
MariaDB Analytics
01 Introduction
In a data-driven world, the ability to analyze information as it’s created is a critical competitive advantage. Yet, many organizations are still hampered by the traditional divide between their transactional (OLTP) and analytical (OLAP) systems. Moving data via slow, complex and error-prone ETL pipelines results in stale data, architectural complexity and missed opportunities. You need a solution that can handle both seamlessly.
MariaDB Enterprise Platform offers robust solutions to break down the barriers to insight. Whether you need to run ad hoc queries on massive datasets or power the most demanding AI workloads, we provide your choice of two flexible and performant engines to meet your needs.
Two Analytics Engine Options:
MariaDB ColumnStore
A specialized storage engine for scalable, high-performance analytics without the need for complex schemas and indexes – distributed, columnar storage with parallel query processing.
MariaDB Exa
A high-speed analytics engine for the most demanding workloads, connecting live transactional data to a massively parallel, in-memory engine – purpose-built for real-time analytics and AI/ML.
02 MariaDB ColumnStore
MariaDB ColumnStore is a powerful columnar database that delivers fast, ad hoc analytics at scale. It can be deployed as a standalone analytics solution or integrated with MariaDB Enterprise Server to act as a powerful query accelerator. It stores data in a columnar format and can be distributed across a cluster of servers, allowing it to execute complex queries in parallel on petabytes of data.
This integration allows you to access your InnoDB data in near-real time, processing it directly in the ColumnStore engine to run fast, parallel OLAP queries straight from your transactional data. This eliminates the need to maintain a separate pipeline or use delayed batch inserts to analyze your live data.
Scale Query Performance, On Demand
Horizontally scale query throughput faster and more efficiently than ever before. Read-replica nodes utilize shared storage to let you add compute resources focused purely on query execution. This allows you to independently and rapidly scale performance to meet demand without needing to redistribute or reimport data.
Automated and Secure Upgrades
Our new upgrades architecture streamlines the entire process, automating nearly every step to save time and increase reliability. Integrated pre- and post-upgrade checks ensure the safety and integrity of your cluster throughout the upgrade process.
Enhanced Data Import and Error Handling
Streamline your data ingestion with new cpimport options. You can now choose to skip all errors to ensure large jobs complete, and automatically isolate any failed records into a separate file for easy review and reprocessing.
Integrated Cluster Management Tools
Essential management capabilities are now built directly into the core CMAPI toolkit. Orchestrate backup and restore operations and bundle logs for support with simple, standardized commands, making cluster administration faster and more efficient.
Ready for Modern Enterprise Environments
MariaDB ColumnStore is now fully supported on Red Hat Enterprise Linux 10, ensuring seamless integration into the latest enterprise operating system environments.
03 MariaDB Exa
MariaDB Exa unites MariaDB, a trusted database platform for mission-critical, OLTP workloads, with Exasol, the high-performance analytics engine for your most demanding analytics and AI workloads. Together, they enable you to analyze live operational data without compromising on speed or reliability.
This powerful combination excels in high-concurrency scenarios, allowing thousands of users to simultaneously access and analyze large amounts of data without compromising query performance. Whether you have many users running reports or a few users pulling massive datasets, the platform is engineered to deliver fast, consistent results.
Unmatched Performance for Real-Time Insights
Leverage MariaDB Exa for massively parallel, in-memory processing to analyze business events the moment they occur in your MariaDB applications, delivering 10x to 1,000x faster queries.
Eliminate Complex ETL and Simplify Your Architecture
Move beyond slow, brittle data pipelines. Our joint solution provides live access to MariaDB using Exa’s Virtual Schema framework, eliminating the need for separate ETL processes and intermediate staging areas, which radically simplifies your architecture and lowers TCO.
Power Your AI and ML on the Freshest Data
Move beyond batch predictions. Create a seamless connection between your MariaDB transactional data and Exa’s integrated AI/ML execution, allowing you to train and run models on live information.
Flexible Deployment for Any Architecture
Maintain complete control over your data strategy. The joint solution supports any deployment model, whether on-premise, in the cloud (including Microsoft Azure or Amazon Web Services), or as part of a hybrid cloud strategy.
Uncompromised Performance for All Workloads
MariaDB continues to deliver best-in-class transactional throughput while the analytics engine handles complex analytical queries, ensuring neither workload compromises the other.
04 How Do I Choose?
While MariaDB ColumnStore is ideal for intermittent analytic queries, MariaDB Exa is designed to deliver outstanding performance in an intensively analytical environment under heavy usage. If your users run analytical queries on an ad-hoc basis, ColumnStore may meet your needs. It is included as part of MariaDB Enterprise Platform and has been used for many years.
If your users regularly submit complex analytical queries, or your environment is under continuous heavy strain, MariaDB Exa may be the better choice. MariaDB Exa must be installed on an additional server or servers within your MariaDB environment. This means that the resources needed to run a complicated analytical query or to maintain acceptable performance under heavy load are offloaded from your MariaDB Enterprise Servers and instead handled by MariaDB Exa.
