
As one of MariaDB’s Enterprise Architects, one of the questions I get asked, for whatever reason is: do we need to backup the database? If so, isn’t one backup enough?
The answer is: YES, you need to backup your database and one backup is not enough. So in this blog, I am going to talk about what you need to consider when determining your disaster recovery and business continuity plan.
Backup and Recovery processes are a critical part of any application infrastructure – and this is no different for your database. A well tested backup and recovery system can be the difference between a minor outage and the end of your business.
Plan
There are three important considerations to planning your backup and recovery system. These are: Recovery Time Objective (RTO), Recovery Point Objective (RPO) and Risk Mitigation.
While Recovery Time Objective is basically how long it takes you to get back to business, a longer definition is: The amount of time that may pass during a disruption before it exceeds the maximum allowable time specified in the Business Continuity Plan.
Recovery Point Objective is how much data you can afford to lose. Frequently this is how long it was since the last backup. My Architecty way to say this is: the duration of time and service level within which a business process must be restored after a disaster in order to avoid unacceptable consequences associated with a break in continuity.
And then there is Risk Mitigation-What do you need to plan for? What failure scenarios are likely and how important is mitigating each of these scenarios. I would look at failure scenarios such as single and multiple instance, host or data center failure. You should also consider the risk of data corruption, loss or failure. Another common issue is ensuring you satisfy industry and legal regulations. These can include HIPAA, SOX, PCI and other compliance frameworks.
So when you go to design your system, consider the RTO, RPO and applicable risks. But not all data should have the same requirements. For example, an internal employee database could have a longer RTO than your customer facing product database. The cost of a one hour outage for your human resources department is small compared to not accepting orders for an hour.
Types of Backup with MariaDB
This blog is not a comprehensive list of ways to backup MariaDB, but I will mention the more frequently used methods.
Physical Backup
Physical, binary, or block-level backups typically refer to a copy of the data on disk. If you consider the MariaDB data directory, it could be as simple as shutting down the database and copying the data directory to a safe place.
Physical backups are most useful to mitigate host failures or to build replicas. Because they are generally byte for byte copies of the data on disk, they are much faster than other forms of backup – and much faster to restore. While this method provides for quick full recovery time, it is generally slower when trying to recover a single data point, row or table because it necessitates a full server restore before querying for the required data.
For a hot backup, MariaDB offers MariaDB Backup, a fork of XtraBackup, which itself is a fork of an older product. In general, MariaDB Backup creates a copy of the data directory and then applies storage engine transactional logs to make the backup consistent in the prepare phase.
Sample Commands:
[mdb-master]# mariabackup --backup --target-dir=/backup --user=root --password=X [mdb-master]# mariabackup --prepare --target-dir=/backup [mdb-restore]# scp –r mdb-master:/backup /backup/ [mdb-restore]# mariabackup --copy-back --target-dir=/backup/ [mdb-restore]# chown –R mysql.mysql /var/lib/mysql
Another way to do this is with storage level snapshots such as LVM, Virtual Machine, or cloud disk snapshots. The downside is that many times, these external methods take stronger locks on the database.
Logical Backup
Unlike physical backups, logical or SQL backups allow restoration of single database points fairly easily. Logical backups provide SQL files that contain data for regenerating a database from data.
These SQL files can be easily parsed with standard text tools. On Linux, for example, grep, less, sed, awk and other standard tools can be used to parse or manipulate the data before importing it. This means that the DBA can easily restore a single data point, row or table.
Another advantage of logical backups is that they are usually version agnostic and work across various versions of MariaDB and can even be used to import data from other relational databases.
This restore process is also automatically replicated because it is just a series of SQL statements. The disadvantage of logical backups is also that it is a series of SQL statements. That means that a full restore of larger databases is slower.
MariaDB offers mysqldump for creating logical backups. There are other open source tools out there as well such as mydumper which can do a logical dump in parallel. Sometimes, delayed slaves can also sometimes fit some of the logical backup use cases, but this should be evaluated carefully. I will cover delayed slaves in another blog.
Example commands:
[mdb-master]# mysqldump --triggers --routines --events --single-transaction --all-databases -r dump.sql [mdb-restore]# mysql MariaDB> source dump.sql
Choosing a Type
So which backup method should you choose?
Both.
Binary backups will address host failure and building replicas, while logical backups are more appropriate for scenarios such as data corruption and user error or where data is being migrated, obfuscated, or otherwise parsed prior to restoration.
Binary Logs and Point in Time
Binary Log backups, which are out of the scope of this blog, are essential to address RPO with Point in Time Recovery. Binary Log backups add complexity and increase recovery time due to more complicated recovery procedures – but they also give you a lot of flexibility in terms of recovery. I highly recommend looking into binlog backups or streaming. MariaDB MaxScale, one of the key technologies in MariaDB’s products, can also help with some use cases here.
Retention
So let’s say you now have multiple (and redundant) backups in place. What do you do with them?
