
Arguably, one of the key motivations for using a managed DBaaS is its availability characteristics. But, did you know that Applications using AWS RDS (MySQL/MariaDB) often experience outages? If the primary database in a replicated configuration fails there is a good chance that the app connections break and you will experience an outage that can take over 2 mins to heal.
In this post we compare the failover process in RDS with MariaDB SkySQL and describe the crucial role our smart proxy (MaxScale) plays in delivering continuous availability with instant failover.
The failover process in RDS
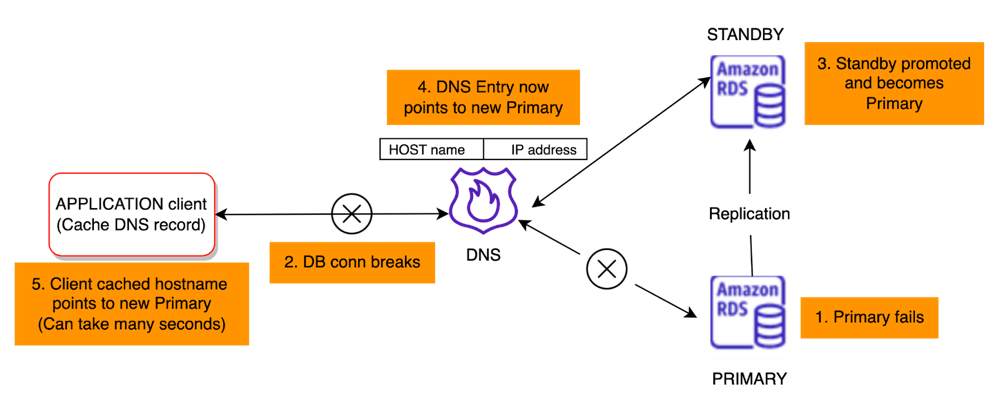
In MariaDB, MySQL, and Postgres databases, writes are sent to a primary instance, which is then replicated to one or more redundant replicas. To achieve high availability (HA) in RDS across different Availability Zones (AZ), the “multi-AZ” standby instance must be configured. This instance is launched in a different availability zone and maintains a copy of the data, but it is purely a standby that cannot be accessed by the application for reads or writes – an idle instance with the same capacity as primary you are paying for. Application clients directly connect and work with the primary instance, which is offered as a DNS endpoint URL that is resolved by the application client driver to the target IP address of the primary.
When the primary instance fails, RDS detects the failure and initiates promotion of the standby instance to become the new primary. This process takes time (well over 2 minutes in our experience) and varies depending on the nature of the failure. For instance, if the failure was due to a network event like network segmentation, the detection is much slower than when the node suddenly crashes. This results in all application client connections dropping, causing a brief outage. Existing database connections are disrupted, and the application must reopen them.
RDS uses a DNS-based approach to handle failover, where it updates the DNS record to point to the new primary instance when a failover occurs. However, most clients use DNS caching to avoid doing DNS lookups for every interaction. The DNS is configured with a Time-to-live (TTL), so the client initiates DNS resolution periodically. As there is no way for RDS to enforce what a client does, this mechanism assumes that all clients honor the TTL configured by RDS, which often becomes a headache for application developers trying to resolve DNS issues.
The graphic below depicts this process of failover.
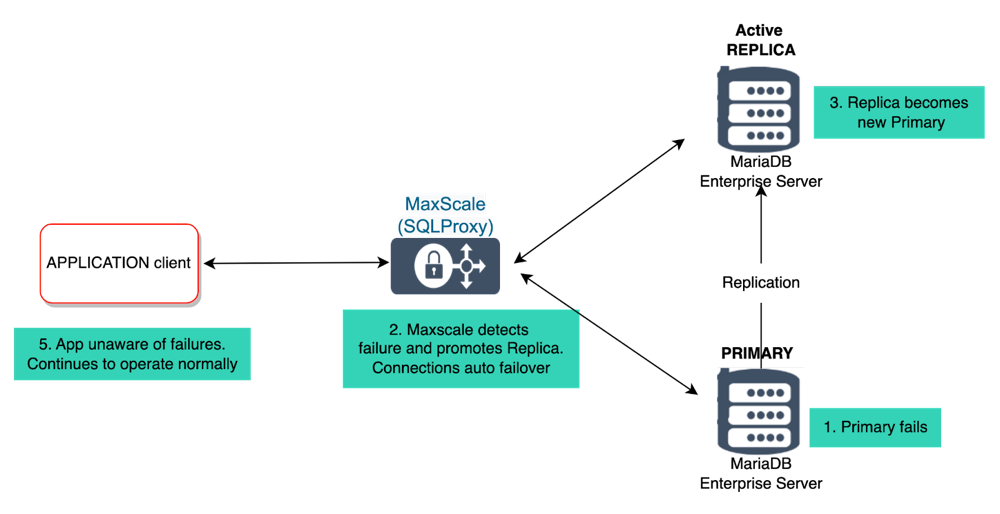
Failover process in SkySQL
The architecture for failover in SkySQL is quite different from that of AWS RDS. Any deployment with replicas transparently launches MaxScale – an intelligent data proxy. With MaxScale, all replicas are always active and accessible to readers, which allows for load balancing of reads across multiple replicas and reduces the load on the primary. When a primary fails, SkySQL is able to quickly detect the failure and orchestrate the election of a new primary while ensuring continuous availability and minimizing interruptions to the application. And, MaxScale itself is designed to be highly available running across zones.
