
Let’s start with what a SEQUENCE is. A SEQUENCE is an SQL object that creates a series of numbers. When the SEQUENCE is created, one can define the start value, the increment step size and some more characteristics. In most cases a SEQUENCE is used to generate unique numbers to be used as primary keys. SEQUENCE objects are fully ACID, meaning they can be used concurrently by as many users as needed.
MariaDB Server before 10.3 does not have native SEQUENCE objects, but allows you to have AUTO_INCREMENT columns. This is very similar to a SEQUENCE, however it works only for a single table. If you need unique identifiers across multiple tables, this won’t help you.
Implementation
So let’s start rolling our own sequences. For each sequence we need to memorize at least the name of the sequence and the value that was most recently pulled from it. We store that in a normal SQL table:
CREATE TABLE seq_table (
seq_name CHAR(10) PRIMARY KEY,
last_val BIGINT UNSIGNED
);
That table can hold not just a single sequence, but as many sequences as we like. A sequence must initialized. That requires just a single insert:
INSERT INTO seq_table (seq_name, last_val) VALUES ("test", 0);
Next step would be to pull a new number from the sequence. This is easy enough with an update:
UPDATE seq_table SET last_val=last_val+1 WHERE seq_name="test";
But now we have a problem: how do we get the new number from last_val in a safe fashion? The update itself is atomic and wouldn’t create any conflicts. But if we select the value in a second statement, it would be possible that another thread issued its own update inbetween.
Rescue comes from an old friend: the LAST_INSERT_ID() function. The more common use case of that function is to return the last number that was created from an AUTO_INCREMENT column. But it can also be called with an argument. In that case the function just returns the argument and stores it in the connection context. Then one can get that stored value with another call to LAST_INSERT_ID(). So our update becomes to that:
UPDATE seq_table SET last_val=LAST_INSERT_ID(last_val+1) WHERE seq_name="test";
And we can see the created number with another select:
SELECT LAST_INSERT_ID();
Since LAST_INSERT_ID() is safe to be used concurrently, so is our emulated sequence.
We can now add all kind of convenience wrappers. I.e. we could implement a next_val() function for our sequences:
CREATE FUNCTION next_val(name CHAR(10))
RETURNS BIGINT UNSIGNED
NOT DETERMINISTIC
MODIFIES SQL DATA
BEGIN
UPDATE seq_table SET last_val=LAST_INSERT_ID(last_val+1) WHERE seq_name=name;
RETURN LAST_INSERT_ID();
END
Quite similarly we could have a last_val() function and a create_sequence() function and we could also implement custom increments (to be stored in seq_table) and anything else. And of course we’d have to add proper error handling.
Performance
In order to test the performance I use a very simple setup. I create a sequence and a target table. The benchmark script (a Lua script for sysbench) pulls a number from the sequence and inserts a row into the target table, using the number as primary key. This is repeated in a loop. Optionally this is done in transactions, bundling inserts in batches of 10. The workload is run with different concurrency, starting with 1 benchmark thread and then going up to 128.
Let’s look at the numbers. The following table shows the insert rate (rows inserted per second) for different thread counts:
|
row-by-row |
10 rows per transaction |
|||
|
threads |
sequence |
auto-increment |
sequence |
auto-increment |
|
1 |
303 |
603 |
2698 |
3751 |
|
2 |
335 |
651 |
4429 |
5554 |
|
4 |
629 |
1217 |
4588 |
9997 |
|
8 |
1178 |
2240 |
4467 |
19055 |
|
16 |
2137 |
4111 |
4236 |
33879 |
|
32 |
4056 |
8184 |
4202 |
55756 |
|
64 |
7678 |
16303 |
4175 |
62509 |
|
128 |
12195 |
34114 |
3884 |
59954 |
Or you might rather look at a diagram:
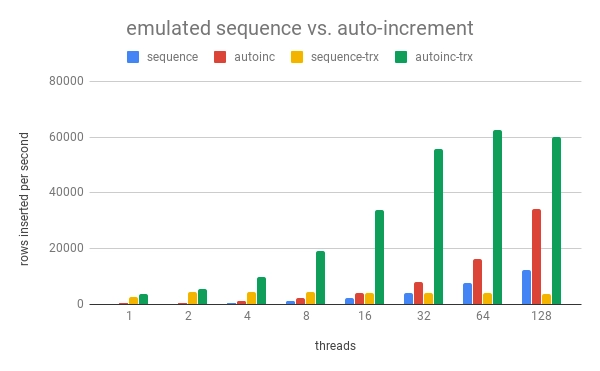
What can we see here? First: auto-increment is much faster than our emulated sequence. Second: doing the inserts in transactions of 10 is much faster than inserting row-by-row. This is because then the redo log has to be flushed 20 times as often – once for the UPDATE of the sequence table and another time for the INSERT itself. When using transactions there is only one flush for the COMMIT statement.
But we also see that the emulated sequence does not scale at all with transactional workload. This is easily explained. When the first thread updates the row in the sequence table, it gets an exclusive lock for that row. When this happens in a transaction, the thread keeps that lock until it commits. But that also means that no other thread can pull a number from the sequence, because for that it would need that same lock. Hence we effectively serialize transactions from different threads as soon as we use the sequence.
This serialization problem can be solved by using a MyISAM table to hold the sequence. However then the sequence is no longer crash-safe. You would risk that the sequence returns duplicates after a server crash. I strongly discourage.
Disclaimer
The benchmarks were run using MariaDB Server 10.3.9, running on a 16-core (32 threads) Intel machine. The datadir was on SSD and MariaDB Server was configured for full durability.
The sysbench implementation is sysbench-mariadb from GitHub. If you look at the numbers from sysbench, keep in mind that the emulated sequence requires two writes to insert one row. So the number of inserts is actually half the number of writes reported by sysbench.
The benchmark scripts, configuration and raw results can be found here.