
Parallel replication is a much-expected feature of MySQL. It’s available in MariaDB 10.0 and in MySQL 5.7. Yet, both lose efficiency when replicating through intermediate masters. In this post, we’ll explain how parallel replication works and why it does not play well with intermediate masters. We’ll also offer a solution (hint: it involves Binlog Servers).
In MySQL 5.5 and MariaDB 5.5, replication is single threaded: on a slave, the previous transaction must complete (commit) before the next transaction can start. This is not the case on a master where many transactions can make progress at the same time. The consequence is that a slave has less transaction processing capabilities than its master (for writes). This means that care must be taken to avoid loading a master with more writes than its slaves can execute. If this is not done well, the slaves will start lagging.
This single threaded implementation is disappointing:
- Year after year, servers get an increasing number of cores but only one can be used on slaves to apply transactions from the master
- MySQL (and its storage engines) gets better at using many cores but those improvements do not speed up replication on slaves
On the other hand, running transactions in parallel on a slave is not simple. If done badly, conflicting transactions could be run at the same time, which risks getting different results on master and slave. In order to be able to run transactions in parallel, a way to prevent that from happening must be implemented. For parallel replication in MySQL 5.6, transactions in different schemas are assumed to be non-conflicting and can be run in parallel on slaves. This is a good start but what about transactions in the same schema?
To provide parallel execution of transactions in the same schema, MariaDB 10.0 and MySQL 5.7 take advantage of the binary log group commit optimization. This optimization reduces the number of operations needed to produce the binary logs by grouping transactions. When transactions are committing at the same time, they are written to the binary log in a single operation. But if transactions commit at the same time, then they are not sharing any locks, which means they are not conflicting thus can be executed in parallel on slaves. So by adding group commit information in the binary logs on the master, the slaves can safely run transactions in parallel.
So far we have:
- The master identifying potential parallelism with group commit and making this information available to the slaves via the binary logs
- The slaves executing transactions in parallel using the information provided by the master
What happens when some of those slaves are intermediate masters? What kind of parallelism information will they pass to their slaves? To answer these questions, the first thing that needs to be highlighted is the fact that transactions committing together might have started at different points of time in the past. This situation is illustrated below where T1 and T2 started (B for begin) after T3 and T4, even if they are all committing at the same time (C for commit).
----Time----> T1: B---C T2: B---C T3: B-------C T4: B-------C
Because those transactions commit together on the master, they start together on the slaves but do not commit at the same time:
----Time----> T1: B---C T2: B---C T3: B-------C T4: B-------C
This will cause the group of 4 transactions from the master to be split into 2 groups of 2 transactions on slaves. This is not a big problem on leaf slaves but it is a major issue on intermediate masters. As an intermediate master will write those transactions as 2 commit groups in the binary logs, its slaves will not run 4 transactions in parallel but only 2 transactions at a time with a barrier between the groups as shown below.
----Time---------> T1: B---C T2: B---C T3: B-------C T4: B-------C
So, when using parallel replication (based on the group commit) with transactions of different execution times, the intermediate masters show less parallelism to their slaves than what is shown by their master. This is not only a supposition, this is clearly observed in our test environments.
To test parallel replication at Booking.com we set up four test environments, each consisting of a master and a slave, where each node is running MariaDB 10.0.16 (we’ve also done similiar tests with MySQL 5.7 and found results close to the ones you’ll see below). On each master, we run transactions from production and identify parallelism using group commit (more on the exact methodology in a follow up post). To monitor parallelism identification, the global status BINLOG_COMMITS and BINLOG_GROUP_COMMITS are checked regularly. The graphs below show the collected data (number of commits and group commits) for both master and slave in the four tests environments.




For the most part, the master and the slave are executing the same number of transactions (commits). But, the slave is executing more group commits than the master (less is better). If we divide the number of commits by the number of group commits, we get the average group commit size. Those are shown on the following graphs with the number of applier threads on the slave:


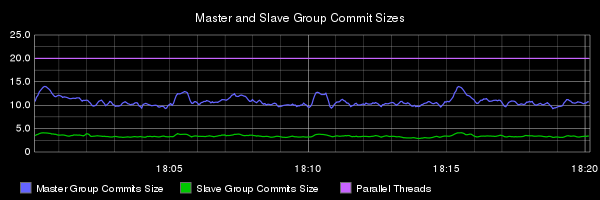

A smaller group size means that, if those slaves were intermediate masters, parallelism is lost when replicating through them. Looking at ratios, we can see how bad this is (slave divided by master, less than one for group commit means that the slave identifies less parallelism than its master). Note: we expect the commit ratio to be 1, as if it were not, the slave would be lagging.




This is very disappointing. In our test environments, using true production workload, intermediate masters divide the parallelism available to their slaves by at least 2 and sometimes by almost 4.
What can be done to improve that? Having all slaves replicating directly from the master could be a solution. But that would increase the load on masters. It would also be impractical for remote site replication because it consumes too much WAN bandwidth as we often have 50 and sometimes more than 100 slaves per site.
People that have read previous posts from this blog might have guessed the solution:
Replace intermediate masters by Binlog Servers.
(Reminder: a Binlog Server sends its slaves exactly the same binary logs it fetched from its master.)
By doing this, all slaves replicate using the same binary logs (the one from the master) and all slaves, either directly connected to the master or replicating from a Binlog Server, see the same parallelism information.
To take full advantage of parallel replication, and while intermediate masters are unable to offer this information to their slaves, intermediate masters must disappear! The tool that will allow us to do that at Booking.com is the Binlog Server.
If you’re interested in this topic and would like to learn more, I’ll be giving a talk about Binlog Servers at Percona Live Santa Clara in April. I am looking forward to meeting you there.
This is a repost from the booking.com blog Better Parallel Replication for MySQL.