One important consideration is protecting against node and data center failure. Counting on a single backup location is a risk. Backups are susceptible to corruption, user error, malicious users and the aforementioned node or data center failure.
If you want to cover all your bases, store up to a week worth of backups on the local server where the backup was taken, up to two weeks worth in the local data center and maybe a month of backups at a remote facility. Additionally, monthly or annual backups may be stored for years or forever. For some industries this may be overkill, for others, this is standard operating procedures and depends on business, legal and industry standards. Evaluate what works for you.
You should also consider storing copies of important data offsite. Cloud storage such as Google Nearline, Amazon AWS Glacier and others are good options. Other more traditional options also exist, such as vaulting and shipping drives or tapes (e.g. Iron Mountain). A DR (disaster recovery) site with file storage can also be used.
Recovery Testing
My best advice about recovery testing is: Don’t test your recovery at 3AM while your business is on the line.
Backups do not exist unless you are certain they can be recovered. An untested backup is a liability because it gives you a false sense of security.
A backup’s single purpose is to enable recovery following a disaster. Recovery procedures should be tested at least once a quarter–even better, every week.
Testing your backups regularly validates the correctness of your backups. Furthermore, if you do it right, you can collect some useful metrics like RPO and RTO. This means if there is downtime and a user asks, “How long until we are up and how much data will we lose?” you can refer back to your last test and have a fairly accurate guess.
When testing, be sure to test the accuracy of the restored data. Look for errors and that the dataset is correct with smoke test queries, data size and checksums.
Other Considerations
Security
If security is important to the database itself, it is also important for the backups. Ensure that your at-rest encryption extends to the backups. MariaDB Backup provides simple methods to stream backups straight into standard encryption and compression tools. mysqldump can also do this.
mariabackup --backup --stream=xbstream | openssl enc -aes-256-cbc -k mypass > backup.xb.enc
If your data is in a secure environment, encrypt it when it leaves that secure environment and in transit. This is even more important for offsite backup locations.
One of the downsides of encrypting your backups is that it will take longer to run the backup itself – it will also take longer to recover, so factor this into your RTO calculations. Encryption also adds complexity, which introduces more vectors for user error or automation problems. This could cause issues during disaster recovery.
Even worse, if you lose encryption keys or passwords, you could render your backups useless in a failure scenario.
Incremental and Differential Backups
MariaDB Backup offers a few flags to allow incremental and differential backups. There is currently not an easy way to do this for logical backups.
A differential backup records differences since the last full backup. For example, suppose you do a full backup on Sunday. Each day, this changeset grows as you compare it against Sunday’s backup. Incremental backups also backup only the changed data, but they compare it against the last backup – whether that is full, differential or incremental.
This method of backups can save on storage and provide for faster daily backups. But there is risk associated with both these methods, especially with incremental. If you are doing incrementals each day and have a failure on Friday, but Monday’s incremental is corrupt, your only choice is to go back and use Sunday’s backup. This would mean a whole week of data has been lost.
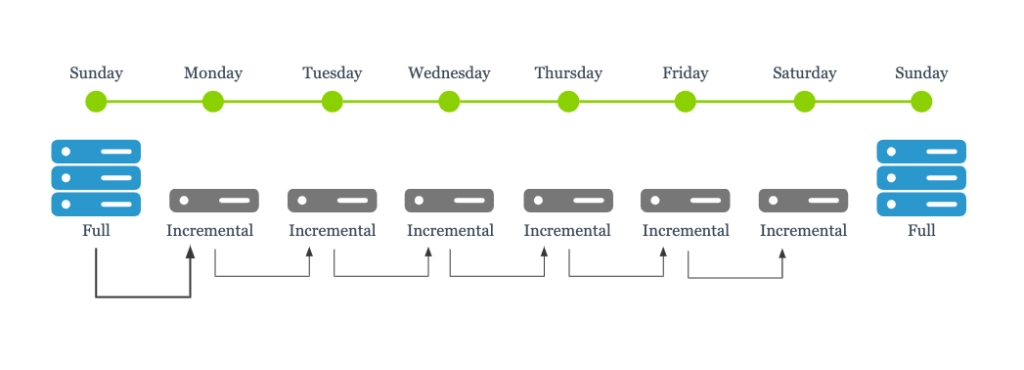
Another downside of this method is that while it does provide faster backups, it negatively affects your RTO as you must first restore the full backup and then each applicable differential or incremental backup.
Monitoring
Just like with your databases, monitoring backups is also important. It is important to verify the backup happened and how fresh the backups are. Automated recovery tests could also alert when RTO has exceeded required parameters.
Capturing this information also allows an organization to monitor how long backups take, when they start and stop, system impact of backups and their size over time.
Conclusion
While there are a lot of considerations when designing a resilient system for business continuity, take Recovery Time Objective, Recovery Point Objective and Risks into account.
Keep these in mind as backups are scheduled, stored and tested. Disasters have occurred even for the largest of players, such as Amazon. Having good procedures in place will ensure disaster doesn’t mean the end of your business.