
This article first appeared in InfoWorld. It is reprinted with permission. © IDG Communications, Inc., 2020. All rights reserved How MariaDB achieves global scale with Xpand. Xpand is now available in MariaDB SkySQL adding distributed SQL for scalability and elasticity in the cloud.
As information and processing needs have grown, pain points such as performance and resiliency have necessitated new solutions. Databases need to maintain ACID compliance and consistency, provide high availability and high performance, and handle massive workloads without becoming a drain on resources. Sharding has offered a solution, but for many companies sharding has reached its limits, due to its complexity and resource requirements. A better solution is distributed SQL.
In a distributed SQL implementation, the database is distributed across multiple physical systems, delivering transactions at a globally scalable level. MariaDB Platform X5, a major release that includes upgrades to every aspect of MariaDB Platform, provides distributed SQL and massive scalability through the addition of a new smart storage engine called Xpand. With a shared nothing architecture, fully distributed ACID transactions, and strong consistency, Xpand allows you to scale to millions of transactions per second.
Optimized pluggable smart engines
MariaDB Enterprise Server is architected to use pluggable storage engines (like Xpand) to optimize for particular workloads from a single platform. There is no need for specialized databases to handle specific workloads. MariaDB Xpand, our smart engine for distributed SQL, is the most recent addition to our lineup. Xpand adds massively scalable distributed transactional capabilities to the options provided by our other engines. Our other pluggable engines provide optimization for analytical (columnar), read-heavy workloads, and write-heavy workloads. You can mix and match replicated, distributed, and columnar tables to optimize every database for your specific requirements.
Adding MariaDB Xpand enables enterprise customers to gain all the benefits of distributed SQL – speed, availability, and scalability – while retaining the MariaDB benefits they are accustomed to.
Let’s take a high-level look at how MariaDB Xpand provides distributed SQL.
Distributed SQL down to the indexes
Xpand provides distributed SQL by slicing, replicating, and distributing data across nodes. What does this mean? We’ll use a very simple example with one table and three nodes to demonstrate the concepts. Not shown in this example is that all slices are replicated.
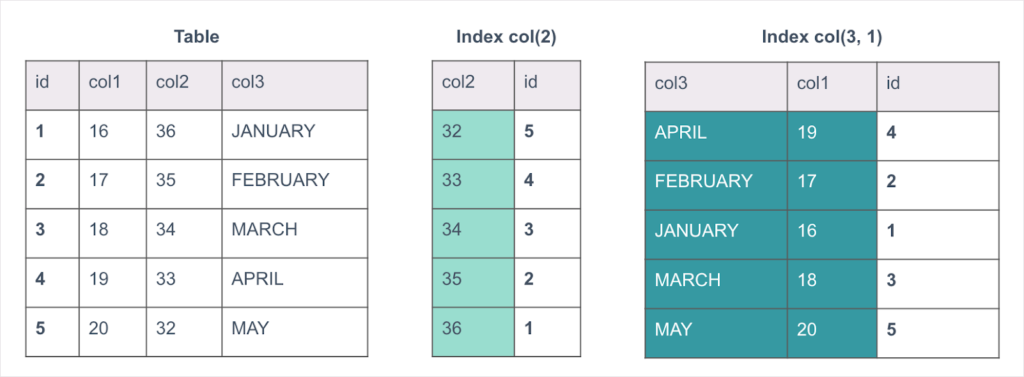
In Figure 1 above, we have a table with two indexes. The table has some dates and we have an index on Column Two, and another on Columns Three and One. Indexes are in a sense tables themselves. They’re subsets of the table. The Primary Key is id, the first index in the table. That’s what will be used to hash and spread the table data out around the database.
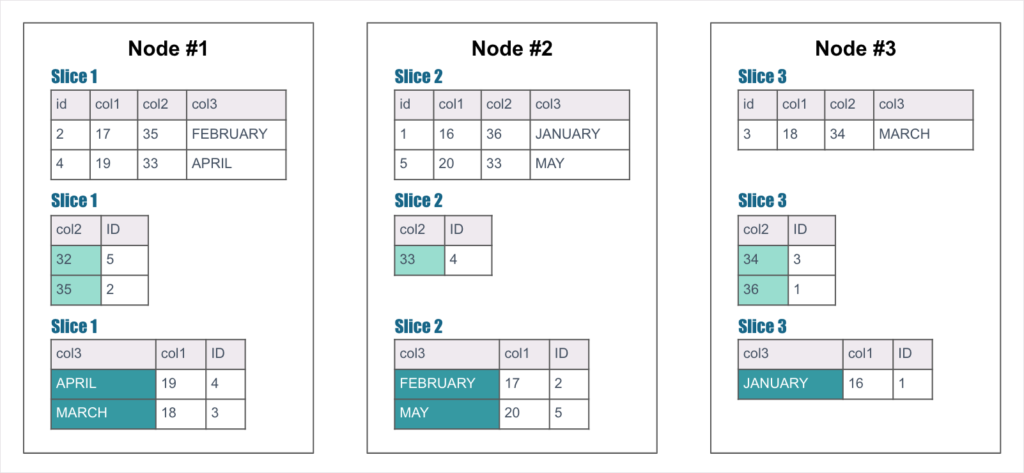
Now we add the notion of slices. Slices are essentially horizontal partitions of the table. We have five rows in our table. In Figure 2, the table has been sliced and distributed. Node #1 has two rows. Node #2 has two rows, and Node #3 has one row. The goal is to have the data distributed as evenly as possible across the nodes.
