
Guide pratique de l’IA et de la recherche vectorielle dans les bases de données relationnelles
01 Résumé exécutif
L’intelligence artificielle (IA) n’est plus une simple expérimentation futuriste – elle transforme d’ores et déjà la façon dont les entreprises fonctionnent. Et au cœur de nombreuses applications alimentées par l’IA se trouve un nouveau besoin : la recherche vectorielle.
Des agents IA aux moteurs de recommandation, en passant par les bases de connaissances et la recherche sémantique, ces capacités reposent sur le stockage et l’interrogation de représentations vectorielles – et non plus seulement sur les traditionnelles lignes et colonnes. La recherche vectorielle permet aux applications de récupérer des résultats basés sur le sens et la similarité, plutôt que sur des correspondances exactes.
Jusqu’à récemment, la mise en œuvre de la recherche vectorielle nécessitait l’introduction d’une base de données vectorielle tierce en plus de votre système relationnel principal. Cela complexifiait l’architecture, augmentait la charge opérationnelle et introduisait de nouveaux risques d’intégration.
Mais la situation change.
Les bases de données relationnelles évoluent pour prendre en charge la recherche vectorielle nativement. Cela permet aux organisations d’unifier les requêtes structurées et la recherche de similarité au sein d’une seule plateforme – rapprochant ainsi les capacités d’IA des systèmes de production et réduisant la distance entre l’expérimentation et le déploiement.
Ce guide offre une introduction pratique à la recherche vectorielle : ce que c’est, pourquoi c’est important et où cela s’intègre dans une stratégie de données d’entreprise moderne. Nous explorerons les considérations techniques clés – des stratégies d’indexation aux modèles de requêtes hybrides – et vous aiderons à comprendre quand une base de données relationnelle avec support vectoriel intégré (comme MariaDB Enterprise Platform) est le bon choix, et quand un moteur vectoriel spécialisé est encore nécessaire.
Si vous envisagez de faire évoluer votre infrastructure actuelle pour incorporer l’IA, ce guide vous aidera à naviguer entre les compromis, les cas d’utilisation et les modèles d’implémentation les plus impactant pour faire monter en charge la recherche vectorielle dans l’entreprise.
- La recherche vectorielle aide les applications d’IA à comprendre le sens et le contexte, allant au-delà de la correspondance traditionnelle par mots-clés pour alimenter des fonctionnalités telles que les recommandations personnalisées et les chatbots intelligents.
- Les bases de données relationnelles modernes intègrent désormais la recherche vectorielle de manière native, ce qui simplifie votre architecture système en unifiant les requêtes de données traditionnelles avec les recherches de similarité pilotées par l’IA sur une seule plateforme.
- En utilisant une base de données relationnelle avec recherche vectorielle intégrée, comme la plateforme MariaDB Enterprise, vous pouvez déployer des capacités d’IA plus rapidement et plus efficacement, en tirant parti de votre expertise SQL existante et en réduisant les frais opérationnels.
02 Comprendre la recherche vectorielle en IA
Les systèmes de recherche traditionnels reposent sur la correspondance de mots-clés ou de valeurs structurées. Bien qu’efficaces pour les requêtes exactes, ils ne savent pas gérer le sens, l’intention ou le contexte. Or ce sont des capacités essentielles pour les applications modernes de l’IA. La recherche vectorielle est la réponse à cette limitation.
Au cœur de la recherche vectorielle se trouvent les représentations vectorielles, qui sont des représentations numériques de données produites par des modèles d’apprentissage automatique. Ces représentations projettent du texte, des images ou d’autres contenus dans un espace multi-dimensionnel où la proximité reflète la similarité sémantique. Deux tickets de support client, par exemple, peuvent être formulés différemment mais se situer près l’un de l’autre dans l’espace vectoriel s’ils décrivent le même problème sous-jacent. Un espace vectoriel est simplement une grille fortement multi-dimensionnelle. Chaque représentation est un point sur cette grille, et les vecteurs ayant une signification similaire tendent à se regrouper.
