
Vendors and developers sometimes talk about ACID, transactions, or consistency haphazardly. It is essential to understand what consistency means and the limitations of the methods of achieving it. Without that understanding, your application will have errors, come to a screaming halt, or worse, risk hidden data loss.
Consistency with multiple clients and one database server was a challenging problem to solve. Early databases used approaches like table locks, then page locks, and row locks. Yet those did not work well as concurrency increased. Multiple clients or server processes would contend for the lock and tie up other resources like database server connections. As resources became constrained and contended, the locks would last longer, leading to a downward spiral.
New methods of ensuring consistency were created that rely on giving client threads a copy of the data to work on instead of locking the original. In other words, the client’s reads and writes are isolated until the change is “committed.” This Multiversion Concurrency Control (MVCC) or “snapshot isolation” has its problems. Still, so long as actual collisions are rare, it tends to be “more concurrent” than locks at the expense of more disk space or memory.
A Quick Refresher
Every strong database consistency scheme aims to ensure data is ACID (atomic, consistent, isolated, and durable). However, every scheme has a cost in terms of concurrency, throughput, and resource utilization. Early locking schemes favored low resource utilization at the expense of concurrency. Newer schemes assume resources are cheap and concurrency is more critical.
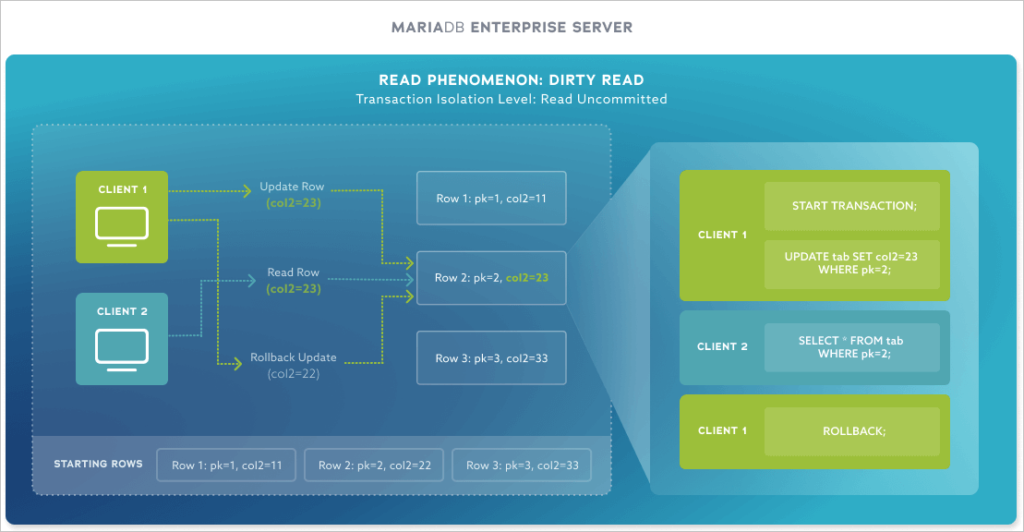
There are different kinds of isolation errors that can occur in a database. The most basic is a dirty read. Two threads see intermediate states of the data that have not been “committed.” Avoiding these errors is easy when using any form of transaction control.
