
Ein praktischer Leitfaden zu KI und Vektorsuche in relationalen Datenbanken
01 Zusammenfassung für Führungskräfte
Künstliche Intelligenz (KI) ist kein zukunftsorientiertes Experiment mehr – sie verändert bereits die Betriebsweise von Unternehmen. Und im Kern vieler KI-gestützter Anwendungen liegt eine neue Anforderung: die Vektorsuche.
Von agentischen KI-Systemen über Empfehlungssysteme, Wissensdatenbanken und semantische Dokumentensuche basieren diese Fähigkeiten auf der Speicherung und Abfrage von Vektoreinbettungen – nicht nur auf traditionellen Zeilen und Spalten. Die Vektorsuche ermöglicht es Anwendungen, Ergebnisse basierend auf Bedeutung und Ähnlichkeit abzurufen anstatt auf der Basis exakter Übereinstimmungen.
Bis vor kurzem bedeutete die Implementierung von Vektorsuche, dass eine separate Vektordatenbank neben Ihrem primären relationalen System eingeführt werden musste. Das erhöhte die architektonische Komplexität sowie den betrieblichen Aufwand und führte zu neuen Integrationsrisiken.
Das beginnt sich jedoch zu ändern.
Relationale Datenbanken entwickeln sich weiter, um die Vektorsuche nativ zu unterstützen. Dies ermöglicht es Organisationen, strukturierte Abfragen und Ähnlichkeitssuche innerhalb einer einzigen Plattform zu vereinen – wodurch KI-Funktionen näher an Produktionssysteme herangeführt und die Distanz zwischen Experimentieren und Einsatz verringert wird.
Dieser Leitfaden bietet eine praktische Einführung in die Vektorsuche: was sie ist, warum sie wichtig ist und wie sie in eine moderne Unternehmensdatenstrategie passt. Wir werden wichtige technische Überlegungen erkunden – von Indexierungsstrategien bis hin zu hybriden Abfragemustern – und Ihnen helfen zu verstehen, wann eine relationale Datenbank mit integrierter Vektorunterstützung (wie MariaDB Enterprise Platform) die richtige Wahl ist und wann eine spezialisierte Vektormaschine dennoch erforderlich sein könnte.
Wenn Sie planen, Ihre bestehende Infrastruktur zu erweitern, um KI-Workloads zu unterstützen, hilft Ihnen dieser Leitfaden, die Anwendungsfälle, Implementierungsmuster und Zielkonflikte abzuwägen, die für die Skalierung der Vektorsuche im Unternehmen am wichtigsten sind.
- Vektorsuche hilft KI-Anwendungen, Bedeutung und Kontext zu verstehen, indem sie über die traditionelle Stichwortsuche hinausgeht und Funktionen wie personalisierte Empfehlungen und intelligente Chatbots ermöglicht.
- Moderne relationale Datenbanken integrieren jetzt nativ die Vektorsuche, was Ihre Systemarchitektur vereinfacht, indem traditionelle Datenabfragen mit KI-gesteuerten Ähnlichkeitssuchen auf einer einzigen Plattform vereint werden.
- Durch die Verwendung einer relationalen Datenbank mit integrierter Vektorsuche wie der MariaDB Enterprise Platform können Sie KI-Funktionen schneller und effizienter bereitstellen, indem Sie Ihr vorhandenes SQL-Knowhow nutzen und den betrieblichen Aufwand reduzieren.
02 Vektorsuche in der KI verstehen
Traditionelle Suchsysteme basieren auf der Übereinstimmung von Schlüsselwörtern oder strukturierten Daten. Während sie für exakte Abfragen effektiv sind, scheitern sie daran, Bedeutung, Absicht oder Kontext zu erfassen. Diese sind wesentliche Fähigkeiten für moderne KI-Anwendungen. Die Vektorsuche behebt diese Einschränkung.
