MariaDB Enterprise Cluster is an open source active-active, multi-primary synchronous replication solution for MariaDB Enterprise Server. In combination with MariaDB MaxScale, it provides high availability, scalability and automated failover for mission-critical transactional workloads. Enterprise Cluster provides parallel replication and data consistency across all nodes, automatically managing the identification and removal of failed nodes, as well as recovering and rejoining new nodes. With Enterprise Cluster, there’s no chance of lost transactions, significant replica lag or client latency.

Why Choose Enterprise Cluster
Fault tolerance
If one or more MariaDB Enterprise Server nodes fail, the remaining nodes continue to operate and failed nodes are automatically taken offline, repaired and reintroduced into the cluster – all without intervention from the application level.
Multi-master
While MariaDB Enterprise Platform primary/replica topologies with MaxScale optimize for read-intensive applications, MariaDB Enterprise Cluster is multi-master – all nodes accept write and read operations and synchronize to ensure data consistency across all nodes.
Geographically distributed data
Replicated nodes can be placed across a wide area network (WAN), and combined with asynchronous replication, will improve performance and reduce response times for end-user web services.
Customer Stories


High Availability Options with Enterprise Cluster
Multi-Primary Cluster and Automatic Failover
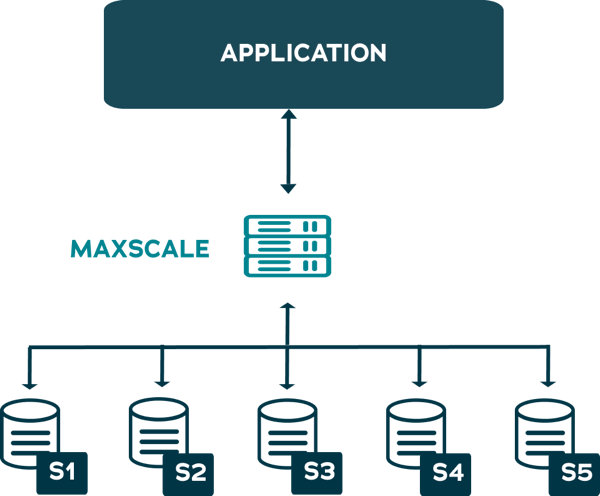
In the example topology below, a mission-critical transactional workload is supported through MariaDB MaxScale, Enterprise Server, and Enterprise Cluster, which consists of five database nodes and MariaDB MaxScale to facilitate front-end load balancing and automatic failover. This is an example of a multi-primary installation.
When a write request is submitted, MaxScale routes it to any of the servers. In this example, the write request is sent to S2. S2 accepts and processes the write, then replicates that write request to S1, S3, S4 and S5. Once acknowledgement is received from all servers, the write request is acknowledged to the application.
If one of the servers fails, it is removed from the cluster, and write and read requests are no longer submitted to it. This node failure does not impact the application.