
There are different possibilities to benchmark MariaDB servers, with sysbench to be one often used. As sysbench can only use a C connector, any influence another connector could have on the result of a benchmark is typically ignored.
I am working as a connectors developer for Java, Node.JS and R2DBC at MariaDB Corporation. Writing your own benchmarks is for sure not the best solution. At some point I decided to contribute a change to the benchbase framework (formerly oltpbench) which allows the use of MariaDB Connector/J and MariaDB Server.
Now, about three months later, my contribution got integrated and I decided to share a bit about how the benchbase framework can be used, but also how you can run micro-benchmarks to test or evaluate a Java connector.
Benchmark framework
As already mentioned, I’ll use the benchbase framework that permits to easily launch Java “real-world” benchmarks for various databases.
I’ll use 2 different types of benchmark (descriptions from benchbase wiki):
TPC-C
TPC-C involves a mix of five concurrent transactions of different types and complexity either executed on-line or queued for deferred execution. The database consists of nine types of tables with a wide range of record and population sizes. TPC-C is measured in transactions per minute (tpmC). While the benchmark portrays the activity of a wholesale supplier, TPC-C is not limited to the activity of any particular business segment, but rather represents any industry that must manage, sell, or distribute a product or service.
Twitter
The Twitter workload is inspired by the popular microblogging website. In order to provide a realistic benchmark, we obtained an anonymized snapshot of the Twitter social graph from August 2009 that contains 51 million users and almost 2 billion “follows” relationships [14]. We created a synthetic workload generator that is based on an approximation of the queries/transactions needed to support the application functionalities as we observe them by using the web site, along with information derived from a data set of 200,000 tweets. Although we do not claim that this is a precise representation of Twitter’s system, it still reflects its important characteristics, such as heavily skewed many-to-many relationships.
TPC-C is mainly composed of writes while Twitter has more read commands.
Installation
Install MariaDB Server 10.6 with a user ‘admin’ using a password ‘password’ and a database ‘benchbase’ (default benchbase configuration).
Change server configuration according to your server memory in order to have stable results (here is the configuration change for a 64G server)
max_connections=500 innodb_buffer_pool_size=50G thread_handling=pool-of-threads max_heap_table_size=6G tmp_table_size=6G innodb_log_file_size=50G
(then restart server to makes those change effective)
Benchbase needs Java 17 along with a Java 17 compatible maven (>= 3.8).
Clone benchbase:
git clone https://github.com/cmu-db/benchbase.git cd benchbase
Update mysql/mariadb driver in ./pom.xml to the latest available version. At the day of writing this blog post it’s MariaDB Connector/J 3.0.3:
<dependency> <groupId>org.mariadb.jdbc</groupId> <artifactId>mariadb-java-client</artifactId> <version>3.0.3</version> </dependency>
Then build the package:
mvn clean package -DskipTests cd target tar xvzf benchbase-2021-SNAPSHOT.tgz cd benchbase-2021-SNAPSHOT/
Run a benchmark
Configuration files are in ‘config/mariadb/’. Each configuration file indicates connection information and benchmark configuration.
Example for TPCC using mariadb driver in ‘config/mariadb/sample_tpcc_config.xml’:
...
<!-- Connection details -->
<type>MARIADB</type>
<driver>org.mariadb.jdbc.Driver</driver>
<url>jdbc:mariadb://localhost:3306/benchbase?useServerPrepStmts</url>
<username>admin</username>
<password>password</password>
<isolation>TRANSACTION_SERIALIZABLE</isolation>
<batchsize>128</batchsize>
<!-- Scale factor is the number of warehouses in TPCC -->
<scalefactor>1</scalefactor>
<!-- The workload -->
<terminals>1</terminals>
<works>
<work>
<time>60</time>
<rate>10000</rate>
<weights>45,43,4,4,4</weights>
</work>
</works>
...
For this example, the goal will be to see the maximum throughput, setting a warmup of 60 seconds with a run of 600 seconds.
Here is the corresponding change in configuration file :
<!-- Scale factor is the number of warehouses in TPCC --> <scalefactor>128</scalefactor> <!-- The workload --> <terminals>128</terminals> <works> <work> <warmup>60</warmup> <time>600</time> <rate>unlimited</rate> <weights>45,43,4,4,4</weights> </work> </works>
Use the same values for the scale factor and for the number of terminals to minimize the number of possible deadlocks.
Run the bench:
java -jar benchbase.jar -b tpcc -c config/mariadb/sample_tpcc_config.xml --create=true --load=true --execute=true
Benchmark results will be stored in folder ‘results’, listing throughput and different value of latency for each type of transaction per second.
For this specific maximum throughput example, the file of interest is ‘tpcc_<timestamp>.samples.csv’.
