
MariaDB MaxScale is an excellent solution for making your MariaDB Server database deployments highly available… but how do you make sure MaxScale does not become the new single point of failure? Modern MariaDB application connectors provide simple failover configuration options so if one MaxScale node goes down, the application connector will automatically try connecting to another MaxScale node it knows. Combined with MaxScale’s cooperative locking feature, your application can continue querying your database cluster uninterrupted when a MaxScale node goes down.
What is a MariaDB Application Connector?
A MariaDB application connector is a library you can import into your development project which facilitates making connections and queries to MariaDB Server instances. MariaDB directly maintains and provides many connectors tailored to meet the needs of many programming languages.
An important step of implementing a connector in your application code is to configure how the connector will find your MariaDB Server to connect and query. The exact process for how to define this varies by connector and programming language, but generally you pass a hostname, IP address, or file socket parameter. When your deployment leverages MariaDB MaxScale, you usually use the hostname or IP address and port of the primary MaxScale instance.
What is Connector Failover?
Modern connector libraries allow developers to pass more than one connection target as part of their connection configuration. This allows the connector to try another connection target when its first choice does not respond. In the simplest implementations of this, developers supply an ordered list of MariaDB MaxScale or MariaDB Server instances, and the connector routes queries to the first backend in its list. If the first backend does not respond, the connector tries the next backend in its list, and it keeps doing this until it gets a response, or until there are no more backends in its list to try. This behavior allows the connector to “automatically failover”, avoiding downtime.
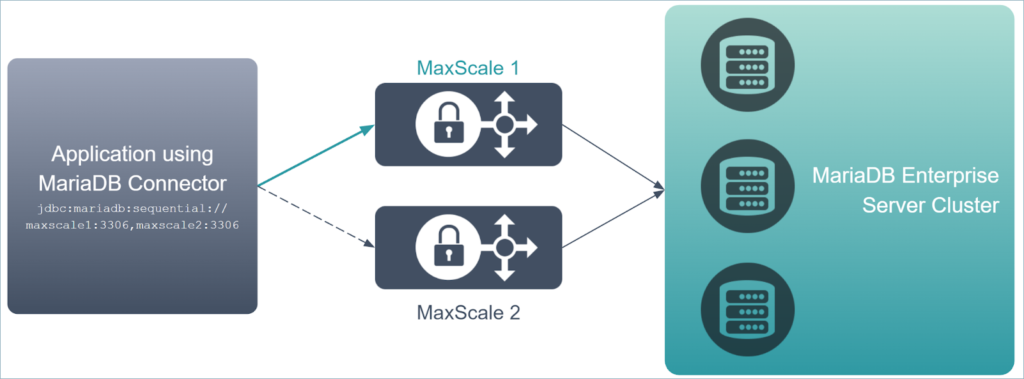
Using Connector/J (Java)
MariaDB’s Connector/J supports defining a high availability mode, and it supports defining multiple backends. To use simple failover, use Sequential Mode which will have Connector/J try connecting to the configured backends in the order they appear in the connection string. Below is an example of a connection string which defines two MaxScale instances with Sequential failover-
jdbc:mariadb:sequential://maxscale1:3306,maxscale2:3306
Note that in this example, maxscale1 and maxscale2 serve as hostnames- you would need to replace these with the actual hostnames or IP addresses of your MaxScale instances. An application using this configuration would direct all queries to maxscale1:3306 and would only try sending queries to maxscale2:3306 if maxscale1:3306 fails to respond. If you would like to add further resiliency, you could set up more Maxscale nodes and append them to the comma-separated list in the connection string.
Using Connector/C (also relevant for ODBC and C++)
MariaDB’s Connector/C offers simple failover configuration by allowing the mysql_real_connect function to accept a string with a comma-separated list of host:port combinations for its host parameter. The comma-separated list is parsed in order, so the connector will only use the first host unless connecting to that fails, in which case it will try the next host. Below is a basic example of what the host parameter could look like-
“maxscale1:3306,maxscale2:3306”
Note that in this example, maxscale1 and maxscale2 serve as hostnames- you would need to replace these with the actual hostnames or IP addresses of your MaxScale instances.