Un système de recherche vectorielle permet des requêtes telles que « trouver des transactions similaires à celle-ci » ou « récupérer des documents liés par le sens à ce paragraphe ». Au lieu d’un appariement exact, il classe les résultats en fonction de la distance entre les représentations vectorielles, en utilisant des algorithmes tels que la similarité cosinus ou la distance euclidienne.
En pratique, la recherche vectorielle est couramment utilisée pour alimenter :
Recommandations personnalisées basées sur le comportement ou les préférences de l’utilisateur
Récupération sémantique de documents, utilisant des vecteurs pour localiser des informations conceptuellement liées
L’IA conversationnelle, où les vecteurs contextuels aident à affiner les réponses des chatbots
Certains systèmes de production utilisent un hybride de recherche et de requête, où des filtres structurés tels que le segment, le timestamp ou la catégorie de produit se combinent avec la similarité vectorielle. Cette approche permet des cas d’utilisation à la fois opérationnellement basés et sémantiquement riches.
Grace à l’intégration la recherche vectorielle dans les bases de données relationnelles courantes, les entreprises peuvent gérer ces charges de travail sans introduire de nouveau composant dans l’infrastructure. Les recherches vectorielles peuvent s’exécuter parallèlement au SQL traditionnel, permettant ainsi l’ajout de capacités d’IA au sein de systèmes et d’outils familiers.
03 Considérations essentielles sur les bases de données pour la recherche vectorielle
La recherche vectorielle introduit une nouvelle classe de requêtes qui privilégie la similarité sémantique par rapport aux correspondances exactes. Bien que conceptuellement simple, la mise en œuvre de la recherche vectorielle à grande échelle pose des défis distincts pour les systèmes de bases de données. La performance, l’indexation et l’intégration avec les flux de requêtes existants sont tous des facteurs clés dans le choix de la bonne approche.
Performance et évolutivité
Contrairement aux index traditionnels qui prennent en charge les recherches d’égalité ou de plage, les index vectoriels sont optimisés pour la recherche de voisin le plus proche approximatif (ANN). Ces algorithmes échangent une précision parfaite contre la vitesse, permettant des requêtes de similarité en temps réel même sur de grands ensembles de données.
Trois approches sont couramment utilisées :
HNSW (Hierarchical Navigable Small Worlds)
Un index basé sur les graphes qui offre de bonnes performances de recherche et un taux de rappel élevé. Il nécessite beaucoup de mémoire mais fonctionne bien pour les applications à faible latence.
IVFFlat (Fichier Inversé avec Vecteurs Plats)
Une méthode basée sur le partitionnement qui équilibre temps d’indexation et efficacité de la recherche. Elle peut s’adapter à de grandes quantités de données mais peut nécessiter des ajustements.
Recherche par force brute
Une méthode exhaustive qui garantit des résultats exacts. Bien qu’elle soit précise, elle est coûteuse en puissance de calcul et est généralement réservée aux petites quantités de données ou pour des évaluations hors ligne.
Les systèmes de recherche vectorielle doivent également prendre en charge les accès concurrent, en particulier lorsqu’ils sont intégrés dans des applications transactionnelles. Par exemple, certains processus peuvent nécessiter des centaines de requêtes de similarité par seconde, exécutées parallèlement à des insertions, des mises à jour et des lectures analytiques.
Gestion du stockage et des représentations
Les représentations de vecteurs sont souvent stockées sous forme de tableaux de nombres à virgule flottante encodés sur 32 bits, ou occasionnellement quantifiés à des tailles plus petites pour des raisons de performance. La gestion de ces représentations à grande échelle nécessite encore des formats de stockage compacts et des stratégies d’indexation intelligentes. Certains systèmes compressent ou quantifient les vecteurs ; d’autres privilégient des lectures rapides pour une inférence à faible latence.
Les bases de données doivent également prendre en charge les opérations d’insertion/mise à jour à des vitesses qui correspondent aux pipelines d’IA en amont. Par exemple, les catalogues de produits, les journaux de comportement ou les historiques de transactions peuvent générer des représentations en continu.
