
The goal of this article is to provide a high level description of what it means to be a distributed SQL engine, and a few different approaches to how distributed SQL engines process queries, and how that impacts performance and scale.
First, given our blogs are written for both MariaDB Server and MariaDB Xpand audiences, we should specify what we mean by our use of the term database engine in this entry. In the context of MariaDB Server, the term engine sometimes refers to the database kernel, while at other times it refers to individual storage engines. For the purposes of this blog, however, our reference to the database engine represents the database kernel, which powers your RDBMS to allow you to efficiently create, read, update, and delete (CRUD) data. To that end, a distributed SQL engine is a RDBMS that leverages multiple database servers to process queries, while maintaining the guarantees of a traditional RDBMS (transactions, ACID properties, foreign key integrity, etc).
Some benefits of distributed SQL databases include:
- Distributed SQL engines provide scale-out performance. As your business grows, adding capacity to your database becomes much simpler.
- Distributed SQL engines guarantee transactional consistency across all servers – the complications of handling distributed transactions across multiple servers, while maintaining data integrity is handled by the database engine
- Fault tolerance – since the database is distributed over multiple nodes, distributed sql engines often feature built-in data redundancy and some measure of fault tolerance.
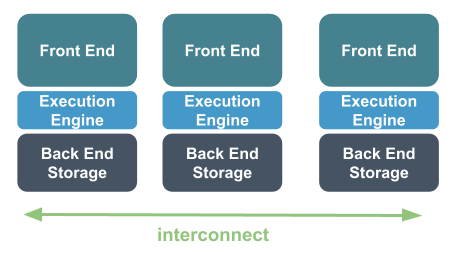
Now even though distributed SQL engines have many things in common, their architecture can differ. Before we dive into some of those differences, here is a short primer on some of the common components of a database system. I’ll let the picture do the talking:
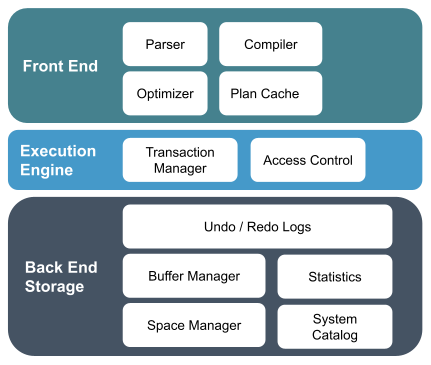
Now when it comes to distributed SQL database engines, the picture above changes. Here are a few different approaches to scaling your database horizontally, including some that attempt to address scalability limitations of single node systems, but do not scale to the levels of a truly distributed database.
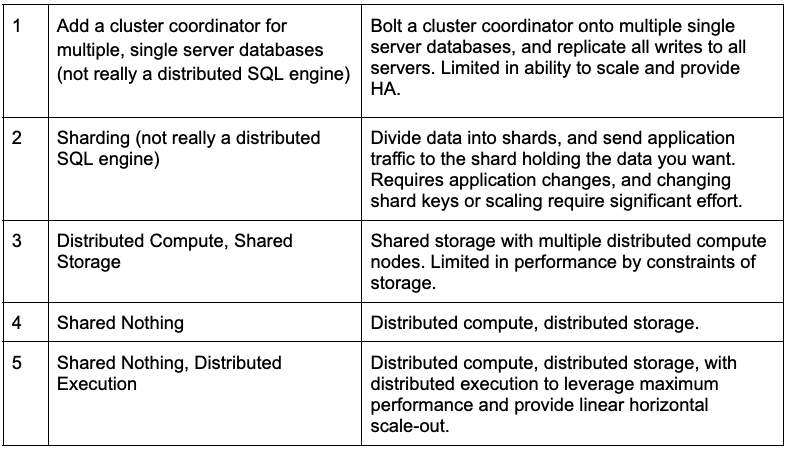
Approach #1: Add a cluster coordinator for multiple, single server databases.
This solution involves leveraging multiple instances of a single-server database via sharding, or replication (asynchronous or synchronous).