Im Kern der Vektorsuche stehen Vektoreinbettungen, die numerische Darstellungen von Daten sind, die von maschinellen Lernmodellen erzeugt werden. Diese Einbettungen ordnen Text, Bilder oder andere Inhalte in einen vieldimensionalen Raum, in dem die Nähe die semantische Ähnlichkeit widerspiegelt. Zwei Support-Tickets zum Beispiel können unterschiedlich formuliert sein, aber nahe beieinander im Vektorraum liegen, wenn sie dasselbe zugrunde liegende Problem beschreiben. Ein Vektorraum ist einfach ein (sehr) vieldimensionales Raster. Jede Einbettung ist ein Punkt in diesem Raster, so dass Elemente mit ähnlicher Bedeutung zusammen gruppiert werden.
Ein Vektorsuchsystem ermöglicht Abfragen wie „finde Transaktionen, die dieser ähnlich sind“ oder „rufe Dokumente ab, die in ihrer Bedeutung mit diesem Absatz verwandt sind“. Anstatt exakter Übereinstimmungen werden die Ergebnisse nach der Distanz zwischen Vektordarstellungen bewertet, wobei Algorithmen wie Kosinusähnlichkeit oder euklidische Distanz verwendet werden.
In der Praxis wird die Vektorsuche häufig verwendet, um Folgendes zu erreichen:
- Personalisierte Empfehlungen basierend auf dem Nutzerverhalten oder den Vorlieben
- Semantische Dokumentenabfrage, bei der Embeddings verwendet werden, um konzeptionell verwandte Informationen zu finden
- Konversationelle KI, bei der Kontexteinbettungen helfen, Chatbot-Antworten zu verfeinern
Einige Produktionssysteme profitieren von einer Kombination aus Suche und Abfrage, bei der strukturierte Filter wie Benutzersegment, Zeitstempel oder Produktkategorie mit Vektorsimilarität kombiniert werden. Dieser Ansatz ermöglicht Anwendungsfälle, die sowohl operativ fundiert als auch semantisch reichhaltig sind.
Durch die direkte Integration von Vektorsuche in häufig genutzte relationale Datenbanken können Organisationen diese Workloads unterstützen, ohne neue Infrastrukturen einzuführen. Vektor-unterstützte Abfragen können neben herkömmlichem SQL ausgeführt werden und KI-Funktionen in vertrauten Systemen und Tools freischalten.
03 Grundüberlegungen zur Datenbank für Vektorsuche
Die Vektorsuche führt eine neue Klasse von Abfragen ein, die semantische Ähnlichkeit über exakte Übereinstimmungen priorisiert. Obwohl konzeptionell einfach, stellt die Implementierung der Vektorsuche im großen Maßstab besondere Herausforderungen für Datenbanksysteme dar. Leistung, Indexierung und Integration in bestehende Abfrage-Workflows sind entscheidende Faktoren bei der Wahl des richtigen Ansatzes.
Leistung und Skalierbarkeit
Im Gegensatz zu traditionellen Indizes, die Gleichheits- oder Bereichsabfragen unterstützen, sind Vektorindizes für die Suche nach dem ungefähren nächsten Nachbarn (Approximate Nearest Neighbor, ANN) optimiert. Diese Algorithmen tauschen perfekte Genauigkeit gegen Geschwindigkeit ein, was Echtzeit-Ähnlichkeitsabfragen auch über große Datensätze ermöglicht.
Drei Ansätze werden häufig verwendet:
HNSW (Hierarchical Navigable Small Worlds)
Ein graphbasierter Index, der schnelle Suchleistung und hohe Trefferquote bietet. Er erfordert erheblichen Speicher, funktioniert aber gut für Anwendungen mit niedriger Latenz.
IVFFlat (Invertierte Datei mit flachen Vektoren)
Eine clusterbasierte Methode, die Indexierungszeit und Sucheffizienz ausbalanciert. Sie kann auf große Datensätze skaliert werden, erfordert jedoch möglicherweise Anpassungen.