Architectures intégrées vs. plug-in
Certains systèmes vectoriels sont construits comme des extensions tierces aux bases de données généralistes. D’autres sont intégrés dans une base de données généraliste. Les implémentations intégrées offrent souvent de meilleures performances car elles se connectent directement au moteur de stockage, à l’optimiseur et au système d’indexation.
A titre d’exemple, la plateforme MariaDB Enterprise intègre l’indexation vectorielle, offrant une intégration plus étroite et une meilleure concurrence comparativement aux extensions tierces superposées à PostgreSQL.
Intégration hybride de vecteurs et SQL
De nombreux cas d’usages combinent les filtres structurés avec une recherche de similarité. Une requête typique peut filtrer par type d’utilisateur, catégorie de produit ou date, puis classer les résultats par distance vectorielle. Le support des requêtes hybrides – combinant des prédicats relationnels et une récupération ANN – est essentiel pour les applications.
Exemple de requête MariaDB Enterprise Platform :
Commerce électronique
Montrez-moi dix vestes comme celle-ci, à moins de 200 $, qui sont en stock.
SELECT product_id, nom, prix
FROM products
WHERE category = 'Vestes'
AND prix < 200
AND en_stock = TRUE
ORDER BY VEC_DISTANCE(embedding, ?) -- lier le vecteur associé à la requête ici
LIMIT 10;
Support Client
Trouvez des tickets récents comme celui-ci provenant de clients premium.
SELECT ticket_id, subject, opened_at
FROM support_tickets
WHERE customer_tier = 'Premium'
AND opened_at >= CURRENT_DATE - INTERVAL 30 DAY
ORDER BY VEC_DISTANCE(ticket_embedding, ?) -- lier le vecteur associé au nouveau ticket
LIMIT 5;
Base de connaissances
Récupérer des articles similaires à cette question, pour le produit « MariaDB Enterprise Platform », publiés au cours des six derniers mois.
SELECT doc_id, title, published_at
FROM kb_articles
WHERE product = 'MariaDB Enterprise Platform'
AND published_at >= CURRENT_DATE - INTERVAL 6 MONTH
ORDER BY VEC_DISTANCE(article_embedding, ?) -- lier le vecteur de paragraphe
LIMIT 15;
Diffusion de médias
Trouvez dix films d’action comme celui-ci, classés PG-13, sortis après 2015.
SELECT movie_id, title, release_year
FROM movies
WHERE genre = 'Action'
AND classification = 'PG-13'
AND release_year >= 2015
ORDER BY VEC_DISTANCE(movie_embedding, ?) -- lier le vecteur du film de départ
LIMIT 10;
Recherche de talents
Afficher les candidats dont les CV ressemblent à ce profil, situés aux États-Unis, avec ≥ 5 ans d’expérience.
SELECT candidate_id, full_name, years_experience, last_active
FROM resumes
WHERE VEC_DISTANCE(resume_embedding, ?) < 0,35 -- seuil strict de similarité
AND country_code = 'US'
AND years_experience >= 5
ORDER BY last_active DESC -- tri secondaire
LIMIT 12;
Ces exemples illustrent comment MariaDB combine des prédicats relationnels avec un classement par voisinage approximatif dans un seul plan de requête. Vous obtenez une recherche de similarité rapide, les garanties traditionnelles du SQL, et aucun des frais opérationnels liés à l’exécution d’une base de données vectorielle distincte.
04 Cas d’utilisation où les bases de données généralistes avec recherche vectorielle excellent
Bien que les bases de données vectorielles autonomes soient conçues pour la récupération sémantique à grande échelle, de nombreux cas d’utilisation en production impliquent des données structurées, des exigences opérationnelles ou une infrastructure SQL existante. Dans ces cas, intégrer la recherche vectorielle directement dans une base de données relationnelle réduit la complexité, simplifie l’intégration et accélère le déploiement.
