into a form which the command-line replica we are building can derive. In particular, we use three abstractions: 1) an event source, 2) an event reader, and 3) an event executor. Table 1 correlates these abstractions with both the replication implementation in a MariaDB server, as well as the replication client we will build. For traditional MariaDB replication, these components correspond directly to the MariaDB primary server, IO thread, and SQL thread, respectively.

Figure 4: Workflow for our command-line replica
Figure 4 represents the workflow for the replication client which we are building. We use the mariadb-binlog command-line tool as the event reader. The newly added GTID support in mariadb-binlog allows for the filtration and validation of individual data streams. Each domain id can have an associated start position and stop position, and only events within that range will be decoded and validated. The event source can be either a running mariadb server instance or a set of existing binary logs (e.g., from a crashed server), as mariadb-binlog supports both as an input source. The event executor is then the mariadb command-line client, as mariadb-binlog decodes its input into SQL statements and executable comments. Additionally, in-between the mariadb-binlog and mariadb command-line tools, we add an event recorder to monitor replication progress. In particular, the event stream output by mariadb-binlog is decoded into plaintext, which allows for it to be parsed and analyzed for various purposes, such as IO or event counting. For this initial blog post, we will build this to be a very rudimentary file IO analyzer, but part 3 of this blog series will extend this component with more depth. Observe that our replication client does not have the equivalent of a relay log; it simply directs the output from mariadb-binlog into mariadb.
The Implementation
To initially set up our replication client, we start with the command
mariadb-binlog --read-from-remote-server --stop-never $PRIMARY_CONNECTION_PARAMS $BINLOG_FILES | tee >(grep "Rotate to") | mariadb $REPLICA_CONNECTION_PARAMS
which contains all components of our replication client. The event reader is the mariadb-binlog executable, which will connect to our event source. Specifically, we connect to an active MariaDB server instance using the arguments –read-from-remote-server and –stop-never. The environment variables $PRIMARY_CONNECTION_PARAMS and $BINLOG_FILES provide the environment specific configurations to connect to the primary server. The event executor is the mariadb executable (specified at the end of the command), which executes the SQL commands output by mariadb-binlog. The environment variable $REPLICA_CONNECTION_PARAMS provides the environment specific configurations to connect to the replica server. Our rudimentary event recorder is a simple tee with command substitution, tee >(grep “Rotate to”), which analyzes the event stream for rotate events to explicitly see when the underlying binary log file is switched. Below is an example set of environment variables.
export PRIMARY_CONNECTION_PARAMS=--socket=/tmp/primary.sock --user=repl_user export BINLOG_FILES=master-bin.000001 export REPLICA_CONNECTION_PARAMS=--socket=/tmp/replica.sock --user=data_user
Note that in this simple example, both the primary and replica MariaDB server instances co-exist on the same machine where the command-line executables are being run, allowing us to use the socket protocol to connect (or on Windows, it would use a named pipe). To generalize this approach, both the mariadb-binlog and mariadb command-line tools support the TCP connection protocol, allowing these commands to be run from a machine which has access to the network and from a user which is granted the proper access privileges. If directly using binary log files, then mariadb-binlog must be run from a computer with access to those files.
We now look at extending this command-line replica to use GTIDs with mariadb-binlog.
Specifying an initial replication state
The –start-position argument to the mariadb-binlog executable represents the current replication state when provided with a list of GTIDs. This is functionally equivalent to using the variable gtid_slave_pos with CHANGE MASTER TO MASTER_USE_GTID=slave_pos on a replica server. Therefore, we can extend our command to have the form:
mariadb-binlog --start-position=$B --read-from-remote-server --stop-never $PRIMARY_CONNECTION_PARAMS $BINLOG_FILES | tee >(grep "Rotate to") | mariadb $REPLICA_CONNECTION_PARAMS
where $B is a comma separated list of GTID values that specify a Beginning replication state for each existing domain on the replica server. For example, the start positions of replica 1 and 2 from figure 1 would be 1-1-3,2-1-5,3-1-2 and 1-1-2,2-1-3,3-1-2, respectively.
Specifying a replication GTID stop condition
The –stop-position argument to the mariadb-binlog executable functions as the replication stop condition, when provided with a list of GTIDs. This is functionally equivalent to running START SLAVE UNTIL on a replica server. Our initial command can then be extended to have the form
mariadb-binlog --stop-position=$E --read-from-remote-server --stop-never $PRIMARY_CONNECTION_PARAMS $BINLOG_FILES | tee >(grep "Rotate to") | mariadb $REPLICA_CONNECTION_PARAMS
where $E is a comma separated list of GTIDs that specify the Ending replication state. In particular, for each listed domain, transactions with sequence numbers greater than those provided in the stop position list are ignored, and once all stop-positions have been processed, mariadb-binlog will automatically quit.
Ensuring data stream consistency
The –gtid-strict-mode (on by default) argument to the mariadb-binlog executable ensures that all output events are correctly ordered by their sequence number, relative to their domain id. That is, if an event with a GTID sequence number that is lower than the previously seen value for its domain is seen, mariadb-binlog will immediately quit in error. This can be disabled with –skip-gtid-strict-mode; however, it is then recommended to then run with three levels of verbosity (i.e. -vvv), which enables warnings on out-of-order sequence numbers. Running –skip-gtid-strict-mode without three levels of verbosity will completely bypass GTID event validation.
Additional Notes
- All new mariadb-binlog options discussed in this blog post (i.e., –start-position, –stop-position, and –gtid-strict-mode) can be specified simultaneously
- If the intent is to receive the latest transactions from the primary server, the –stop-position option should either be omitted or should be the same value as the primary’s gtid_binlog_pos
- If the primary server is missing early binlogs, e.g. due to a purge, a replica should first be initialized via mariadb-dump
Conclusion and Further Reading
This blog post provided an overview on using GTIDs to maintain replication state for consistent event replay, as well as the workflow of replication on a mariadbd instance. We then used this information to build our own command-line replica using the mariadb-binlog and mariadb executables. Stay tuned for more blog posts in this series, which will extend our command-line client with additional GTID filtering and parallelization (part 2) and replication monitoring (part 3) capabilities.
Further details of concepts described in this blog post can be found in the following links:
- Using Global Transaction IDentifiers
- Using the mariadb-binlog command-line tool
- Filtering on a mariadbd server instance
Special thanks to Andrei Elkin for reviewing both the code patch and this blog post, Anel Husakovic for reviewing this blog post, and Alice Sherepa for extensive testing and hardening of the feature.