
Despite the laws of physics, modern apps are increasingly global in nature. This tug of war is seen when cloud regions – perhaps across a continent – are working in conjunction to reduce user/customer latency or as hot cooperative DR regions.
For cross-region data access, you must contend with the speed of light, network routing bottlenecks, connection loss and lost packets. For instance, on Amazon AWS, a ping from us-west1 (CA) to us-west-2 (OR) at 99th percentile latency can be up to 70ms, and with a high degree of jitter causing latencies to sporadically degrade to multiple seconds. Throughput rates (bytes transferred per second), on the other hand, are significantly higher across regions (data centers spread across large distances) and zones.
Simply put, when replicating data to different regions, the design choices within the database engine have a huge impact on real time access to data, performance and reliability.
There are many approaches to how data gets replicated over large distances in modern DBs. Some rely on a single primary node to send all events in strict order, some achieve distributed consistency with globally managed transactions and some NoSQL based systems only aim for eventual consistency with no support for transactions. The common practice is to relegate the responsibility to an external “replication server”, limiting throughput. To counter, PostgreSQL supports streaming replication of the binary WAL (Write Ahead Log) but carries the potential risk of replicating corrupted records in the WAL.
We decided to aim for highest possible throughput by aggressively capitalizing on inter and intra node parallelism and assume an abundance of network bandwidth across large distances.
In this post, I describe how MariaDB Xpand’s new parallel replication architecture delivers extreme throughput across global regions, the primary use cases where it is applicable, and a comparison to popular alternatives (Amazon Aurora and Google Spanner). I also provide a glimpse into its performance through a benchmark we conducted for a customer – demonstrating the near linear scaling characteristics across global regions using modest infrastructure.
Requirements
Businesses everywhere face unpredictable demand and change. They need a database that handles sudden spikes in transactions and diverse workloads while maintaining strict data consistency and availability. MariaDB Xpand is a fully distributed SQL database with a shared nothing architecture. Unlike AWS Aurora’s storage replication or PostgreSQL’s read replication, Xpand is a true multi-writer – any node can be written to and adds scale for reads and writes.
Let me step back and list a few of the most important requirements when replicating a database:
- Lowest possible write latency: Any change in any region should become visible as quickly as possible in other regions. You have to anticipate complex write patterns from apps: Small updates, a sequence of individual transactions in response to user action, a batch process moving massive amounts of data.
- Very fast local reads: To the extent possible you don’t want to hop over synchronously to remote regions on every read. Serving a single web page typically requires multiple DB reads.
- Multiple topologies (Active-Active, Active-Passive): Data changes can occur simultaneously in different regions (Active-Active), or apps may designate a single location as primary and only allow reads from other sites, or to failover from the primary to secondary for Disaster recovery (Active-Passive).
- Protection against failures: Connections across regions could fail or be exposed to unpredictable pauses. To the extent permitted by your application you want the readers and writers in each region to continue unhindered.
- Security, compliance and data governance: There is a lot to unpack here and beyond scope for this blog.
Horizontally partitioned, scalable replication in Xpand 6.0
Xpand has supported asynchronous cross region replication for many years. Applications use SQL to turn ON transaction logging (binlogs, which contain committed transactional events) on the emitting “master” cluster, and instruct the receiving “target” system to stream these events into the database on the target (at a statement or row level). The different topologies supported are depicted in the schematic in Figure 1.

Figure 1: Different replication topologies supported by Xpand
To achieve extreme scale for replication, we adopted the same strategy we use for scalable tables. The architecture is depicted in Figure 2. The primary side stores replication events into binlogs. They are implemented more or less as sets of regular Xpand tables (sliced and distributed across nodes). The target cluster uses a configurable number of readers to stream data in batches from the binlogs, in parallel.
The “master” replies to multiple concurrent pull requests from these readers, and serves streams of events to each independently and in parallel, while preserving the logical consistency of the transactions in the workflow.
We harness the power of the entire cluster to stream to the targets without any choke points (i.e., no single streaming pipe to targets). Scaling replication becomes as simple as horizontally scaling your cluster capacity. As noted before, given the abundance of bandwidth on the network (i.e., you can have many parallel pipes across distributed regions) we can now keep up with very high write rates.

Figure 2: Parallel Replication across two clusters
A peek below the surface
The target cluster pulls committed changes as fast as possible, without loss of transactional consistency or loss of ordering. Xpand uses consistent hashing to map the keys to the streams spread across the cluster. Changes to the same key are always mapped to the same stream preserving ordering at a key level.