Les exemples suivants mettent en évidence des cas d’usages où les capacités vectorielles intégrées dans les bases de données SQL – telles que MariaDB Enterprise Platform – offrent des avantages pratiques.
Récupération des connaissances d’entreprise
La documentation interne, les wikis et le contenu de support couvrent souvent plusieurs équipes et formats. La recherche par mots-clés traditionnelle a du mal à faire ressortir du matériel sémantiquement pertinent. En intégrant le contenu et les requêtes des utilisateurs dans des vecteurs, les entreprises peuvent obtenir des résultats qui correspondent au sens, et pas seulement aux mots.
Stocker et interroger des représentations dans la même base de données qui contient les métadonnées des documents permet de filtrer par équipe, département ou date tout en classant par pertinence.
Recommandations de produits pour le commerce électronique
Les systèmes de recommandation reposent souvent sur la similarité entre les produits, les préférences des utilisateurs ou le comportement des sessions. Les vecteurs représentant ces relations peuvent être interrogés via une recherche vectorielle pour fournir des recommandations de “produits similaires” ou “les utilisateurs ont également consulté”. Intégrer cette logique dans une base de données relationnelle simplifie le filtrage des stocks, la localisation et la personnalisation.
Assistants IA pour le support client
La récupération de cas antérieurs pertinents est essentielle pour alimenter les assistants IA et aider les agents de support. L’intégration des tickets passés et du contenu de support permet une récupération par similarité avec les nouvelles requêtes. Associer le classement vectoriel à des métadonnées structurées (par exemple, type de produit, niveau de client) permet d’obtenir des résultats très précis dans un processus de support.
05 Quand utiliser une base de données spécialisée
Les différents moteurs de bases de données ont des fonctionnalités de recherche vectorielle différentes. Par exemple, les fonctions vectorielles intégrées de MariaDB couvrent bien le modèle commun “ANN-plus-SQL” pour la plupart des charges de travail en production. Si vos besoins en recherche exigent IVF-PQ, HNSW avec élagage dynamique des arêtes, quantification par produit de sous-vecteur, ou un contrôle strict sur les intervalles de réentraînement des livres de code, vous devriez peut-être envisager une base de données spécialisée. Même dans ce cas, vous souhaiterez probablement utiliser un mélange d’une base de données généraliste et une base de données spécialisée. La couche relationnelle peut toujours gérer les métadonnées, les jointures et les garanties transactionnelles, tandis que la base de données spécialisée peut traiter votre algorithme vectoriel particulier.
06 Mise en œuvre de la recherche vectorielle dans les bases de données SQL
L’intégration de la recherche vectorielle directement dans une base de données SQL permet une recherche hybride dans des environnements de données familiers. Cela réduit la prolifération des infrastructures et rapproche les fonctionnalités alimentées par l’IA des systèmes hébergeant les données opérationnelles. Une implémentation réussie implique la gestion des représentations, l’optimisation des index et une conception minutieuse des requêtes.
Stockage et Interrogation de Vecteurs
Les données vectorielles sont généralement stockées sous forme de tableaux de longueur fixe de nombres à virgule flottante stocké sur 32 bits. Les bases de données SQL avec support vectoriel intégré les traitent comme un type de données dédié, permettant une insertion, une indexation et un requêtage directement.
Exemple
Insérer un vecteur dans une table :
INSERT INTO knowledge_base (id, content, embedding)
VALUEES (101, 'Comment activer SSO', VEC_FROM_TEXT('[0.13, 0.48, 0.91, ...]'));
Exemple
Recherche de similarité :
SELECT id, contenu
FROM knowledge_base
ORDER BY VEC_DISTANCE(embedding, VEC_FROM_TEXT('[0.12, 0.49, 0.90, ...]'))
LIMIT 3;
Certaines bases de données prennent également en charge l’intégration directe avec Python ou les représentations générées par API, permettant à la couche de logique applicative de transmettre des vecteurs au moment de la requête.
