
Modern Analytics Made Easy
MariaDB Enterprise can be deployed as a columnar database for real-time analytics at scale, using distributed data and massively parallel processing (MPP) to perform interactive, ad hoc queries on hundreds of billions of rows with standard SQL. Further, MariaDB Enterprise implements a cloud-native storage architecture, and can optionally use object storage services in public or private clouds to lower costs and store an unlimited amount of data.

What’s New
Simplified install
Just add the MariaDB ColumnStore plugin to one or more MariaDB Enterprise Server instances and run the post install/configuration scripts.
Cloud-native storage
Store columnar data on any object storage service compatible with the Amazon S3 API for scalable, real-time analytics at a lower cost.
Faster queries
Query data faster than ever with up to 2x faster joins and 50x faster sorting thanks to a new hash join algorithm and ORDER BY pushdown.
Why Now
Business today is undeniably data-centric. Near-real-time insights from MariaDB’s efficient, flexible and infinitely scalable analytics give you a competitive advantage.
Store a lot more data and analyze it faster
MariaDB Enterprise lets you scale analytic workloads when they’ve outgrown traditional databases like Oracle Database and MySQL.
Run interactive, ad hoc queries on demand
MariaDB Enterprise allows you to analyze data in unlimited, unforeseen ways because it doesn’t need indexes to improve query performance.
Move faster with access to near-real-time data
MariaDB Enterprise can import streaming data from Apache Kafka so you’re always analyzing the latest data, not some week-old data.
Components
Enterprise Server
The only open source database with Oracle Database compatibility (i.e., PL/SQL), temporal tables and transparent data encryption.
ColumnStore
A storage engine optimized for analytical workloads – the data is distributed for scalability and stored by column for performance.
MaxScale
The world’s most advanced database proxy: intelligent routing, automatic failover and a powerful database firewall.
Kafka connector
A streaming data adapter for automatically and continuously consuming Apache Kafka messages and writing them directly to storage.
Spark connector
A bulk data adapter for publishing machine learning results from Apache Spark for ad hoc, interactive analysis with standard SQL.
Import connectors
C, Java and Python import connectors for bypassing SQL to import data directly from remote applications, services and scripts.
Architecture
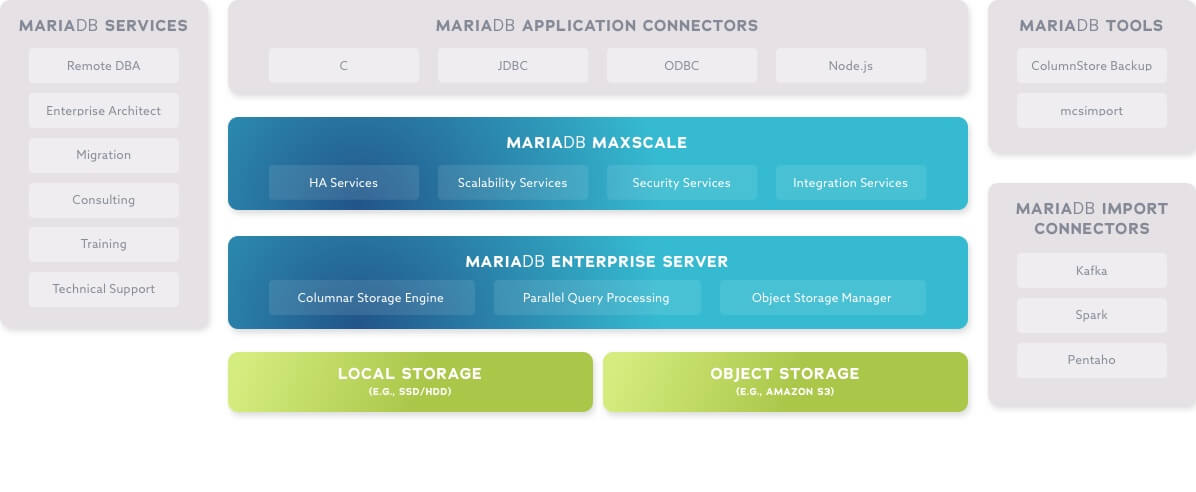
Modern Analytics
Scalability and performance
MariaDB Enterprise scales out to billions of rows and uses massively parallel processing to analyze the data in a matter of seconds.
Columnar format and compression
MariaDB Enterprise can store data in a columnar format for fast analytics and up to 10x data compression on disk.
Kafka and Spark connectors
MariaDB Enterprise has Kafka and Spark connectors for ingesting streaming data and publishing machine learning results.
Standard ANSI SQL with no limitations
MariaDB Enterprise, unlike Hadoop and NoSQL databases, supports analytics on hundreds of terabytes of data with standard SQL.
Direct, on-demand imports from the source
MariaDB Enterprise includes connectors for importing bulk data from C, Java and Python applications, services and scripts.
Open source on commodity hardware
MariaDB Enterprise is production-grade open source, runs on premises or in the cloud, on servers or containers, and with HDDs or SSDs.



Services and Support
Enterprise subscriptions include world-class, 24×7 technical support. If that’s not enough, Enterprise customers can add consulting services to get proactive recommendations and advice based on decades of experience. Further, a dedicated team of remote DBAs, enterprise architects and migration managers is available to ensure customers succeed – whether it’s migrating from a legacy data warehouse or integrating with Apache Spark, Apache Kafka and Apache Hadoop.