Here is a fuller example of using Connector/C to achieve this goal-
int main() { MYSQL *conn; const char *server1 = getenv("MXS1_HOST"); const char *server2 = getenv("MXS2_HOST"); const char *user = getenv("MXS_USER"); const char *password = getenv("MXS_PASS"); const char *database = getenv("TEST_DB"); char servers[100] = ""; strcat(servers, server1); strcat(servers, ":3306,"); strcat(servers, server2); strcat(servers, ":3306"); if (servers == NULL || user == NULL || password == NULL || database == NULL) { fprintf(stderr, "Environment variables not set properly.\n"); return EXIT_FAILURE; } conn = mysql_init(NULL); if (conn == NULL) { fprintf(stderr, "mysql_init() failed\n"); return EXIT_FAILURE; } if (mysql_real_connect(conn, servers, user, password, database, 0, NULL, 0) == NULL) { fprintf(stderr, "mysql_real_connect() failed\n"); mysql_close(conn); return EXIT_FAILURE; } printf("Connected to the database successfully!\n"); mysql_close(conn); return EXIT_SUCCESS; }
As MariaDB’s C++ connector and ODBC driver implement Connector/C so the same technique works for them as well.
Using Connector/Node.js
MariaDB’s Connector/Node.js offers Load Balancing functionality via its connection pool cluster feature. To configure this to use simple failover, configure the specify defaultSelector: ‘ORDER’ as part of the pool cluster’s configuration-
// Create connection pool cluster const cluster = mariadb.createPoolCluster({ defaultSelector: 'ORDER' // Try pools in order, only trying the next pool if the prior fails });
Hosts can be added sequentially with-
// Add first MaxScale node to cluster
cluster.add('mxs1', { host: process.env.MXS1_HOST, user: process.env.MXS_USER, password: process.env.MXS_PASS, database: process.env.TEST_DB, connectionLimiit: 100});
// Add second MaxScale node to cluster
cluster.add('mxs2', { host: process.env.MXS2_HOST, user: process.env.MXS_USER, password: process.env.MXS_PASS, database: process.env.TEST_DB, connectionLimiit: 100});
With this setup, the connector would always try to query mxs1 first, but if it does not respond it would automatically try mxs2. Here is a more complete example of setting-up a pool cluster, adding connections to the pool cluster, and then performing queries-
const mariadb = require('mariadb'); require('dotenv').config(); // Create connection pool cluster const cluster = mariadb.createPoolCluster({ defaultSelector: 'ORDER' // Try pools in order, only trying the next pool if the prior fails }); // Add first MaxScale node to cluster cluster.add('mxs1', { host: process.env.MXS1_HOST, user: process.env.MXS_USER, password: process.env.MXS_PASS, database: process.env.TEST_DB, connectionLimiit: 100}); // Add second MaxScale node to cluster cluster.add('mxs2', { host: process.env.MXS2_HOST, user: process.env.MXS_USER, password: process.env.MXS_PASS, database: process.env.TEST_DB, connectionLimiit: 100}); // Test and validate connection (async () => { let conn; try { // Get connection conn = await cluster.getConnection(); // Test no table read query const rows = await conn.query("SELECT 1 as val"); console.log(rows); //[ {val: 1}, meta: ... ] // Test writing const res = await conn.query("INSERT INTO testTable (value) VALUE (?)", ["nodejs"]); console.log(res); // { affectedRows: 1, insertId: 1, warningStatus: 0 } // Test reading from a table const tableRows = await conn.query("SELECT * FROM testTable"); console.log(tableRows); } catch (err) { throw err; } finally { if (conn) return conn.end(); } })();
Together, MariaDB Connectors and MaxScale keep your MariaDB database cluster available
By using the connector failover techniques in tandem with deploying multiple MaxScale instances (with cooperative monitoring configured), you can eliminate single points of failure from your database cluster. For further advice on using MaxScale for failover and high availability, download The Ultimate Guide to Database High Availability with MariaDB.
Next steps
- Grab your license token and download MaxScale Enterprise software, Docker images, connectors and more from mariadb.com/downloads
- Need help or want to connect? MariaDB is here to help with Remote DBA, Expert Technical Support, Migration, Training, Consulting and more.
- Contribute, learn from, and connect with your MariaDB community on Slack, DBA Stack Exchange, and the Community Knowledge Base.
- Learn more about MariaDB MaxScale