Indexation pour la performance
Pour les charges de travail à grande échelle, l’indexation vectorielle est essentielle. Les index de voisinage approximatif comme HNSW offrent des performances de recherche sous-linéaires avec un taux de rappel élevé. Ces index peuvent être configurés en fonction des besoins de l’application – des graphes plus grands améliorent la précision mais nécessitent plus de mémoire.
Les meilleures pratiques incluent :
- Choisir des paramètres d’indexation adaptés à votre charge de requêtes
- Assurer une mémoire suffisante pour garder les index en mémoire pour un accès rapide
- Reconstruire périodiquement les index lorsque les distributions de représentations changent
Considération du rappel
De nombreuses bases de données vantent leurs performances globales avec la recherche vectorielle, cependant, un aspect clé à l’appréhension de chaque benchmark ou prétention est le paramètre de rappel utilisé.
- 0,9 est un bon point de départ pour la plupart des cas d’usage en production.
- 0,95 est généralement plus sûr pour les applications d’IA utilisant l’approche RAG (génération enrichie par recherche) afin de réduire les hallucinations.
- 0,8 pour ajuster la réactivité devrait suffire pour des aperçus d’interface utilisateur, des recommandations, etc.
Ce que signifie réellement le terme « rappel » dans ce contexte :
En recherche vectorielle, le terme « rappel » désigne généralement à quel point l’algorithme ANN se rapproche des plus proches voisins exacts (la vérité du terrain).
Par exemple :
- Si les 10 voisins de référence sont {a, b, c, …, j}
- Et votre algorithme ANN renvoie {a, b, c, d, f, h, i, j, k, l}
- Alors rappel@10 = 8 / 10 = 0,8
En général, utiliser un paramètre inférieur à 0,8, bien que cela puisse produire des résultats impressionnants pour les benchmarks, produit des résultats qui ne sont pas acceptables pour un usage en production.
Recherche Hybride et Filtrage SQL
L’un des principaux avantages de la mise en œuvre de la recherche vectorielle dans SQL est la capacité de combiner la recherche de similarité avec des filtres structurés
Exemple
Récupérer les tickets de support similaires à un problème donné, filtrés par version du produit et priorité :
SELECT id, title
FROM support_tickets
WHERE product_version = '2.1'
AND priorite = 'Haute'
ORDER BY VEC_DISTANCE(embedding, VEC_FROM_TEXT('[...]'))
LIMIT 5;
Cette intégration étroite permet la récupération contextuelle d’informations par l’IA sans pipeline supplémentaire traversant plusieurs systèmes.
Gestion des représentations
Un stockage efficace des représentations et une gestion du cycle de vie sont essentiels. Les équipes devraient :
Maintenir la cohérence des dimensions des vecteurs au sein de chaque modalité (par exemple, 384-D pour le texte, 512-D pour les images) ; pour les ensembles de données à modalités mixtes, utiliser des index séparés ou compléter/tronquer si nécessaire pour aligner les dimensions avant la recherche de similarité (cela doit être fait avec soin pour éviter la perte d’information ou d’alignement)
Versionner et taguer les représentations lorsque plusieurs types de modèles ou sources sont utilisés
Les pipelines de représentations sont souvent gérés en dehors de la base de données par les équipes MLOps ou data science, avec le stockage des vecteurs géré via des insertions SQL ou des traitements par lots.
La mise en œuvre de la recherche vectorielle dans les bases de données SQL permet de créer fonctionnalités pilotées par l’IA tout en préservant la cohérence, la sécurité et l’extensibilité des systèmes relationnels. Pour les équipes déjà opérationnelles sur SQL, cette approche offre un chemin rapide et sans friction vers la production et une base pérenne qui s’adapte naturellement à mesure que les charges de travail, les volumes de données, les modalités d’intégration et les cas d’usage se développent. Étant donné que les vecteurs coexistent avec les tables traditionnelles, les équipes peuvent réutiliser des modèles éprouvés de partitionnement, de réplication et de gouvernance au lieu de migrer vers un magasin séparé plus tard.