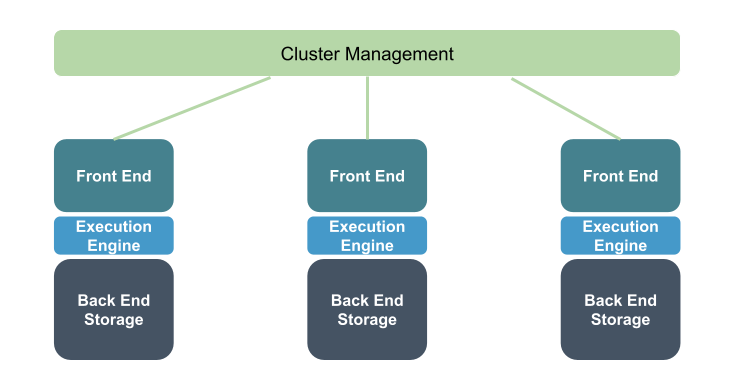
Each server holds a full copy of the data, and by being able to leverage multiple servers, there are some additional resources to serve your workloads, particularly for reads. There is a single cluster manager that handles traffic to the different servers (which itself can end up being a bottleneck, or single point of failure). Each additional server incurs additional write overhead, so ability to scale is limited. This isn’t a distributed SQL engine per se, but was one of the early ways people attempted to add scale.
Approach #2 Sharding your Data
When you shard your data, you divide your data into shards, based on a shard key that determines which data goes to which server. This also isn’t really a distributed SQL solution, but shares some of the same characteristics (a database that spans multiple servers). When you shard, your application then needs to be aware of where the data lives, so it can send queries to the appropriate server(s).
This works well for use cases where there is a high degree of isolation in your data, and no need to query across keys or shards. However, if your data set grows or becomes imbalanced, you will need to add additional shards or modify your shard key, and make sure your application code is modified at the same time. Sharding carries an overhead of ongoing refactoring, ongoing data balancing, and ongoing maintenance for each shard. You lose the ability to run cross-shard transactions or maintain consistency across shards. Getting a consistent backup across shards is very difficult.
Approach #3 Shared Storage
Another common approach leveraged by cloud vendors is to deploy multiple database instances that share the same physical storage. This is presented with a unified interface, where queries can be sent to any of the front end nodes, which access data stored in the underlying shared storage. This is one of the easiest ways to add clustering to an existing database engine.
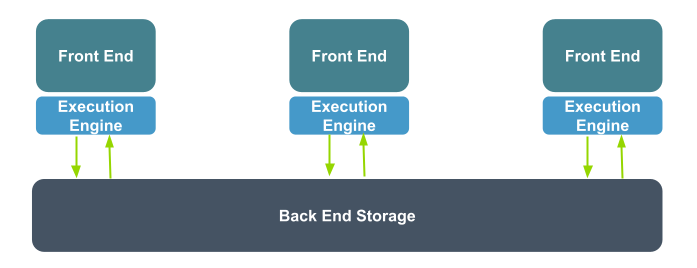
Distributed SQL Engine with Shared Storage
Most of the database stack remains the same. You have the same planner/optimizer, the same query execution engine, and they work independently to add capacity to your workload. Adding more processing power to the database is possible by adding nodes, and data access is transparent to the application layer. There is some measure of fault tolerance available, since front end nodes can be replaced easily.
For applications that require higher scale, this approach is limited by what the back end storage can provide. As the number of cluster nodes increases, so does coordination overhead. While some workloads can scale well with shared disks (small working sets dominated by heavy reads), many workloads do not, especially heavy write workloads.
Here is a comparison using TPC-C with 10k warehouses, of Xpand vs one commonly used distributed cloud database that leverages the shared storage model:
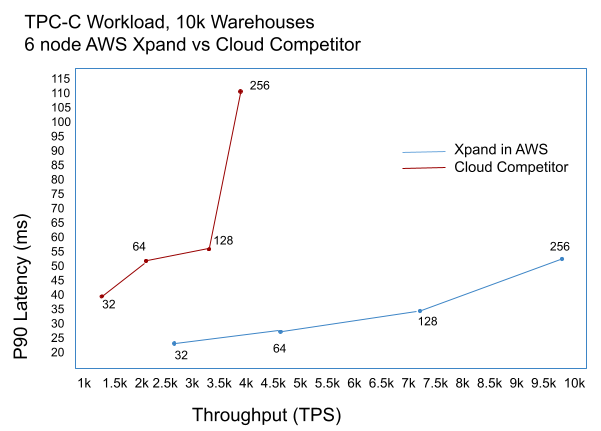
Limits of a Distributed SQL Database with shared storage
The Xpand throughput is 2.5x that of the cloud competitor, and is able to scale past 256 terminals, where the cloud competitor is not able to keep up. Xpand’s latency is also less than half what the cloud competitor was able to provide. During this test, Xpand still had additional headroom available during the 256 terminal test, so could have scaled further.