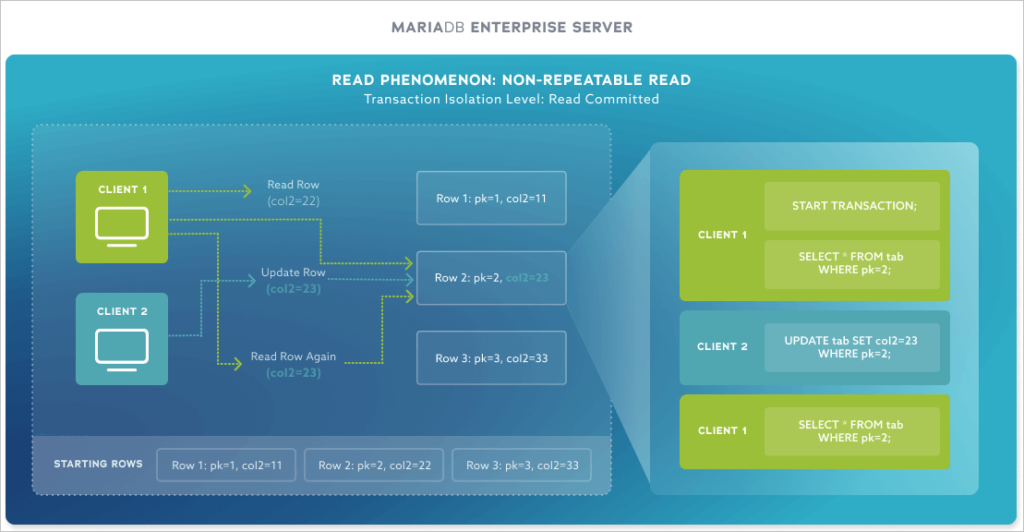
More common are non-repeatable reads where Thread A reads, Thread B updates, Thread A then updates based on its initial read. If thread A acquires no lock or transactional context for its initial read, it will write state based on a “non-repeatable” read. A lot of old client-server code that ran with AUTO_COMMIT turned on experienced this issue as the software did each read and write operation in a separate transaction.
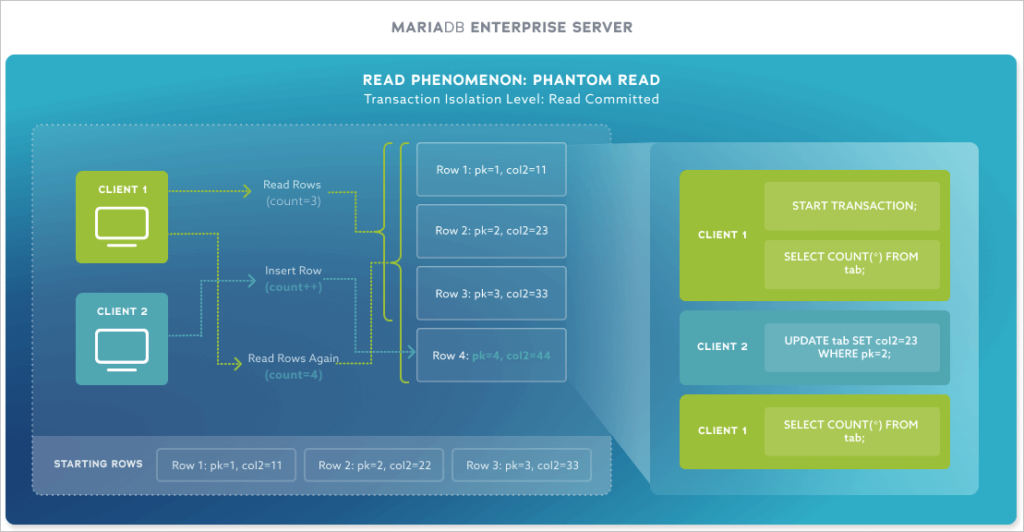
Most developers do not think about phantom reads. Consider the classic case of Orders to Order Items, where the ORDER_ITEMS table contains the order’s line items. If there are 25 different items in the order and Thread A runs X=conn.execute("select count(*) from order_items where item_id=1") then X will be 25. If thread B then inserts a new row in ORDER_ITEMS, when thread A rechecks the count, it will get 26. In many cases, this is “no big deal,” but Thread A operates on data that is not consistent between operations. There is a way to handle that without locking a table, using something called a “range lock”. Essentially a range lock either locks or copies the items found in the first query.
Beyond ACID: Multi Server Consistency
On mainframes, table and page locks were common. In the early days of computing, there was only so much data and few users, and these methods were feasible. With the advent of client-server computing, row locks and snapshot isolation were more common. There was not only more data, but more clients were running concurrently and with higher latency than locally-run programs. If you fast-forward to the present, virtually all cloud-scale databases operate on a form of snapshot isolation. Concurrency is even more critical than ever.
As databases have become distributed, consistency is no longer a single-server problem. On a multi-node database like MariaDB Xpand (also available in the cloud through MariaDB SkySQL), the database must also ensure that the data’s replicas are consistent. For a distributed SQL database, this means ensuring that if a record is on two nodes, both copies are consistent even when state is changing. A consistency guarantee requires a coordinated version of transaction control that spans the network.