L’avenir de la recherche alimentée par l’IA dans les bases de données d’entreprise
À mesure que l’adoption de l’IA continue de s’étendre à travers les industries, la capacité d’intégrer la recherche pilotée par l’apprentissage automatique dans les systèmes opérationnels principaux deviendra une capacité de base – et non une fonctionnalité de niche.
Les entreprises appliquent déjà la recherche sémantique à des processus structurés tels que les catalogues de produits, les tickets de support, les journaux financiers et les interactions avec les clients. Ce qui a commencé comme une fonction de bases de données vectorielles spécialisées se déplace maintenant vers le cœur relationnel.
Le support intégré des vecteurs devient incontournable
Tout comme les bases de données ont évolué pour prendre en charge la recherche en texte intégral, les données géospatiales et JSON, le support intégré pour les représentations vectorielles suit désormais une voie similaire. Plutôt que de forcer les utilisateurs à gérer des systèmes vectoriels séparés, les bases de données modernes commencent à offrir :
Types de données vectorielles intégrées pour le stockage et l’indexation
Index ANN natifs optimisés pour la recherche de similarité
Intégration avec la planification et l’exécution des requêtes SQL standard
Cette convergence simplifie le déploiement, réduit la complexité architecturale et rapproche les processus impliquant l’IA da la où les données des entreprises résident déjà. Ce changement nécessite l’intégration de données diversifiées et leur interrogation dans un cadre unifié. Les bases de données capables de prendre en charge les représentations et les requêtes structurées joueront un rôle crucial dans ces pipelines.
Processus impliquant l’IA dans la base de données
À mesure que les opérations vectorielles deviennent plus courantes, la distinction entre les processus impliquant l’IA et les bases de données opérationnelles continue de s’estomper. Déjà, certaines plateformes permettent aux modèles d’IA de générer et d’insérer des représentations directement dans la base de données. D’autres prennent en charge l’appel d’API externes ou intègrent des services depuis la couche de logique applicative.
À l’avenir, nous pouvons nous attendre à :
- Rapprocher plus étroitement les modèles d’IA et le stockage vectoriel.
- Les pipelines de représentations vectorielles sont exécutés au sein de vos jobs ETL ou CDC.Chaque nouvelle ligne ou ligne mise à jour passe par le modèle, et le nouveau vecteur est immédiatement écrit.
- L’inférence opérationnelle est alimentée par des requêtes vectorielles au moment de l’exécution. Par exemple, lorsqu’un concurrent met à jour le prix d’un article, un détaillant en ligne peut non seulement mettre à jour le prix du même article – mais aussi celui d’articles similaires (par exemple, tous les machines à pâtes similaires à celle mise à jour).
Ces capacités permettront aux applications de passer de la recherche en tant que fonctionnalité à la recherche intelligente, où les résultats sont personnalisés, contextuels et profondément intégrés dans l’expérience utilisateur.
Flux de travail IA incluant la base de données
Les modèles d’IA comme GPT d’OpenAI, Claude d’Anthropic, et d’autres sont déjà d’excellents outils pour écrire des applications. Avec l’aide du Model Context Protocol (MCP), les modèles d’IA peuvent invoquer des services externes et même exécuter du code, y compris du code qui s’exécute dans votre base de données. Cela permet aux développeurs d’exposer l’accès à la base de données aux LLM de manière contrôlée. Les entrées en langage naturel sont converties en SQL structuré via des appels de fonctions sécurisés, rendant possible pour les modèles de requêter, mettre à jour et interagir avec la base de données en utilisant des appels de fonctions sécurisés exposés par un serveur MCP.
En général, un serveur MCP expose des appels de fonction prédéfinis à la logique backend, aux API ou aux bases de données. En utilisant MariaDB comme exemple, le schéma suivant illustre le concept :

07 Conclusion et recommandations stratégiques
La recherche vectorielle n’est plus une fonctionnalité expérimentale réservée aux équipes spécialisées en IA. Elle devient un composant fondamental des applications d’entreprise qui ajoutent des expériences contextuelles, sémantiques et personnalisées.