Approach #4 Distributed compute, shared nothing
The most scalable approach is with a shared-nothing architecture, where no server can serve as a single point of contention, and there is no single point of failure. With a distributed storage model, data is no longer shared between the nodes at a page or block level. Queries are sent to each node, which access their individual storage to execute queries.
Xpand accomplishes this by splitting tables and indexes into slices (what Xpand calls its unit of data, similar to a shard), and distributing them across the cluster. Xpand features an automatic Rebalancer which runs automatically in the background, to ensure that data is evenly distributed, and that the requisite number of copies of all data are available (to ensure fault tolerance).
For more details, see Data Distribution and Rebalancer.
#5 Taking Distributed SQL to the next level – Distributed Execution
Xpand’s data distribution scheme sets the stage for its unique execution model, where it applies distributed computing principles to SQL query optimization + execution, and achieves next level efficiency, concurrency, and scale. At the core of Xpand is the ability to execute one query with maximum parallelism, and many simultaneous queries with maximum concurrency. Xpand was designed from end to end to maximize parallelism, and that affects all parts of the stack – from the query compiler all the way down to on-disk storage.
Here are a few ways that plays out:
Compile SQL into fragments
Xpand implements a compiler that takes SQL statements and compiles them into distributed programs that can be executed across the cluster. During compilation, queries are broken down during compilation into fragments, which are basically machine code with a rich set of operations they can perform. They can read, insert, update a container, execute functions, modify control flow, format rows, perform synchronization, and send rows to query fragments on other nodes. Many, many query fragments can operate simultaneously across the cluster. Those query fragments may be different components of the same query or parts of different queries. The result is the same: massive concurrency across the cluster that scales with the number of nodes. Xpand does its own distributed scheduling of fragments to cores on each node, i.e. a thread-per-core model of execution. Each fragment runs to completion without pre-emption. This leads to high concurrency and maximum resource utilization. This is a key reason why Xpand’s scalability is unsurpassed.
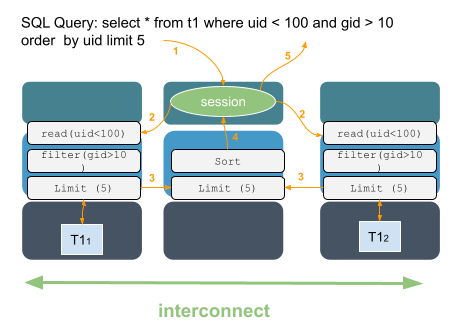
“Send the Query to the Data”
One of the fundamental ways that Xpand is able to scale linearly as nodes are added is its ability to “send the query to the data”. Other RDBMS systems routinely move large amounts of data to the node that is processing the query, then eliminate all the data that doesn’t qualify based upon the query. This is often LOTS of data! Xpand is able to reduce network traffic by only moving qualified data and partial results, such as aggregation, to the requesting node. Processors on multiple nodes can additionally be brought to bear on the data selection process. Instead of a single node having to gather information from multiple nodes, Xpand is able to select data on multiple nodes in parallel.
This illustrates how Xpand can parallelize processing, and leverage multiple nodes to execute a query. SQL statements can be sent to any node, and Xpand will automatically determine an optimal distributed query plan, and execute leveraging multiple nodes.
Similarly, other distributed computing principles (MVCC, two phase locking) are applied to Xpand’s execution engine to scale joins, implement a distributed lock manager, and ensure consistency in a distributed environment. All of this happens without the application needing to be aware of data placement or cluster size.
Conclusion
There are different flavors of distributed SQL engines, and varying levels of how much storage, compute, and execution are distributed, resulting in varying levels of scalability and performance. Many distributed SQL engines still borrow components from traditional monolithic databases, or are confined to execution environments that do not allow sufficient concurrency.
Overview of the various approaches to distributing a database across multiple servers:
Xpand was purpose-built from the ground up for scale with a shared nothing architecture that features:
- Automatic data distribution via the Rebalancer, to ensure that data is evenly distributed across the cluster, with multiple copies to ensure fault tolerance
- Distributed query evaluation that “brings the query to the data”, to avoid shipping rows around to perform JOINs and other operations
- Distributed query execution that leverages the principles of distributed computing to achieve maximum parallelism and performance.
To get started:
- Xpand 6.1 is now available in SkySQL, get started here
- Try Xpand on Docker
- Check out the Xpand documentation
- Contact us