
In this blog I am going to evaluate the use of Intel Optane SSD drives to boost the performance of MariaDB ColumnStore both as storage and for the more novel case as RAM using the Intel Memory Drive Technology (IMDT). Access to the test hardware was provided to MariaDB as part of the Accelerate with Optane Program.
The following deployments were tested (two servers were made available to us):
- Single server with DRAM only, no IMDT memory, Optane storage.
- Single server with DRAM, IMDT memory, Optane storage.
- Two node combined (User Module and Performance Module on each server) with DRAM, IMDT memory and Optane storage.
Each server has 2 Intel® Xeon® Gold 6142 CPU’s (32 cores), 192GB DDR4 RAM, 1 4TB NVME SSD disk, 3 750GB Intel® Optane™ P4800X drives, and bonded 2*10gpbs network cards.
We utilized a TPC-DS like benchmark for comparison purposes as well as the Star Schema Benchmark (SSB) in our tests.
Data Loading
First we look at data loading performance. In this case we utilize the TPC-DS like schema and data set with scale factor 1000 resulting in approximately 1TB of csv data files. The test environment utilizes one Optane P4800X per node for the dbroot storage and the NVME SSD disk for data file storage. Both load tests kicked off table cpimport jobs in parallel to aim to take full advantage of the system.
| Configuration | Load Time |
| Cpimport mode 1 (centrally loaded from 1 file / node) jobs running in parallel | 51 minutes 20 seconds |
| Cpimport mode 2 (data is pre-partitioned and loaded from each PM node) jobs running in parallel | 22 minutes 30 seconds |
Queries
Introduction
An implementation of the Star Schema Benchmark (SSB) for MariaDB ColumnStore is available here: https://github.com/mariadb-corporation/mariadb-columnstore-ssb. This includes queries and a DDL file specifically for MariaDB ColumnStore as well as varying helper scripts used in this effort.
The Star Schema Benchmark focuses on 4 different typical star schema query patterns against a lineorder fact table and several dimension tables. The tests were run with scale factor 1000. Due to the nature of the SSB data generator, the CSV data file size is actually closer to 600GB than 1TB in size.
One area where ColumnStore does not often shine so well with generated benchmark data is that the product does not yet have the capability to perform sort on ingestion. The trade off is that ColumnStore data ingestion and ongoing maintenance is lower since you do not need to worry about data skew where one data node ends up with more data than the other. SSB, like many other benchmarks, generates data in a semi random order. In particular the date fields are not ordered in the data files. In the real world, most systems will end up having date fields generally increasing over time allowing ColumnStore to perform partition elimination as an optimization. To mitigate this a script was developed to partition the lineorder file by order date year and then load the data by year. Further partitioning / sorting of the data would yield even better results for queries filtering by quarter or month.
Finally, for larger systems and data sets, the following settings in ColumnStore.xml are adjusted to provide improved performance:
- MaxOutStandingRequests (20->32) to bias faster query response time by utilizing more cpu cores at the expense of concurrent throughput.
- PmMaxMemorySmallSide (64M->2048M) with larger memory machine and fast networks it is highly advised to increase the threshold below which joins are pushed down to the PM nodes.
Single Node Performance
First cold query performance is measured which measures the query performance in a cold cluster with no previously cached data, i.e. data must be read from the Optane SSD being used for storage. This was performed for 3 scenarios:
- IMDT memory enabled (1.4TB RAM: 1280GB IMDT + 192GB DRAM) with default (not date sorted) lineorder data
- IMDT memory enabled (1.4TB RAM: 1280GB IMDT + 192GB DRAM) with lineorder data ordered by year
- No IMDT memory enabled (192 GB DRAM only) with lineorder data ordered by year
Since the purpose of the benchmark is to look at the effectiveness of using the Optane SSD for memory caching, the performance is measured for repeat queries where the table data will already be cached (and the additional memory footprint ensures complete caching):
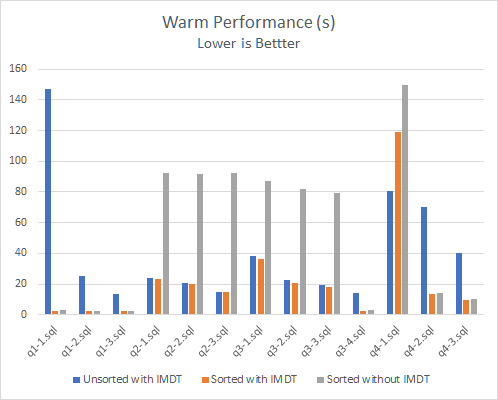
It is clear here that for many queries whether the data is unsorted or sorted, the increased memory allows significant gains in query performance. Comparing bar 2 (with IMDT) and bar 3 (without IMDT) it can be seen that especially for queries that must scan all rows of the table there can be a significant multiplier in performance. In the case of q2-3 this brings performance gains of 620%.