The indexes have also been sliced and distributed. This is a key difference between Xpand and other distributed solutions. Typically, distributed databases have local indexes, so every node has an index of its own data. In Xpand, indexes are distributed and stored independently of the table. This eliminates the need to send a query to all nodes (scatter/gather). In the example above, Node #1 contains rows 2 and 4 of the table, and also contains indexes for rows 32 and 35 and rows April and March. The table and the indexes are independently sliced, distributed, and replicated across the nodes.
The query engine uses the distributed indexes to determine where to find the data. It looks up only the index partitions needed and then sends queries only to the locations where the needed data reside. Queries are all distributed. They’re done concurrently and in parallel. Where they go depends entirely on the data and what is needed to resolve the query.
All slices are replicated at least twice. For every slice, there are replicas residing on other nodes. By default, there will be three copies of that data – the slice and two replicas. Each copy will be on a different node, and if you were running in multiple availability zones, those copies would also be sitting in different availability zones.
Read and write handling
Let’s take another example. In Figure 3, we have five instances of MariaDB Enterprise Server with Xpand (nodes). There’s a table to store customer profiles. The slice with Shane’s profile is on Node #1 with copies on Node #3 and Node #5. Queries can come in on any node and will be processed differently depending on if they are reads or writes.
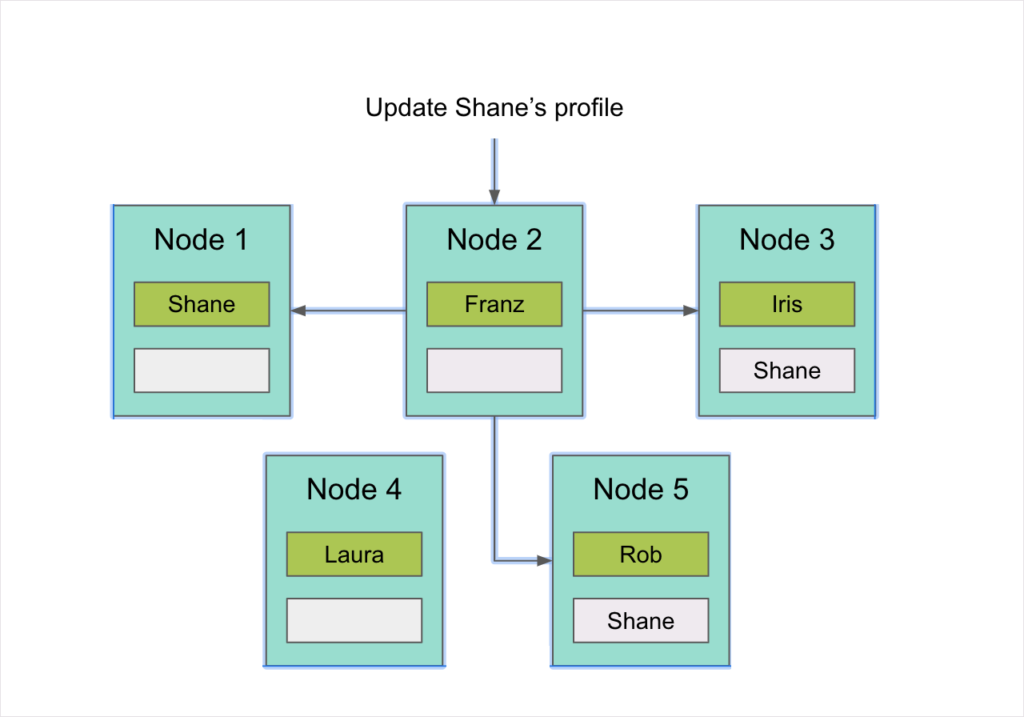
Writes are made to all copies synchronously inside a distributed transaction. Any time I update my “Shane” profile because I changed my email or I changed my address, those writes go to all copies at the same time within a transaction. This is what provides strong consistency.