Brute-Force-Suche
Eine erschöpfende Methode, die genaue Ergebnisse garantiert. Obwohl sie präzise ist, ist sie rechnerisch aufwendig und wird typischerweise für kleine Datensätze oder Offline-Bewertungen verwendet.
Vektorsuchsysteme müssen auch gleichzeitige Zugriffsmuster unterstützen, insbesondere wenn sie in transaktionale Anwendungen integriert sind. Beispielsweise können einige Workflows Hunderte von Ähnlichkeitsabfragen pro Sekunde erfordern, die parallel zu Einfügungen, Aktualisierungen und analytischen Lesevorgängen laufen.
Speicher- und Einbettungsverwaltung
Vektor-Einbettungen werden häufig als Arrays von 32-Bit-Gleitkommazahlen gespeichert oder gelegentlich für die Leistung auf kleinere Größen quantisiert. Die Verwaltung dieser Darstellungen im großen Maßstab erfordert weiterhin kompakte Speicherformate und intelligente Indexierungsstrategien. Einige Systeme komprimieren oder quantisieren Vektoren; andere priorisieren schnelle Lesevorgänge für latenzarme Inferenz.
Datenbanken müssen auch Einfüge-/Aktualisierungsvorgänge in einer Geschwindigkeit unterstützen, die den vorgelagerten KI-Pipelines entspricht. Zum Beispiel können Produktkataloge, Verhaltensprotokolle oder Transaktionshistorien kontinuierlich Einbettungen erzeugen.
Integrierte vs. Plug-in-Architekturen
Einige Vektorsysteme werden als Erweiterungen auf allgemeinen Datenbanken aufgebaut. Andere sind in die allgemeine Datenbank integriert. Integrierte Implementierungen bieten oft eine bessere Leistung, da sie direkt mit der Speicher-Engine, dem Optimierer und dem Indexierungssystem verbunden sind.
Zum Beispiel umfasst MariaDB Enterprise Platform integrierte Vektorindizierung, die eine engere Integration und bessere Parallelität bietet als Plug-in-Modelle, die auf PostgreSQL aufgesetzt sind.
Hybride Vektor- und SQL-Integration
Viele Anwendungsfälle kombinieren strukturierte Filter mit Ähnlichkeitssuche. Eine typische Abfrage könnte nach Benutzertyp, Produktkategorie oder Datum filtern und dann die Ergebnisse nach Vektordistanz sortieren. Die Unterstützung von hybriden Abfragen – die relationale Prädikate und ANN-Retrieval kombinieren – ist für praktische Anwendungen unerlässlich.
Beispielabfrage in der MariaDB Enterprise Platform:
E-Commerce
Zeig mir zehn Jacken wie diese, unter 200 $, die auf Lager sind.
SELECT product_id, name, price
FROM products
WHERE category = 'jackets'
AND price < 200
AND in_stock = TRUE
ORDER BY VEC_DISTANCE(embedding, ?) -- Abfragevektor hier anbinden
LIMIT 10;
Kundensupport
Finden Sie aktuelle Tickets wie dieses von Premium-Kunden.
SELECT ticket_id, subject, opened_at
FROM support_tickets
WHERE customer_tier = 'Premium'
AND opened_at >= CURRENT_DATE - INTERVAL 30 DAY
ORDER BY VEC_DISTANCE(ticket_embedding, ?) -- neuen Ticket-Vektor anbinden
LIMIT 5;
Wissensdatenbank
Rufen Sie Artikel ab, die dieser Frage ähneln, für das Produkt „MariaDB Enterprise Platform“, veröffentlicht in den letzten sechs Monaten.