Another interesting pattern is observed for queries scanning the entire table which is, repeat runs become faster. This is due to the IMDT driver intelligently moving the frequently accessed data to DRAM which is faster than the Optane IMDT memory. However the first time results are impressive showing that IMDT works very well for large memory block caches such as MariaDB ColumnStore:
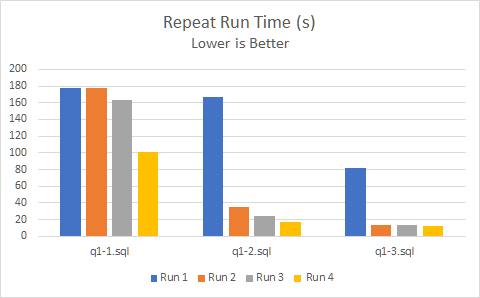
In this case the data is taken from the ‘Unsorted with IMDT data set’ scenario. Even without partition elimination Q1-1 scans the largest amount of rows and so takes longer overall than Q1-2 and Q1-3 which progressively filter down to smaller data sets for aggregation. For Q1-1 the most dramatic effect can be seen going from about 180s down to 100s. This is very nice capability for frequently accessed data.
Two Node Performance
MariaDB ColumnStore can provide additional performance by adding additional PM nodes. Going from 1 to 2 PM nodes will see a reduction in query time of 50% for the same data set size / hardware since now each PM can work in parallel processing 50% of the data compared to 1 node.
| Test | Total Cold Time (s) | % Improvement | Total Warm Time | % Improvement |
| 1 Node Unsorted | 1343.16 | 530.02 | ||
| 1 Node Sorted | 714.05 | 284.87 | ||
| 2 Node Unsorted | 813.82 | 165% | 207.99 | 255% |
| 2 Node Unsorted w/ Data Redundancy | 951.01 | 141% | 243.53 | 218% |
| 2 Node Sorted | 366.32 | 195% | 119.41 | 239% |
The above table shows the total time across all SSB queries for a cold and warm database. In general the percentage improvement is at least twice moving from 1 to 2 nodes. The improvement for unsorted data is not as high as expected but there was not time to determine if this was an anomaly (cold times were only measured once as opposed to an average of 3 for warm).
A further point of interest is that in deploying the 2 node cluster utilizing the Data Redundancy option demonstrates that the underlying GlusterFS is only adding a 17% overhead. In return the cluster could survive the failure of one of the nodes since both nodes have redundant copies of data.
With the restrictions of the test environment both single server and 2 node combined deployments allocated 50% of RAM for block cache meaning 736GB of RAM for single server and 1472GB of RAM for 2 node combined. If the cluster was deployed as 1 user module, 2 performance modules then 2335GB of RAM would be utilized as block cache with the default allocation of 80% RAM for dedicated performance module servers.
Summary
The Intel Optane drive provides some very interesting benefits for ColumnStore. I’m especially excited about the potential shown when combined with the Intel Memory Drive Technology to provide extended addressable RAM. A real world ColumnStore deployment will utilize a significant portion of RAM for block caching. With this workload, mapping the Optane Drive provides a lower cost option of enabling ColumnStore as an in memory database.
Finally in addition Intel Optane storage performs very strongly when deployed as the persistent storage volume. We also see low overhead when deployed with our data redundancy feature to allow for data storage high availability in conjunction with local storage.