One approach that some databases have taken is to coordinate control over the data from one primary node. If a client issues UPDATE product SET name='Mongo' WHERE id=1 then one particular node in the cluster is in charge of product 1. All changes to product 1 go through that node. This approach causes problems with reliability and limits performance and scale. If that node goes down, then a new primary has to be elected.
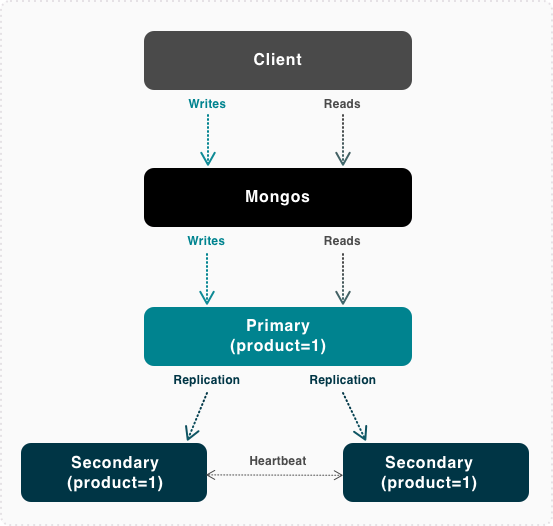
Modern distributed SQL databases like Xpand use a bit more memory to agree on the cluster’s state and coordinate state changes synchronously. When an application client enrolls a record in a transaction, the database creates a provisional record. When the application client performs an update or write, the row is locked. As the transaction commits, each node in the cluster that contains the record acknowledges the write, locks are released, and then the client continues.
A protocol called Paxos coordinates state changes for Xpand. Paxos allows multiple nodes on the network to agree on state changes even without a hardware-based atomic clock. It also handles problems like network instability or faults.
Latency: The Price You Pay for Consistency
Nothing is free. Latency is the price you pay for strong consistency. While the database writes a row to nodes across the network, operations will block. Moreover, the more nodes involved and the further they are apart, the longer this will take. This latency is often measured in nanoseconds or single-digit milliseconds when in a single geographic region.
With current technology and barring some advances in quantum networks, data travels at some fraction of the speed of light. Regardless of throughput, when a database replicates a row between two geographic zones, changes usually happen with an unacceptable amount of latency. However, most data is heavily geographically dependent. A customer in the UK will not likely write to the same record in the US geographic region simultaneously. In all likelihood will not write to the US geographic region at all unless there is some kind of catastrophic failover.
The rules of strong consistency are often relaxed when performing writes across geographic regions (usually for disaster or availability purposes). For these long writes, administrators enable a form of cross-data-center replication. Cross-data-center replication tolerates latency while assuring data replicates even during failures. There are times when strong consistency between geographic regions is necessary. However, it is not a common use case due to the inherent latency and geographic affiliation of data.
Your Application Decides What is Consistent
If a developer writes an application using AUTO_COMMIT mode, then every statement is a separate transaction. While the transaction will be consistent, the data probably will not be. There is a higher cost to coordinating transactions in a distributed database. When an application uses a similar auto-commit pattern with a distributed database, there will be an even higher cost to many mini-transactions and low throughput. Next, data errors will seep in rather quickly as the transaction bounds do not match what the application is trying to do.
Most modern developers do not use AUTO_COMMIT, but many do not think about a transaction’s boundaries and what they mean for both consistency and the database. Many developers believe that transactions govern writes and not reads. In reality, they manage both and the database’s effort to keep data together.
When designing an application or service that saves state, it is essential to think about the boundaries of a unit of work and what it means. The transaction boundary should include only those operations that are part of that work, anything more, and there is an opportunity for conflict. Anything less, and there is a chance of error.
Be Consistent
By all means, use technologies that support strong consistency — such as MariaDB Xpand. However, consistency begins in and ends in your application. Consider consistency as a holistic concept, required by your business logic, encoded in your application which governs your database which manages your data. If any piece of the puzzle doesn’t work — you have an error!
Learn More
- To learn more about how MariaDB Xpand assures consistency at scale, check out How MariaDB Achieves Global Scale in InfoWorld or check out our animated feature on YouTube.
- Or, if you are ready to give it a try, you can launch Xpand in SkySQL right now!