

Hello, MariaDB community! My name is Pieter Humphrey, and I recently joined the Developer Relations team at MariaDB – a team that focuses on helping developers to succeed with data. We create content like blog posts, technical articles and videos, appear at conferences, write sample applications, and participate in the community in a variety of ways. I look forward to serving you and highlighting community accomplishments in person and online!
With the exception of frontend engineering and UI design, after 20+ years in information technology, I believe that the hard problems are “shifting right” – ever further into data and analytics. That’s not to say that this “shift right” philosophy correlates 100% with revenue, market, or mindshare – it’s my belief about where innovation is and learning opportunities are.
Cue the current generative AI (GenAI) wave sparked by large language models.
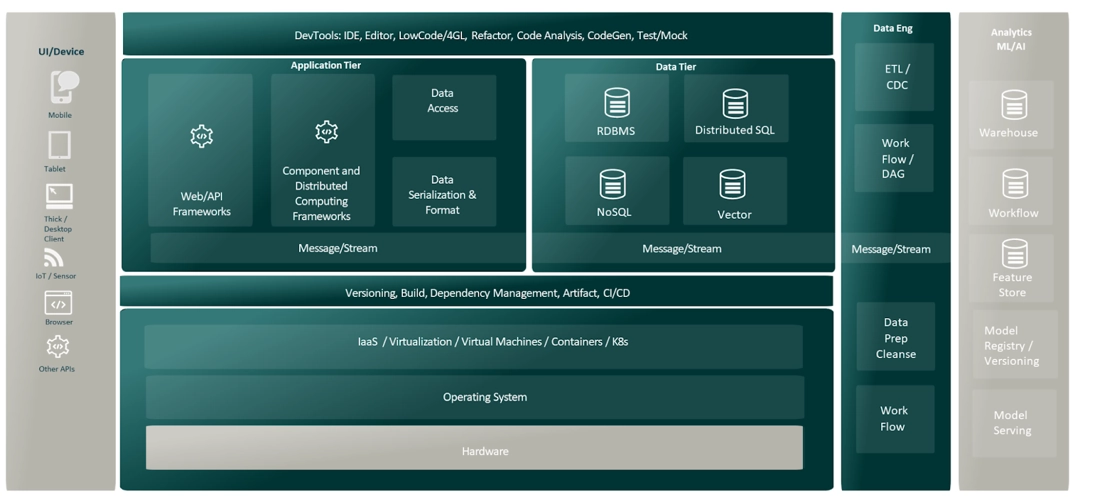
Having worked with technologies featured in the green areas of the above diagram for 20+ years, I’ve watched backend application development make the shift to include distributed architectures like SOA and microservices. Yet, in that same time frame, I feel that data and analytics has changed more dramatically relative to backend application development. New DBMS types, data models and network wire transmission modes arrived along with distributed file systems and cloud object storage. The very notion of the file system a database rests on has been reimagined and reimplemented. My first glimpse beyond operational RDBMS data started with ETL, CDC, and then messaging, queuing and pubsub middleware. Then big data and NoSQL arrived along with streaming. Data was beginning to distribute across process and network boundaries more and more, not just apps.
Having experience working at Oracle Middleware (coherence key-value), Elastic (JSON document) and DataStax (NoSQL wide-column) gave me the fundamentals for distributed data and NoSQL. However, none of these solutions can really provide a workable SQL developer interface, and they often imply compromise with consistency/availability/performance for the application developer.
I was part of the first wave of application server infrastructure with Java EE for 7+ years, and the Spring Framework team for 7+ years, which gave me a deep understanding of the application development process, backend developers, and later, distributed application development. This is why I believe that distributed SQL is the future for operation data: developers can code like a monolith, yet scale like a cloud. It offers the best set of CAP theorem compromises for general purpose operational data use cases by providing ACID-level consistency, high availability across network boundaries, and the best possible performance. Also, there is a potent incentive to bring analytics as close as possible to the operational system, as HTAP/Augmented Transactions and Operational Analytics have shown. Web/Mobile apps and APIs are now the “point of sale” systems in modern digital business.
Earlier, I set aside frontend development and UI/UX design as an exception to the challenges of shifting right. Frontend development is indeed difficult, and in retrospect, one that is easy to trivialize. It’s a great opportunity to cite one of my favorite Tweeple:
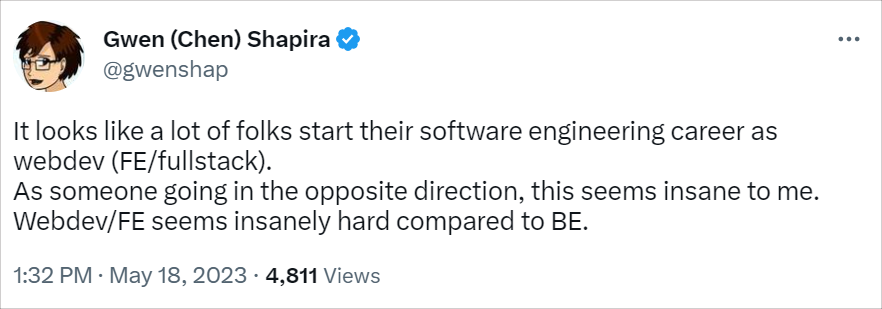
Good application-level UX is a unique talent in this industry. I can’t recall another role I’ve seen that brings together the same breadth of right/left brain and soft/hard skills – together with design. Those designs must also cope with a wide range of experienced and inexperienced users. Aspirants must learn some amount of HTML, CSS, and JavaScript to get anything done, at least on the web. For example, client (native) UI toolkits like SwiftUI, WinUI or Swing/AWT in Java arguably have less moving parts and less fragmented programming models, but then you have an OS compatibility matrix to consider. As one of the replies to the above tweet mentioned “I’m always surprised the web works.” Massive respect to the UX, one of the reasons why I’m so grateful to be working with people like Alejandro Duarte who has a ton of Vaadin experience.
Looking forward to working with, and learning with, the community!
You can reach me at:
https://twitter.com/PieterHumphrey
https://www.linkedin.com/in/pieterhumphrey/
https://www.infoq.com/profile/Pieter-Humphrey/