MariaDB Exa Architecture
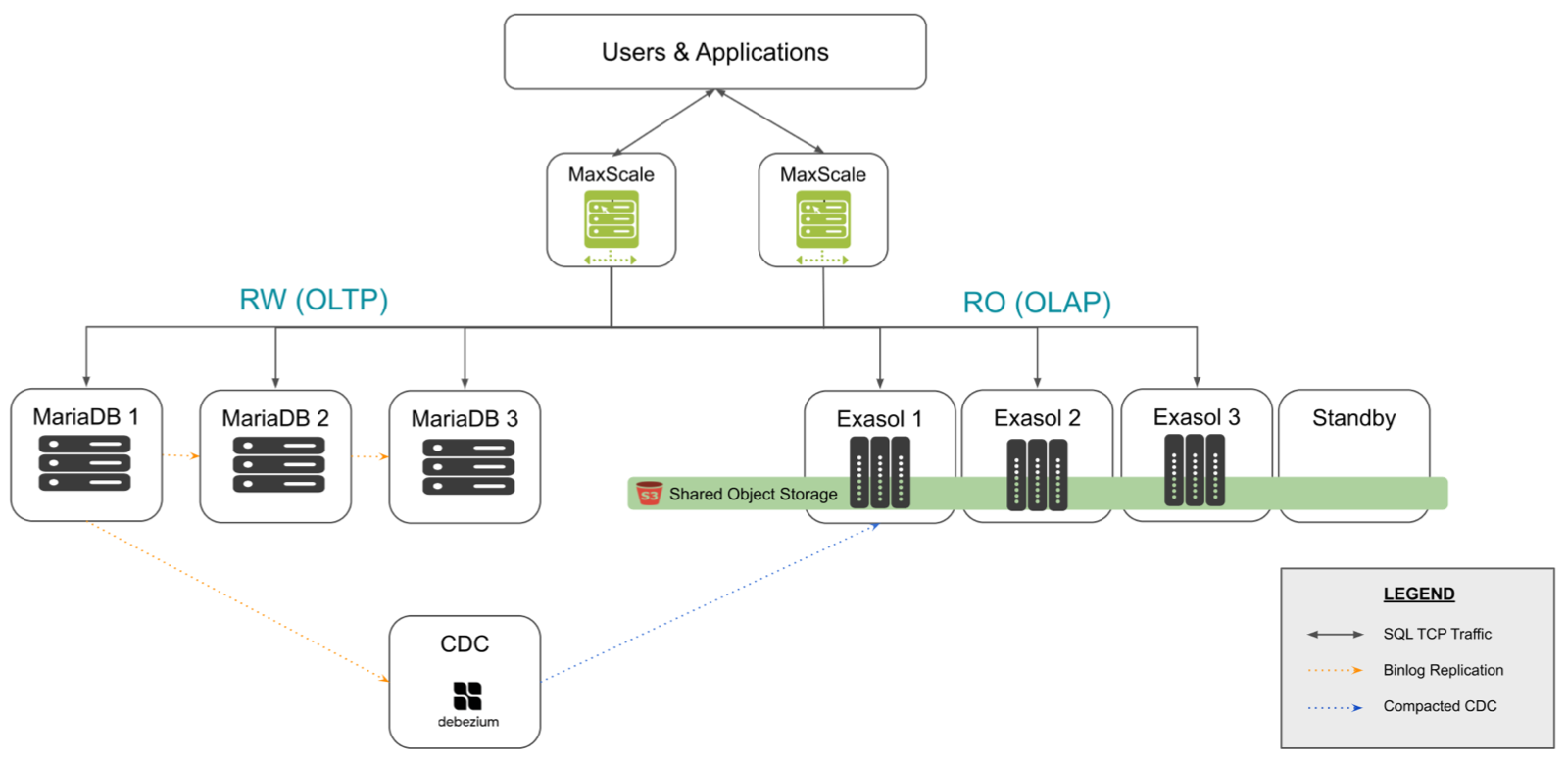
In this graphic, all write requests are routed to the MariaDB server side. Data is captured using binlog, processed through CDC, and then loaded into the Exasol servers.
Read requests are routed to MariaDB servers for transactional requests and to Exasol servers for analytical requests.
05 About MariaDB
MariaDB seeks to eliminate the constraints and complexity of proprietary databases, enabling organizations to reinvest in what matters most – rapidly developing innovative, customer-facing applications. Enterprises can depend on a single complete database for all their needs, that can be deployed in minutes for transactional, analytical and hybrid use cases. Trusted by organizations such as Deutsche Bank, DBS Bank, ServiceNow and Samsung – MariaDB delivers customer value without the financial burden of legacy database providers. For more information, please visit mariadb.com.
Contact Us to Learn More About MariaDB