
MariaDB MaxScale
01 Introduction
MariaDB MaxScale is a next-generation database proxy that sits between applications and databases, providing a high-performance, scalable solution. This enables administrative database processes, such as security, load balancing, and streaming, to run without compromising performance, which is crucial in mission-critical applications. MaxScale also prevents external attacks with its advanced database firewall features, balances the load with its dynamic SQL-aware query router, and minimizes downtime with automatic failover. Additionally, it can stream transactional data for real-time analytics using messaging systems, such as Apache Kafka.
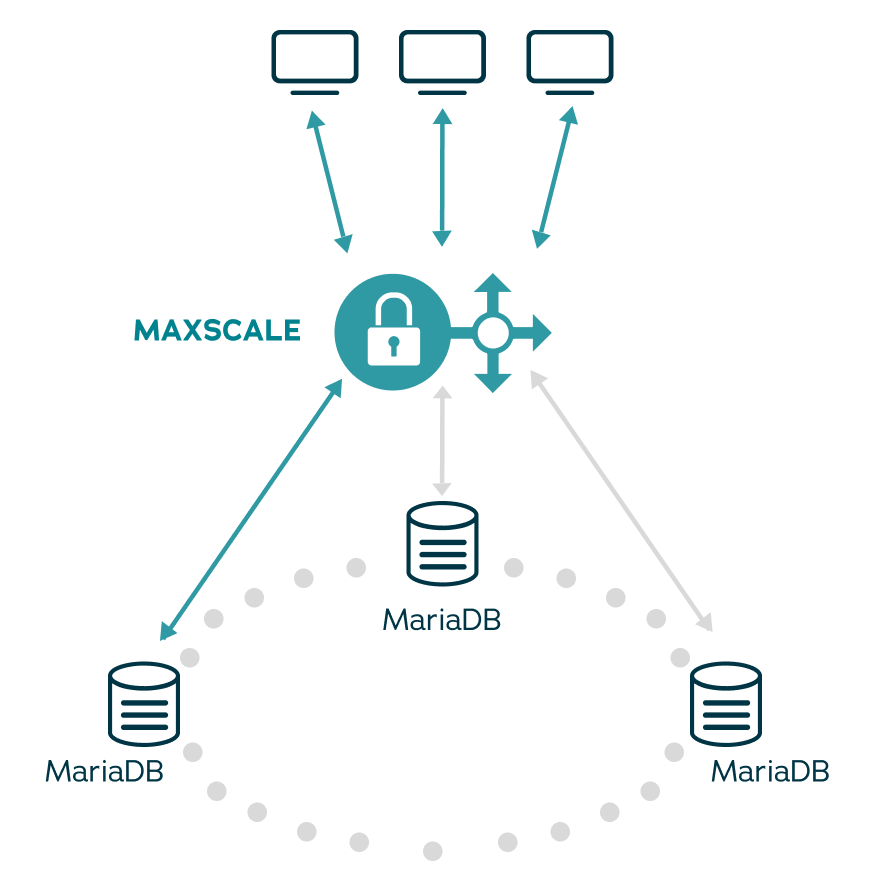
02 MaxScale Features
MaxScale delivers a range of features that combine to provide a secure, scalable, reliable environment while maintaining ease of use and monitoring. Key features include:
Firewall protection
MaxScale provides a database firewall that acts as a protective barrier, ensuring that only expected queries are allowed through. It learns the typical patterns of queries during a training period and then uses this knowledge to block any queries that do not match what it has learned. This helps safeguard the database from unauthorized access or potentially harmful operations.
High availability and automatic failover
MaxScale ensures unmatched performance and reliability with its robust high availability features. Automatic failover, transaction replay, connection migration and session restore work together to prevent service interruptions, providing a seamless experience for application users, regardless of infrastructure issues.
Scalability
MaxScale simplifies read scaling with its SQL-aware Read/Write Split Router, intelligently distributing queries for load balancing. Cooperative locking enables seamless scaling across multiple instances, ensuring high availability. These features make scaling accessible and straightforward, empowering all developers, regardless of their database expertise, to adjust environments as needed.
Security
MaxScale enhances database security through TLS encryption and query throttling. By limiting query frequency per session, MaxScale effectively prevents rogue sessions (client-side errors) and mitigates DDoS attacks.
Simplified database management
MaxScale provides a centralized platform for administrators to manage their database environments. Easily adjust configurations, perform topology changes (like replica management and failovers) and rebuild replicas with single-click convenience. Comprehensive monitoring is available through a robust web interface, and flexible testing tools (Workload Capture, Replay, and Diff Router) allow for analysis in test or production settings.
In addition, MaxScale seamlessly integrates with MariaDB Enterprise Monitor to provide a holistic view of your total database environment.
03 About MariaDB
MariaDB seeks to eliminate the constraints and complexity of proprietary databases, enabling organizations to reinvest in what matters most – rapidly developing innovative, customer-facing applications. Enterprises can depend on a single complete database for all their needs, that can be deployed in minutes for transactional, analytical and hybrid use cases. Trusted by organizations such as Deutsche Bank, DBS Bank and Samsung – MariaDB delivers customer value without the financial burden of legacy database providers. For more information, please visit mariadb.com.
Contact Us to Learn More About MariaDB MaxScale