One of the key challenges during the failover process is ensuring data consistency for transactions that were in progress when the primary failed. To address this, SkySQL uses transaction replay to automatically cache and replay transactions on the newly elected primary with idempotency, ensuring data consistency. Meanwhile, readers on replicas continue to remain operational, ensuring uninterrupted reads.
Since application clients never directly connect to the instances in SkySQL, application connections remain open and functional during the failover process, eliminating the need for DNS-based failover mechanisms and avoiding potential DNS caching issues. This provides a more seamless and reliable failover experience for applications.
Well, how can one avoid primary failures in the first place?
While hardware failures can happen, lack of resources is often the most common cause of database failures. Rogue queries that require a larger temporary buffer exceeding available capacity or sudden bursts in writes due to data loads or online schema changes can perpetuate the problem.
With RDS, resources becoming exhausted can be detected and appropriate alerts can be raised, but timely corrective measures require the application developer or administrator to catch and react quickly.
SkySQL offers three major features that reduce the probability of primary failures:
- Load balancing with Maxscale read-write splitting: With active replicas available, readers are automatically load-balanced across replicas, reducing the load on the primary. SkySQL exposes read-only ports to the application so complex reporting-class queries can always be delegated to a replica. A replica failing potentially only impacts the query latency, not availability.
- Auto scaling compute and storage: With SkySQL, users can turn on auto scaling of compute vertically or horizontally. For instance, a primary instance with 8 cores and 32 GB of memory could be auto-scaled to 16 cores and 64GB. SkySQL proactively detects changes in resource utilization and carries out this upgrade completely transparently and with no impact to readers or writers. Likewise, if the application workloads tend to be read-intensive, the cluster could be horizontally scaled with more read replicas.
- Delegating complex queries to serverless compute: If an application performs analytical queries and/or the data set is large, the SkySQL Serverless Analytics service can be turned on to run the complex analytical queries. This service auto-registers the catalogs of the MariaDB databases, enabling zero-ETL analytics on operational databases. When complex queries run, compute capacity is borrowed just when required without creating any load on the primary (or replicas, for that matter). In RDS, data would need to be periodically extracted and loaded into a warehouse like Redshift.
How about using proxies in RDS?
RDS does offer a managed database proxy that can potentially reduce failover times by automatically connecting your application clients to a standby database, but there are some limitations. Firstly, as of July 2022, the RDS proxy does not support the newer versions of MariaDB (10.6 or newer minor versions). https://aws.amazon.com/about-aws/whats-new/2022/07/amazon-rds-proxy-mariadb-version-10-support/
Secondly, the RDS proxy lacks intelligent read-write splitting/routing, transaction replays, and other features that are available with MaxScale in SkySQL.
In addition, setting up RDS proxies requires careful planning of VPC subnets and IP capacity, which can add to the complexity of your deployment(https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/rds-proxy-setup.html). Finally, while RDS proxies are available in multiple availability zones, it is not clear how they maintain consistent state across zones to ensure consistent failover or failback.
In contrast, SkySQL permits redundant MaxScale to operate across zones and uses its own replication to ensure correctness in the presence of proxy-level failures. Additionally, MaxScale in SkySQL has more advanced features such as automatic transaction replay and load balancing, which can help reduce the likelihood of primary failures in the first place.
Why does all of this matter? The differences in the architectures of SkySQL vs RDS lead to a difference in the monthly uptime SLA.
- MariaDB SkySQL foundation tier guarantees an SLA of at least 99.95% or a monthly downtime of 21m, 44s
- MariaDB SkySQL power tier guarantees an SLA of 99.995% or a monthly downtime of 2m, 10s
- AWS RDS guarantees an SLA between 99% or a monthly downtime of 43m, 28s and 99.95%
The difference in unplanned downtime between a couple of minutes and three-quarters of an hour may not seem significant, particularly for dev/test environments or ad hoc projects but for your mission-critical application, the difference could lead to loss of revenues in the tens to hundreds of thousands of dollars for SMBs to far more for larger enterprises. For example, Black Friday and Cyber Monday are peak transactional periods for retail operations, corresponding to far higher loads on DBaaS operations at a point in annual revenue cycles that will make or break overall profitability. Similar analogies can be found for enrollment periods, from student enrollment to annual Medicare and other seasonal campaigns and operations or unexpected surges in demand. In all these cases, resiliency is always a function of maintaining expected price performance for HA at scale.