And the logic to preserve consistency on the target cluster doesn’t end there. Each target’s reader continuously applies the changes to the database using configurable batching before committing the full batch. In other words, the incoming streams are immediately written to the DB but only committed in batches. Essentially, the design allows entire transactions to be processed atomically, and they remain isolated from other concurrent activity on the target cluster. Xpand uses MVCC for its concurrency control, so readers don’t have to acquire any locks or get a partial view of the transactions being replayed from the primary cluster.
Figure 3 depicts how concurrently running transactions on the master are micro-batched and load balanced across the available connections to the target where they are buffered and committed in larger batches. For instance, as shown in Figure 3, transactional events (Insert :Txn1) followed by (Update:Txn1) could get transmitted to the target cluster on two independent streams. Each stream reader accumulates these transactional events and the target cluster coordinates a distributed commit, periodically.

Figure 3: Parallel streaming of writes
To summarize, the design favors doing as much in parallel as possible to achieve the highest possible replication throughput without compromising consistency. The asynchronous nature of replication ensures the replication doesn’t degrade the write latencies on either end or impact availability when the link is severed.
Popular replication systems and their tradeoffs
Distributed replication in databases has been around for decades. I will only focus on the two that seem to attract the most attention lately.
Google Spanner
Spanner (a globally distributed database) delivers transactional consistency and serializability guarantees at a global scale and has knobs for fine grained placement of data – who owns it, how many global copies, where it is copied, and so forth. The flexibility is quite attractive.
But achieving strong consistency guarantees comes at a price:
- Delayed commit: For transaction serializability, Spanner has to make it appear as if the clocks across all the global regions are fully synchronized. But, clocks across regions will always have a small amount of skew. Spanner utilizes the concept of an “uncertainty” window which is based on the maximum possible time skew across the clocks on the servers in the system. After completing their writes, transactions wait until after this uncertainty window has passed before they allow any client to see the data that they wrote. So, if the maximum skew was 20 ms, each commit would incur this additional delay. I suggest this reading if you are keen on the details.
- Synchronous writes: Google Spanner effectively does replication through its distributed transaction layer, which uses a Paxos-based distributed transaction commit protocol. The downside to this approach is that inter-region replication can have significantly higher write latency. For more details, see this article.
If your application requires high write rates or requires consistent latencies, the price might be too high. You could be looking at hundreds of additional milliseconds per transaction commit.
Amazon Aurora
Aurora is an optimized single node db engine with a distributed storage layer. All intra-region replication is handled through its rather opaque storage sub-system. Its high level architecture is described here.
Aurora does synchronous replication at the Aurora Storage layer within a region, which has the properties of any storage-based replication solution. That is, it preserves write-order across all storage objects that store data or metadata for a given Aurora database. For cross-region replication, Aurora uses asynchronous log-based replication, which means that data loss is possible in the event of a cross-region disaster recovery (DR) failover.
Aurora’s replication solutions are based on conventional replication or distributed transaction techniques, neither of which are novel.
Use cases for MariaDB Xpand 6.0
Disaster recovery and continuous availability
The most obvious configuration is setting up a cluster in your primary application region and asynchronously replicating to another cluster in a remote region. If the primary cluster fails or becomes unavailable, applications can easily failover to the secondary cluster.
MariaDB connectors are designed to failover in case the primary cluster is not accessible.
For instance, with MariaDB Connector/J the JDBC URL supports specifying an alternate cluster to failover to:
jdbc:mariadb:replication//<hostDescription>[,<hostDescription>...]/[database][?<key1>=<value1>[&<key2>=<value2>]...]
Read more on how this works here.
Isolating OLTP and OLAP workloads
Xpand 6.0 added support for operational analytics through its Columnar indexing feature. Applications can now create columnar indexes on attributes commonly used in Analytical class queries to boost query performance – for scans, filters and aggregations.
Traditionally, when working with large data sets, the highly parallelized analytic queries can run for a longer duration and potentially consume most of the cluster compute power. To minimize the impact to OLTP operations (i.e., the response time for common online app queries) a common best practice is to split the processing by isolating Analytic workloads. The conventional way to accomplish this would require expensive ETL, data pipelining into a warehouse or data mart and living with analysis on stale data.
Instead, with Xpand’s real time continuous replication to another cluster you can deliver near real time analytics without the added complexity of ETL.