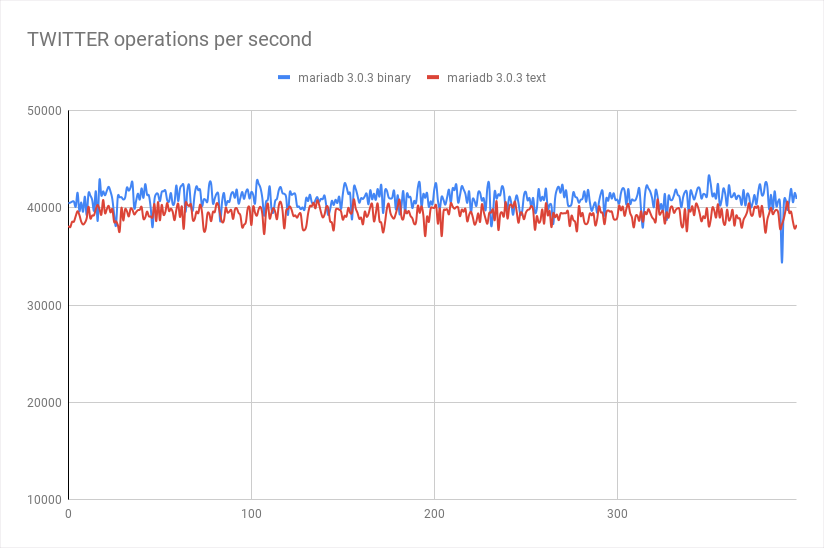
When running the benchmark with connection strings ‘jdbc:mariadb://localhost:3306/benchbase‘ and ‘jdbc:mariadb://localhost:3306/benchbase?useServerPrepStmts‘ you can compare using the binary protocol versus text:

(Down pike corresponds to when dead-locks occurs)
To run another type of benchmark, edit the corresponding benchmark configuration file ‘config/mariadb/sample_twitter_config.xml’ for twitter, and run it using command
java -jar benchbase.jar -b twitter config/mariadb/sample_twitter_config.xml --create=true --load=true --execute=true
results:
Micro-benchmarking
Micro-benchmarking is different, you are measuring the performance of a small piece of code.
OpenJDK JMH is a Java framework permitting micro-benchmark, taking care of things like JVM warm-up and code-optimization paths, making micro-benchmarking as simple as possible.
First JMH dependencies are needed:
<dependency> <groupId>org.openjdk.jmh</groupId> <artifactId>jmh-core</artifactId> <version>1.33</version> </dependency> <dependency> <groupId>org.openjdk.jmh</groupId> <artifactId>jmh-generator-annprocess</artifactId> <version>1.33</version> </dependency>
For example, to test a command returning a resultset with a different number of rows , I am using the mariadb sequence storage engine that permit returning resultset with various size, using commands like “select * from seq_1_to_x” with a different value for X
Here is a benchmark method :
@Benchmark
public int[] testSeq(MyState state) throws SQLException {
int[] values = new int[state.size];
int i = 0;
try (PreparedStatement prep = state.connection.prepareStatement("select * from seq_1_to_" + state.size)) {
ResultSet rs = prep.executeQuery();
while (rs.next()) {
values[i++] = rs.getInt(1);
}
}
return values;
}
Say you want to test “select * from seq_1_to_X” for multiple X values, here is the complete benchmark class content:
@State(Scope.Benchmark)
@Warmup(iterations = 10, timeUnit = TimeUnit.SECONDS, time = 1)
@Measurement(iterations = 10, timeUnit = TimeUnit.SECONDS, time = 1)
@Fork(value = 5)
@Threads(value = -1) // detecting CPU count
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.SECONDS)
public class MyBench {
@State(Scope.Thread)
public static class MyState {
private Connection connection;
@Param({"1", "10", "100", "1000", "10000"})
public int size;
@Param({"false", "true"})
public String binary;
@Setup(Level.Trial)
public void createConnections() throws Exception {
String connectionString = String.format(
"jdbc:mariadb://localhost/db?user=root&useServerPrepStmts=%s",
binary);
connection = DriverManager.getConnection(connectionString);
}
@TearDown(Level.Trial)
public void doTearDown() throws SQLException {
connection.close();
}
}
@Benchmark
public int[] testSeq(MyState state) throws SQLException {
int i = 0;
int[] values = new int[state.size];
try (PreparedStatement prep = state.connection.prepareStatement("select * from seq_1_to_" + state.size)) {
ResultSet rs = prep.executeQuery();
while (rs.next()) {
values[i++] = rs.getInt(1);
}
}
return values;
}
}
The first annotations are for JMH for setting some benchmark options like the warmup time and how long the benchmark should run, how many VMs to use and to set the number of threads to the number of available cores.
Each thread is using a connection first disabling the option `useServerPrepStmts` and then when having it enabled.
Package your project in a fat jar (containing all dependencies) and run it:
mvn clean package java -Duser.country=US -Duser.language=en -jar target/benchmarks.jar
Results:

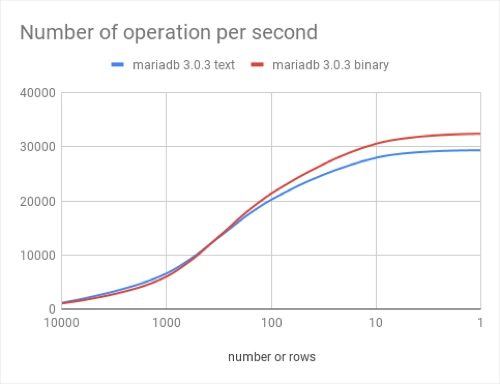
Query “select * from seq_1_to_1” will return one row containing one value (1)
Query “select * from seq_1_to_10000” will return 10000 rows containing one value from 1 to 10000.