Le défi pour la plupart des organisations n’est pas de savoir s’il faut adopter la recherche vectorielle, mais comment le faire sans ajouter de complexité inutile. Très souvent, la réponse réside dans l’extension des bases de données relationnelles existantes pour prendre en charge les représentations vectorielles et les requêtes de similarité.
Les bases de données SQL avec des capacités vectorielles intégrées offrent une voie pratique. Elles permettent l’émergence de modèles de recherche hybrides, prennent en charge le filtrage structuré en parallèle de l’indexation ANN, et réduisent la surcharge de gestion de plusieurs systèmes de données. Cela les rend bien adaptées à des cas d’utilisation comme la récupération sémantique de documents, les recommandations de produits et le support assisté par l’IA.
Les entreprises qui évaluent la recherche vectorielle devraient considérer :
- Proximité avec les données existantes : La recherche vectorielle peut-elle être effectuée là où se trouvent déjà vos données opérationnelles ?
- Complexité des requêtes : Vos charges de travail nécessitent-elles un filtrage hybride structuré et
sémantique ? - Processus d’équipe : Les développeurs, les DBA et les data scientists peuvent-ils collaborer plus facilement au sein d’une plateforme unifiée ?
En alignant l’architecture de la recherche avec ces contraintes opérationnelles, les entreprises peuvent déployer une recherche augmentée par l’IA plus rapidement, plus efficacement et à moindre coût.
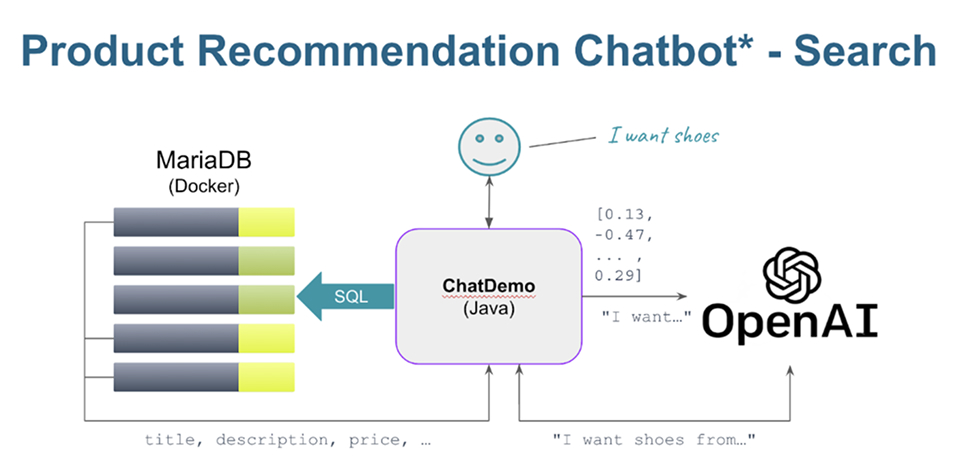
Pour voir ces modèles en action, clonez https://github.com/alejandro-du/mariadb-rag-demo-java et explorez comment fonctionne la recherche vectorielle basée sur SQL à l’aide d’exemples concrets.
La recherche recherche vectorielle intégrée de MariaDB : découvrez-la en action
Déverrouillez la puissance de la plateforme MariaDB Enterprise et de ses capacités vectorielles en utilisant une démonstration complète de recherche vectorielle. Dans cette démonstration, vous discutez avec l’API OpenAI (le modèle programmatique derrière ChatGPT) et connectez sa sortie à des produits dans une instance locale de MariaDB. Pour l’essayer, clonez : https://github.com/alejandro-du/mariadb-rag-demo-java
et suivez les instructions.