In Figure 3, the UPDATE statement went to Node #2. There is nothing on Node #2 regarding my profile but Node #2 knows where my profile is and sends updates to Node #1, Node #3, and Node #5, then commits that transaction and returns back to the application.
Reads are handled differently. In the diagram, the slice with my profile on it is on Node #1 with copies on Node #3 and Node #5. This makes Node #1 the ranking replica. Every slice has a ranking replica, which could be said to be the node that “owns” the data. By default, no matter which node a read comes in on, it always goes to the ranking replica, so every SELECT that resolves to me will go to Node #1.
Providing elasticity
Distributed databases like Xpand are continuously changing and evolving depending on the data in the application. The rebalancer process is responsible for adapting the data distribution to current needs and maintaining the optimal distribution of slices across nodes. There are three general scenarios that call for redistribution: adding nodes, removing nodes, and preventing uneven workloads or “hot spots.”
For example, say we are running with three nodes but find traffic is increasing and we need to scale – we add a fourth node to handle the traffic. Node #4 is empty when we add it as shown in Figure 4. The rebalancer automatically moves slices and replicas to make use of Node #4, as shown in Figure 5.
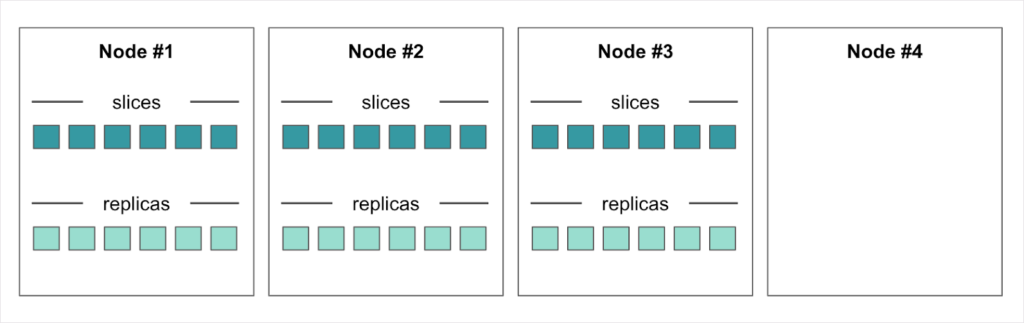
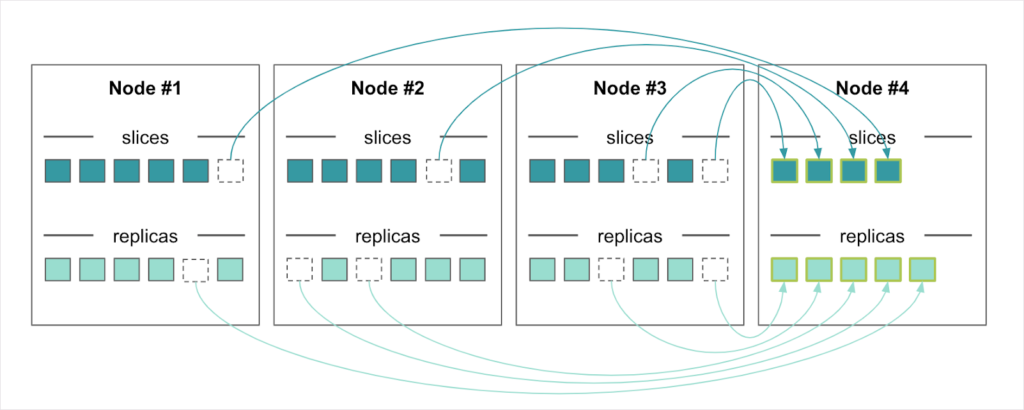
If Node #4 should fail, the rebalancer automatically goes to work again; this time recreating slices from their replicas. No data is lost. Replicas are also recreated to replace those that were residing on Node #4, so all slices again have replicas on other nodes to ensure high availability.
