
In this post, we’ll explore the enhancements made to MariaDB’s backup and restore tools, mariadb-dump and mariadb-import, implemented in MDEV-33635 and MDEV-33627.
TL;DR: MariaDB 11.6 introduces a new backup format for logical backups with mariadb-dump (output to a directory) and an option –parallel that supports parallel backup and restore operations.
Parallel Logical Backup and Restore in MariaDB 11.6
Over the past decade or two, there have been numerous attempts to add parallelism to database backup processes in the MariaDB/MySQL community. Tools like MyDumper emerged, mysqlpump was developed (and is now nearing its end of life), and MySQL Shell Utilities provided enhanced logical backup capabilities.
While it might be tempting to discard older tools in favor of newer ones, at MariaDB, we usually prefer to build on proven solutions. mysqldump existed for a quarter of the century, was used to create billions of dumps, it has seen a huge amount of rare corner cases and was fixed to work for them all. It would be unreasonable to throw all that knowledge away.
With MariaDB 11.6, we’ve introduced a new “directory” backup format and added parallelism to the mix—enhancing, not replacing, the existing tools.
mariadb-dump output formats and the new --dir option
Traditionally, mariadb-dump (former mysqldump) outputs to a single file or standard output, generating SQL commands like CREATE TABLE followed by multi-row INSERTs. This format is optimized for restoration via command-line client and includes numerous tricks to improve performance, such as disabling keys and batching inserts. The output can be piped and transformed by other tools, for example compressed and encrypted.
It is not ideal when it comes to parallelism. Writing a single text file with multiple threads is possible, but not likely to produce desired output.
Multiple-file Output Format with --tab
Less commonly known, yet existing since prehistoric times, is the --tab=path option, which generates separate files for each table in the database. For each table, it creates a .sql file with the table’s DDL and a .txt file with tab-separated data, hence the name. This format is more suitable for parallelization but lacks the ability to back up all or multiple databases at once.
Introducing the --dir Option
Building on the --tab option , the new --dir=path option outputs a structured directory format. The specified path must exist and be writable by the server. Each database is stored in its own subdirectory, making it easier to manage and restore. The subdirectories store .sql and .txt files, in the same format as --tab output.
Here’s an example of how the directory structure might look:
mariadb-dump -uroot --dir=/path/to/dumpdir --all-databases --verbose /path/to/dumpdir ───mysql │ columns_priv.sql │ columns_priv.txt │ ... ├───sbtest │ sbtest1.sql │ sbtest1.txt ├───test │ t.sql │ t.txt
Parallel Backup with the --parallel Option
To enable parallel backup, simply specify --parallel=<N>. This option opens multiple connections and divides the dump process across them. It works seamlessly with both the --dir and --tab options. You can combine this with other options, such as --single-transaction, to ensure a consistent (point-in-time) backup, even though multiple connections are used. This is similar to what mydumper does, ensuring all transactions start at the same “logical time” using a synchronization mechanism.
Here’s how you can perform a parallel backup with 4 concurrent connections:
mariadb-dump -uroot --dir=/path/to/dumpdir --all-databases --parallel=4 --verbose
Restoring with mariadb-import
To complement the new --dir option, mariadb-import (formerly mysqlimport) now supports this format. Although mysqlimport was somewhat obscure, its original purpose was to restore tables backed up with the --tab option. Now, with enhancements for multi-threading and handling --dir, we hope it finds its way from obscurity into the mainstream.
To restore a database with 4 concurrent connections, use:
mariadb-import -uroot --dir=/path/to/dumpdir --verbose --parallel=4
Partial Restore Options
The new format also allows for partial restores, thanks to the new mariadb-import options:
Include-only options:
--database: Specify databases to include--table: Specify tables to include
Exclude options:
--ignore-database: Exclude specific databases--ignore-table: Exclude specific tables
Performance Benchmark
Since the primary goal of these enhancements is to improve performance, let’s take a look at a benchmark comparing traditional single-file output with the new --dir and --parallel options.
The benchmark was conducted on a Windows desktop with a Kingston SVNS1000G disk drive, using sysbench to load four tables with 10 million rows each. Options for the server are --innodb-buffer-pool-size=20G --innodb-log-file-size=20G, the data size is about 9GB, that means data is cached. In real life the data size might be considerably larger than the bufferpool, and the benefits of parallel execution can be much smaller.
Backup Performance Comparison
| Backup Type | Command | Cold Cache Time (sec) | Warm Cache Time (sec) |
|---|---|---|---|
| Classic | mysqldump --databases sbtest > sbtest.sql | 49.05 | 38.33 |
| Parallel | mysqldump --databases sbtest --dir=11.6-dump --parallel=4 | 20.66 | 8.37 |
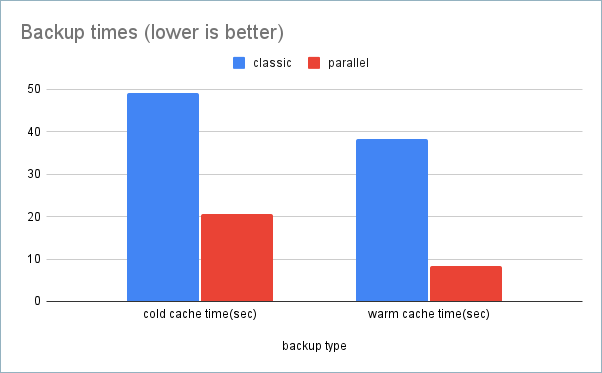
With the warm cache backup scales linearly! Dumping with –parallel=4 is four times faster than without parallelism. The “cold cache” case, it seems to add 11-12 to bring data from the disk to bufferpool.
Restore Performance Comparison
| Type | Command | Load Time (sec) |
|---|---|---|
| Classic | mariadb < dump.sql | 274.77 |
| Import (Parallel=0) | mariadb-import --dir=11.6-dump | 168.266 |
| Import (Parallel=4) | mariadb-import --dir=11.6-dump --parallel=4 | 90.65 |
| Sysbench Prepare | sysbench oltp_update_index --tables=4 --table-size=10000000 --threads=4 prepare | 73.75 |
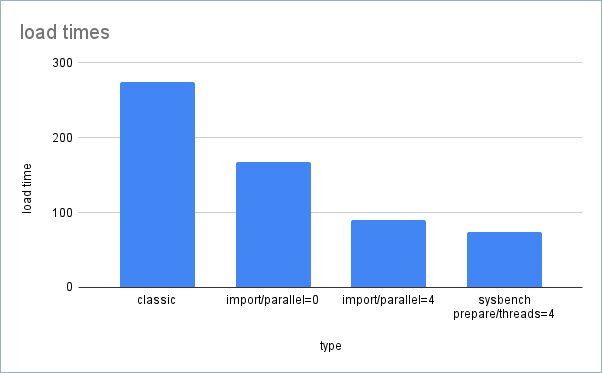
As shown, both backup and restore times significantly improve with the --dir option, even without parallelization. The effects of parallel running are visible, though not as linear, as in the “backup” case – this is a write workload, more things are going on , e.g purge, redo log and doublewrite IO.
Future plans
While these improvements already offer serious benefits, there are still areas for further optimization. One such area is the delayed creation of secondary indexes for InnoDB until after data loading, to beat “sysbench prepare” from above benchmark. Additionally, better handling of binary data in the current format is needed, possibly through support for --hex-blob in tab-separated data files.