
Key takeaways
-
– MariaDB’s new Advanced Cluster uses the Raft protocol to significantly reduce write latency by only requiring a majority of nodes to agree, rather than waiting for every single node to respond. - – This approach makes global, geo-distributed applications much faster and more resilient by effectively ignoring the lag from your slowest or most distant data centers.
- – The system automates fault tolerance, meaning if a leader node fails, the cluster instantly elects a new one to keep your database online without manual intervention.
- – By moving to a leader-follower model, the cluster simplifies complex write operations and provides a stronger foundation for scaling your database horizontally.
We are excited to announce the Technical Preview of MariaDB Advanced Cluster, a new solution for high availability built with the Raft consensus protocol. This release marks a significant leap forward in high availability, offering enhanced performance, scalability and resilience, especially for globally distributed applications.
While MariaDB Galera Cluster provides synchronous multimaster replication for high availability and strong consistency, traditional synchronous replication in geo-distributed environments can introduce commit latency and complex conflict resolution as network distance between nodes grows. The inherent design of traditional synchronous replication guarantees zero data loss, but requires every node to acknowledge a transaction before it can commit. In environments with high network latency, the slowest node dictates the performance of the entire cluster.
Raft: The Power of Consensus
Raft is an algorithm designed for managing a replicated log, ensuring that all database nodes agree on the exact same sequence of changes, even in the face of node failures or network issues. The main advantages of the Raft protocol for a cluster are its simplicity and ease of understanding, which make it easier to implement, along with strong guarantees for fault tolerance, data consistency and high availability. Even with node failures or network issues, Raft ensure that all nodes agree on a single, consistent log of operations. Raft achieves this through a clear leader election process and log replication, allowing the system to remain operational and data-safe during failures.
How it works:
- Leader election: Raft designates a single Leader node. Write operations (e.g., transactions, schema changes) will be received by Leader and Follower; the leader node acts as a coordinator for resolving cluster-wide conflicts.
- Log replication: The Leader appends these operations as entries to its internal log and then replicates these log entries to all of its Follower nodes.
- Commit and consensus: A write operation is considered “committed” as soon as a majority of the nodes (including the Leader) have safely stored the log entry. This crucial “majority rule” is where Raft gains its significant advantages.
- Fault tolerance: If the Leader fails, the Followers quickly elect a new Leader, ensuring continuous availability without manual intervention.
Advantages of MariaDB Advanced Cluster
- Significantly lower write latency in geo-distributed environments: Unlike Galera, which waits for all active nodes to acknowledge a commit, Raft only requires a majority. This means that in a 7-node cluster, a write can commit as soon as 4 nodes respond, effectively bypassing the latency of the 3 slowest or most distant nodes. For global deployments, this translates directly to faster application response times.
- Enhanced fault tolerance: A Raft cluster can tolerate the loss of up to $\frac{N-1}{2}$ nodes (e.g., 3 nodes in a 7-node cluster) while remaining fully operational. The clear Leader-Follower model also simplifies failure detection and recovery.
- Simplified write operations: By channeling all writes through a single Leader, Raft inherently provides a strict ordering of operations.
- A foundation for scale-out: The Raft protocol is a cornerstone of many modern distributed databases that achieve true horizontal scaling. While this Technical Preview focuses on consensus for a set of nodes, it lays the groundwork for future advancements in distributed storage and computation within the MariaDB ecosystem.
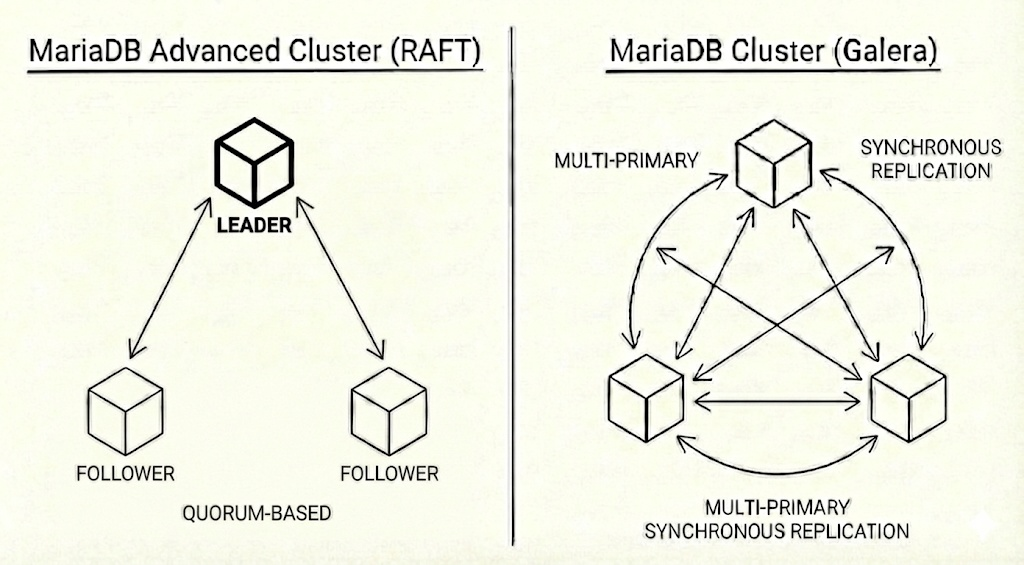
MariaDB Advanced Cluster (Raft) vs. MariaDB Cluster (Galera)
While MariaDB Galera Cluster excels at providing strong consistency with its multimaster, virtually synchronous replication, MariaDB Advanced Cluster offers advantages that are particularly compelling for modern distributed deployments.
| Feature | MariaDB Advanced Cluster (Raft) | MariaDB Cluster (Galera) |
|---|---|---|
| Replication Model | Multimaster with Single-Leader (writes controlled by Leader) | Multimaster (writes to any node) |
| Consistency | Strong (majority acknowledge) | Strong (virtually synchronous – all nodes acknowledge) |
| Write Latency | Bounded by the closest majority RTT | Bounded by the slowest node’s RTT |
| Geo-Replication | Highly efficient due to majority rule | Challenging due to high WAN latency |
| Throughput Scaling | Better potential for horizontal write scaling by adding nodes | Limited by synchronous overhead |
Your Feedback Fuels Our Innovation!
MariaDB Advanced Cluster is a powerful step forward, building on the reliability and performance of MariaDB Enterprise Server with the high availability and distribution capabilities of the Raft consensus protocol.
Join the Technical Preview
This Technical Preview is an exclusive opportunity for our enterprise customers to:
- Experience faster write performance in high-latency network scenarios.
- Test resilience against node failures and network partitions.
- Evaluate operational simplicity compared to existing solutions.
- Shape the future of MariaDB Enterprise Platform.
Note: Access to this Technical Preview requires an active MariaDB Enterprise Platform subscription.
Download the MariaDB Advanced Cluster Technical Preview today!