
Now that the MariaDB Vector preview is out, let’s see how it compares with other vector databases. I’ll use a popular ann-benchmarks suite for this. It has many different datasets and supports a lot of different vector search implementations (13 datasets and 40 implementations at the moment of writing this blog post). And while it doesn’t have many different realistic workloads, it’s good at testing pure algorithm index building and search speed.
I’ll limit the comparison to vector databases only, excluding pure vector search libraries. And only to datasets that need Euclidean distance metric, not cosine or Jaccard — simply because MariaDB Vector preview only supports Euclidean (but we plan to add cosine before the release). Thus, I’ll benchmark:
- MariaDB Vector commit 23ecb6ec89a: native vector search functionality of MariaDB Server
- pgvector commit bb424e96e7: vector similarity search extension for PostgreSQL
- Qdrant 1.5.1, client version 1.5.4: vector database (excluding binary quantization that provided a very poor recall for used datasets)
- RediSearch 2.6.13 commit f966d37: a query and indexing engine for Redis
- Weaviate 3.16.0: vector database
using the following datasets:
- MNIST — 60,000 vectors of 784 dimensions, rather small.
- Fashion-MNIST — 60,000 vectors of 784 dimensions, supposed to be more difficult than MNIST.
- SIFT — 1,000,000 vectors of 128 dimensions. Much larger, so more difficult to get good results.
- GIST — 1,000,000 vectors of 960 dimensions. Large dataset and long vectors — this is the slowest and the most difficult dataset.
Note that ann-benchmarks doesn’t support MariaDB Vector out of the box (yet). It was extended to do so by Hugo Wen from Amazon. I used my fork of his branch to obtain all the results below.
Hardware-wise I used a machine with 24-core (hyperthreaded to 48 vCPUs) Intel Xeon Gold 5412U 3900 MHz, 256GB RAM, Samsung NVMe SSD PM9A1/PM9A3/980PRO, all under Ubuntu 24.04 LTS Noble Numbat.
And this is what I’ve found.
The plots
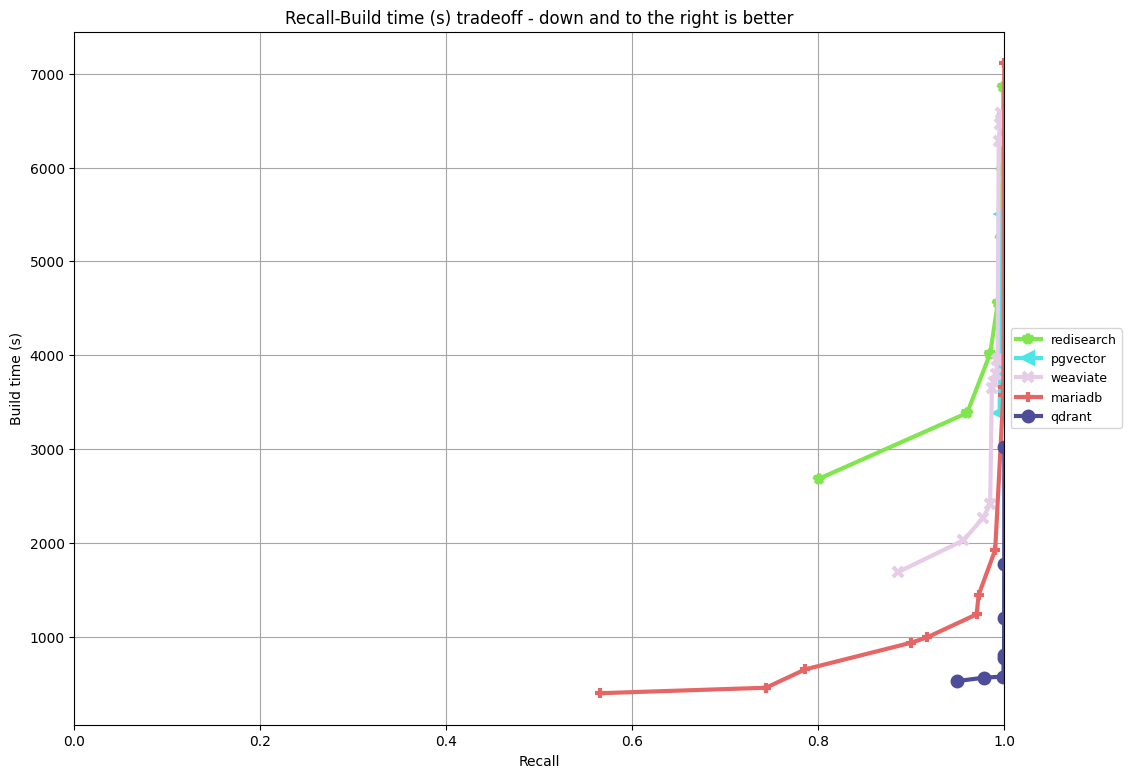
All plots were created by the ann-benchmarks plot.py tool. It plots the index build time or the qps against the recall. The search is always approximate (“ann” in “ann-benchmarks” means Approximate Nearest Neighbor), and recall shows how close the result is to the exact search. If the recall is 1 — the search is exact. You can roughly think of the recall of 0.99 as when you do SELECT … LIMIT 100, you can have one row which is different from the exact result you would’ve got with a full table scan. Because everything — recall, build time, qps — heavily depends on the index and search parameters, ann-benchmarks automatically tries various combinations of them, as instructed by the configuration file, and selects the best result. Meaning, the qps-vs-recall plot, for example, shows the best qps one could get for a given recall.
Database size
Only mariadb and pgvector algorithms (ann-benchmarks calls vector search implementations algorithms, let’s stick to this terminology) implement a method to estimate the index size. MariaDB Vector creates an index about half the size of what pgvector does — which was expected, because we need two bytes per dimension and pgvector uses four. I couldn’t compare with other vector databases, unfortunately.
Indexing time
This is the time from the point when a table is empty, to the point when a vector index is completely built. Many vector databases insert the data first and then build the index. As of today, MariaDB Vector does not support that yet, we build the index slowly, as the data is inserted, row by row.
Below are the results for all the four datasets, from easiest to the most difficult. Note how build takes longer, qps drops and recall becomes worse as the amount of data grows. As results tend to crowd near the right end of the plot, I’ll show everything in linear and in logit-log scale to have a better view of close-to-one recalls.
MNIST-784-Euclidean:


Fashion-MNIST-784-Euclidean:


SIFT-128-Euclidean:


GIST-960-Euclidean:

Search time
Here ann-benchmarks measures qps — queries per second, the more qps the better. As before, it plots the best qps for a given recall and I’m showing linear and logit-log scales.
MNIST-784-Euclidean:


Fashion-MNIST-784-Euclidean:


SIFT-128-Euclidean:


GIST-960-Euclidean:


Concurrency
To see how well a particular vector database scales with concurrent load, I used ann-benchmarks in batch mode. In this mode the python module implementing a particular algorithm (for example, access to MariaDB Server via MariaDB Connector/Python) gets all query vectors at once and sends them to the database in parallel, in multiple connections. The concurrency is set to the number of CPUs. One could expect that with 48 CPUs there would be a significant qps boost. Let’s see if this is, indeed, the case.
MNIST-784-Euclidean:


I’m only showing MNIST, because this shouldn’t depend on the dataset.
Conclusions
MariaDB Vector shows a very competitive performance. It demonstrates the highest qps for a given recall on smaller datasets, with RediSearch being the second, and on large datasets MariaDB Vector comes a close second after RediSearch. On the other hand, MariaDB Vector builds an index faster than RediSearch. Interestingly enough, specialized single-purpose vector databases didn’t turn out to be much faster. They search worse than both MariaDB Vector and RediSearch. And except for Qdrant on the GIST dataset the indexing time isn’t better either.
Concurrency results are baffling. It’s hard to imagine that all tested databases are that bad at scaling. I’d rather shrug it off as some bug in the corresponding python module for a specific database. On the other hand, it’s almost as difficult to believe that they all, except for MariaDB, have this bug in their python modules. Perhaps, developers familiar with these databases could take a look at ann-benchmarks batch mode and explain the bad scalability results. One is clear, though, MariaDB Vector scales nicely and many concurrent connections can search the vector index in parallel significantly improving the throughput.
At the end, I want to reiterate — do not use ann-benchmarks as your only criterion when choosing a vector database, it has a very limited scope. First, it inserts all vectors from the train dataset then it searches for vectors from the test dataset. It does not try updates and deletes, it does not try concurrent vector index modifications, it does not try ACID, does not try hybrid searches where nearest neighbor vector search is combined with conditions on other columns and joins. It does test two basic characteristics of the ANN algorithm — how fast it can build a vector index for a given recall and how fast it can search with a given recall. And it does that fairly well. But it is absolutely not enough to make a decision of what vector search algorithm (or vector search database) will work best in your real-life application.