08 MariaDB Enterprise Platform : une solution complète pour les exigences modernes en matière de données
MariaDB Enterprise Platform offre une solution de base de données de bout en bout conçue pour les charges de travail modernes. En prenant en charge à la fois les cas d’utilisation transactionnels et analytiques, elle unifie les données structurées et semi-structurées (relationnelles et JSON) sur une seule plateforme qui fonctionne de manière transparente dans les environnements sur site, cloud et hybrides. Les entreprises peuvent rationaliser l’infrastructure, réduire la prolifération des systèmes et développer des applications plus rapidement en utilisant un système puissant pour toutes les charges de travail.
MariaDB Enterprise Platform est conçue pour une haute disponibilité, la reprise après sinistre et des performances de niveau production. Que ce soit par le basculement automatique, la mise à l’échelle de la lecture ou le clustering multi-maîtres, la plateforme maintient les données disponibles et les opérations fluides – même en cas de défaillance. Les clients Entreprise bénéficient également de chiffrement de bout en bout, audit granulaire et de l’intégration avec des systèmes de sécurité externes comme HashiCorp Vault.
MariaDB réunit la recherche vectorielle, les charges de travail transactionnelles et analytiques dans une seule base de données. La réplication intégrée, le stockage en colonnes et l’extension distribuée maintiennent la rapidité des requêtes de similarité et un débit élevé. Vous évitez les frais de licence des bases de données propriétaires et la complexité de gérer un magasin vectoriel séparé. Votre équipe conserve ses compétences et outils SQL tout en déplaçant les charges de travail d’IA vers une plateforme de niveau entreprise conçue pour la croissance.
Dans le cadre de l’engagement de MariaDB envers une plateforme de bout en bout, MariaDB Enterprise Server, la base de données qui est au cœur de MariaDB Enterprise Platform, inclut désormais la recherche vectorielle intégrée, transformant MariaDB en une base de données relationnelle + vectorielle. Cela vous permet d’effectuer des recherches de similarité directement dans la même base de données que vous utilisez pour les transactions et l’analytique – aucun moteur vectoriel additionnel requis.
Avec les bases de données MariaDB, les développeurs peuvent exécuter des recherches sémantiques, des filtrages et des requêtes hybrides (SQL + vecteur) en utilisant des outils et interfaces familiers. Étant intégré, la recherche vectorielle bénéficie de toute la fiabilité, la sécurité et l’évolutivité de la plateforme, évitant ainsi la complexité, la latence et le coût supplémentaires induits par une base de données vectorielles externe.
Applications pratiques de la recherche vectorielle
Récupération des connaissances d’entreprise
Améliorez la recherche interne et les prises de décision en trouvant des données sémantiquement pertinentes parmi les documentations, wikis et données historiques de clients au sein de grands volumes de données.
Recommandations de produits pour le commerce électronique
Utilisez en temps réel des vecteurs de similarité de produits et de comportement pour offrir des expériences d’achat hautement personnalisées et augmenter la conversion.
Assistants IA pour le support client
Récupérez les cas historiques ou solutions les plus pertinents en utilisant la recherche vectorielle, permettant aux assistants IA génératifs de répondre de manière plus précise et efficace.
En intégrant directement la recherche vectorielle dans sa plateforme, MariaDB permet aux entreprises de développer des applications d’IA tout en conservant la performance, la fiabilité et la simplicité d’une solution de base de données unique. C’est la base de données alimentée par l’IA qui offre des résultats concrets – sans le prix d’une solution Entreprise.
09 À propos de MariaDB
MariaDB élimine les contraintes et la complexité des bases de données propriétaires, afin de réinvestir dans l’essentiel : développer rapidement des applications innovantes, orientées client. Les entreprises s’appuient sur une plateforme de base de données cloud unique pour tous leurs besoins, déployable en minutes pour des usages transactionnels, analytiques, hybrides et IA. Des organisations telles que Deutsche Bank, DBS Bank, Red Hat, ServiceNow et Samsung font confiance à MariaDB, qui crée de la valeur sans le fardeau financier des fournisseurs historiques.
Plus d’informations: mariadb.com
Contactez-nous pour en savoir plus sur MariaDB