Global scale applications
The new mantra for growth is to “think globally, act (process) locally”. As enterprises move to the cloud, they are increasingly extending their reach to customers across continents. This is happening across all verticals. These global applications need instant visibility to data across geographies and have to comply with data sovereignty regulations. Xpand parallel replication provides global visibility with localized access and also permits explicit control over which data sets can replicate to which cluster (at a table level).
Real time data access across cloud providers
When it comes to mission critical application data, many applications and services need access to the data in real time and without data quality compromises. Xpand’s replication is designed to work across regions within a cloud provider, across cloud providers, across on-prem data centers or across a hybrid cloud environment.
Easy peasy SQL squeezy commands
You can get going with parallel replication using just two simple commands.
- Configure binlogs for your database or specific tables:
CREATE BINLOG 'binlog_name' [LOG (target1, target2, ...),] [IGNORE (target3, target4, ...),] [FORMAT='ROW'] Here the option LOG argument identifies the list of databases or tables to log. For instance, to replicate an entire Database CustOrders, you would use: CREATE BINLOG ‘ORDERSDB_LOG’ LOG CustOrders ;
2. Configure the parallel target readers in the secondary clusters:
CREATE SLAVE replica_name PARALLEL_LOG = primary_log_name, PARALLEL_POS = position, SLICES = num_slices, BATCH_SIZE_MS = batch_size [, primary_HOST = primary_host] [, primary_USER = primary_user] [, primary_PASSWORD = primary_password] [, primary_PORT = primary_port]; To replicate from the above mentioned source CustOrders primary Xpand cluster, you would use CREATE SLAVE ‘ORDERSDB_replica’ PARALLEL_LOG = ‘CustOrders’, SLICES = 20 ; This would result in 20 target readers streaming the distributed BinLogs from the master cluster.
The details of the programming model are available here.
How fast does it go?
Recently, Xpand parallel replication was put to the test to meet a set of strict requirements from a customer. The main requirement from the customer was to prove a high sustained transaction rate in an Active-Active configuration between two regions (US West, US East in AWS) having less than 5-second replication lag between them. Specifically, they required at least 10K transactions/second on each region with a mix of reads and writes and a replication lag of no more than 5 seconds.

Figure 4: Benchmark setup
We configured each region with a 9 node cluster (each node with 32 vCPUs and spread across 3 availability zones), provisioned 10K IOPS and abundant disk capacity.
We used sysbench (a popular benchmark suite for OLTP databases) to simulate the application workload with a 70:30 read-to-write ratio. We executed sysbench at scale (simulating 512 concurrently active DB clients) and sustained the activity for 30 minutes. The results are shown below.
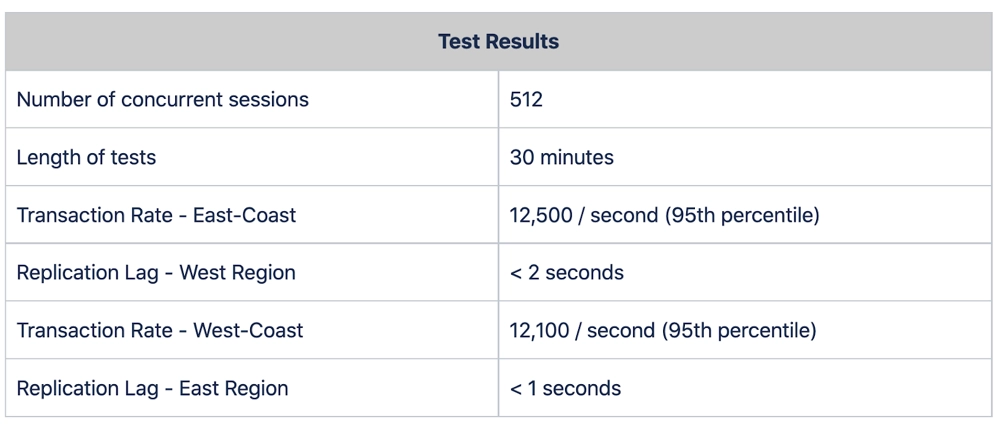
From the benchmark results, the Xpand parallel replication has exceeded the customer’s requirements, maintaining less than 2 seconds lag time throughout the testing period of 30 minutes. In total, there were 24,600 transactions per second processed between the two regions.
Give it a go yourself
Start your trial today or for the easiest and fastest way to get started use Xpand in the cloud. Help is available on the MariaDB Community Slack.