See https://github.com/rusher/simple-benchmark for the source of this example.
Comparison
So we have seen that we can easily benchmark connector options like in our example ‘useServerPrepStmts’, using the binary vs. text protocol. But what do we need to do if we want to compare the benchmark results against other connectors?
Configuration for mysql is in the ‘config/mysql’ folder. By default, configuration is ‘jdbc:mysql://localhost:3306/benchbase’ so currently using MySQL connector 8.0.27 (Feb. 1st, 2022) with the same MariaDB database.
Here an example running TPCC with MySQL connector with the previous MariaDB server (just report to mysql configuration the same TPCC configuration):
java -jar benchbase.jar -b tpcc -c config/mysql/sample_tpcc_config.xml --create=true --load=true --execute=true
Which allows us to compare the drivers we could use:
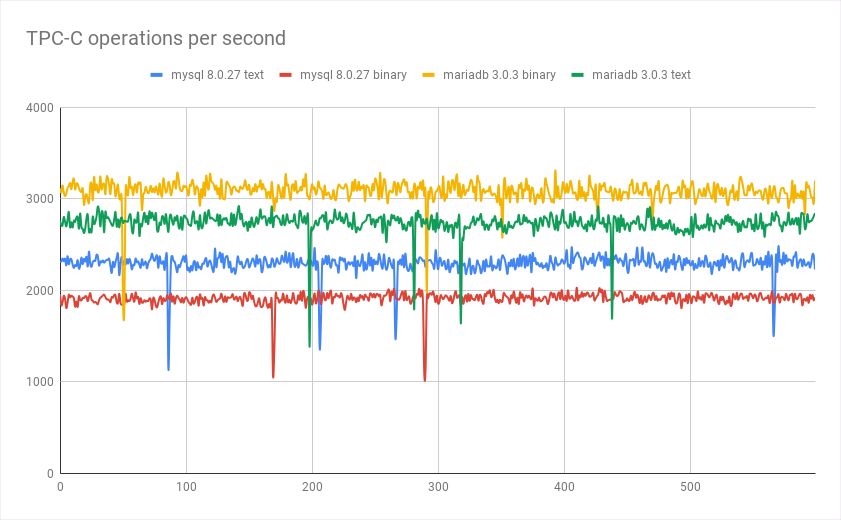
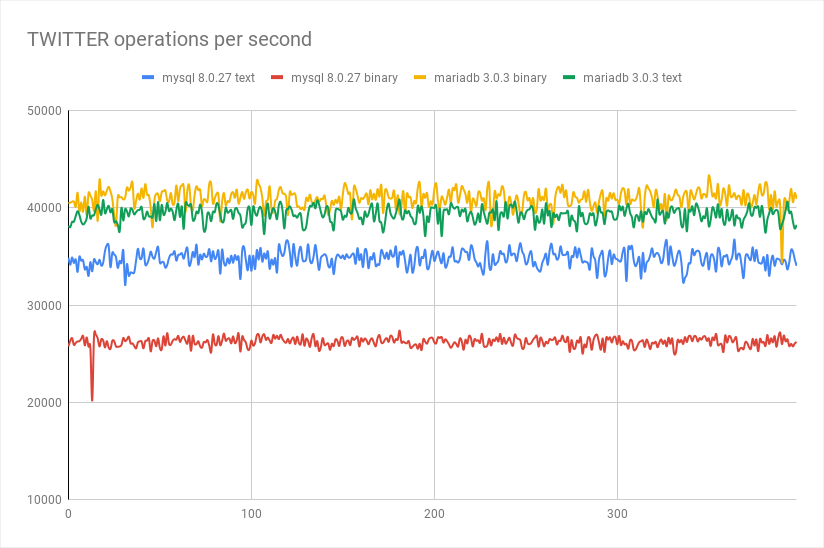
You want to compare connectors (using the same database server) using a micro-benchmark? This is as easy as using the previous example, just add a MySQL driver dependency and add needed parameters (adding sslMode=DISABLED for good comparison since mysql enable ssl by default)
@Param({"mysql", "mariadb"})
public String driver;
@Setup(Level.Trial)
public void createConnections() throws Exception {
String connectionString = String.format( "jdbc:%s://localhost/db?user=root&sslMode=DISABLED&useServerPrepStmts=%s", driver);
connection = DriverManager.getConnection(connectionString);
}
Raw results:

Visual representation:

Conclusion
These figures show that connectors might totally change the results of your benchmark, running with the same database server. So verifying the server implementation is important, but only measuring the complete stack can give you an idea about how your application will perform.