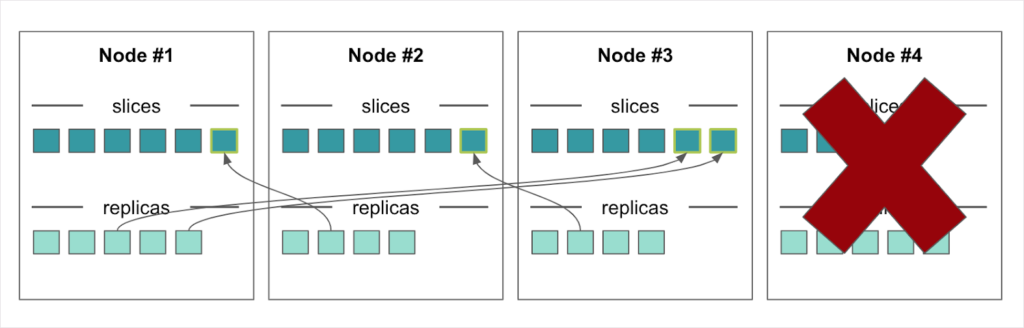
Figure 6. If a node fails, the Xpand rebalancer recreates the slices and the replicas that resided on the failed node from the replica data on the other nodes.
Balancing the workload
In addition to scale out and high availability, the rebalancer mitigates unequal workload distribution – either hot spots or underutilization. Even when data is randomly distributed with a perfect hash algorithm, hot spots can occur. For example, it could happen just by chance that the 10 products on sale this month happen to be sitting on Node #1. The data is evenly distributed but the workload is not (Figure 7). In this type of scenario, the rebalancer will redistribute slices to balance resource utilization (Figure 8).
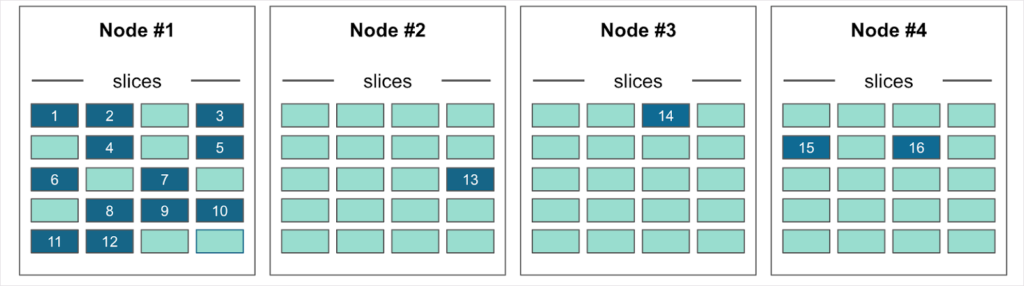 Figure 7. Xpand has evenly distributed the data but workload is uneven. Node 1 has a significantly higher workload than the other three nodes.
Figure 7. Xpand has evenly distributed the data but workload is uneven. Node 1 has a significantly higher workload than the other three nodes.
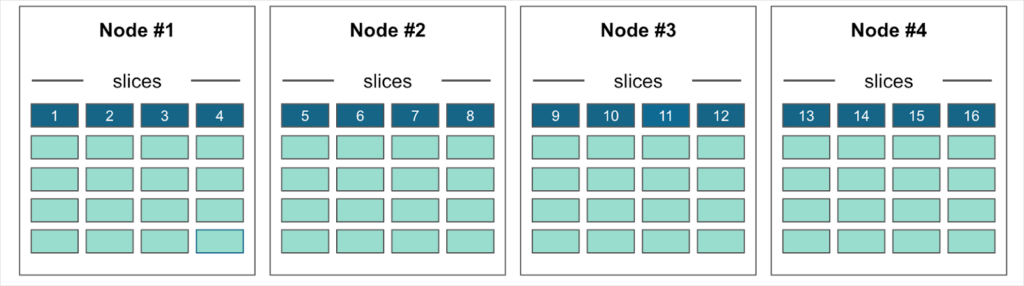 Figure 8. Xpand rebalancer redistributes data slices to balance the workload across nodes.
Figure 8. Xpand rebalancer redistributes data slices to balance the workload across nodes.
Scalability, speed, availability, balance
Information and processing needs will continue to grow. That’s a given. MariaDB Xpand provides a consistent, ACID-compliant scaling solution for enterprises with requirements that can’t be met with other alternatives like replication and sharding.
Distributed SQL provides scalability, and MariaDB Xpand provides the flexibility to choose how much scalability you need. Distribute one table or multiple tables or even your whole database, the choice is yours. Operationally, capacity is easily adjusted to meet changing workload demands at any given time. You never have to be over-provisioned.
Xpand also transparently protects against uneven resource utilization, dynamically redistributing data to balance the workload across nodes and prevent hot spots. For developers, there’s no need to worry about scalability and performance. Xpand is elastic. Xpand also provides redundancy and high availability. With data sliced, replicated, and distributed across nodes, data is protected and redundancy is maintained in the event of hardware failure.
And, with MariaDB’s architecture, your distributed tables will play nicely – including cross-engine JOINs – with your other MariaDB tables. Create the database solution you need by mixing and matching replicated, distributed, or columnar tables all on a single database on MariaDB Platform.