SELECT doc_id, title, published_at
FROM kb_articles
WHERE product = 'MariaDB Enterprise Platform'
AND published_at >= CURRENT_DATE - INTERVAL 6 MONTH
ORDER BY VEC_DISTANCE(article_embedding, ?) -- binde Absatzvektor an
LIMIT 15;
Medienstreaming
Finde zehn Actionfilme wie diesen, mit Altersfreigabe ab 13 Jahren, die nach 2015 veröffentlicht wurden.
SELECT movie_id, title, release_year
FROM movies
WHERE genre = 'Action'
AND rating = 'PG-13'
AND release_year >= 2015
ORDER BY VEC_DISTANCE(movie_embedding, ?) -- binde Seed-Film-Vektor an
LIMIT 10;
Talentsuche
Zeige Kandidaten, deren Lebensläufe diesem Profil ähneln, die sich in den Vereinigten Staaten befinden und über ≥ 5 Jahre Erfahrung verfügen.
SELECT candidate_id, full_name, years_experience, last_active
FROM resumes
WHERE VEC_DISTANCE(resume_embedding, ?) < 0,35 -- strikte Ähnlichkeitsschwelle
AND country_code = 'US'
AND years_experience >= 5
ORDER BY last_active DESC -- sekundäre Sortierung
LIMIT 12;
Diese Beispiele zeigen, wie MariaDB relationale Prädikate mit einer Rangfolge der ungefähren nächsten Nachbarn in einem einzigen Abfrageplan kombiniert. Sie erhalten eine schnelle Ähnlichkeitssuche, traditionelle SQL-Garantien und keinen betrieblichen Aufwand für den Betrieb einer separaten Vektordatenbank.
04 Anwendungsfälle, in denen Allzweckdatenbanken mit Vektorsuche glänzen
Während eigenständige Vektordatenbanken für groß angelegte semantische Abfragen konzipiert sind, beinhalten viele produktive Anwendungsfälle strukturierte Daten, betriebliche Anforderungen oder bestehende SQL-Infrastrukturen. In diesen Fällen reduziert die Einbettung der Vektorsuche direkt in eine relationale Datenbank die Komplexität, vereinfacht die Integration und beschleunigt die Bereitstellung.
Die folgenden Beispiele verdeutlichen Anwendungsfälle, in denen integrierte Vektorfunktionen in SQL-Datenbanken – wie MariaDB Enterprise Platform – praktische Vorteile bieten.
Unternehmenswissenserfassung
Interne Dokumentation, Wikis und Support-Inhalte erstrecken sich oft über mehrere Teams und Formate. Traditionelle Stichwortsuche hat Schwierigkeiten, semantisch relevante Materialien zu finden. Durch das Einbetten von Inhalten und Benutzeranfragen in Vektoren können Unternehmen Ergebnisse liefern, die der Bedeutung entsprechen, nicht nur der Wortwahl.
Das Speichern und Abfragen von Einbettungen in derselben Datenbank, die auch die Dokumentmetadaten enthält, ermöglicht das Filtern nach Team, Abteilung oder Datum, während die Relevanz berücksichtigt wird.
Produktempfehlungen im E-Commerce
Empfehlungssysteme basieren oft auf der Ähnlichkeit zwischen Produkten, Benutzerpräferenzen oder Sitzungsverhalten. Einbettungen, die diese Beziehungen repräsentieren, können über Vektorsuche abgefragt werden, um Empfehlungen wie „ähnliche Artikel“ oder „Benutzer haben auch angesehen“ zu liefern. Die Unterbringung dieser Logik in einer relationalen Datenbank vereinfacht die Bestandsfilterung, Lokalisierung und Personalisierung.
KI-Assistenten für den Kundensupport
Das Abrufen relevanter früherer Fälle ist entscheidend für die Leistungsfähigkeit von KI-Assistenten und menschlichen Support-Agenten. Das Einbetten bestehender Tickets und Support-Inhalte ermöglicht die Abfrage nach Ähnlichkeit zu neuen Anfragen. Die Kombination von Vektorrangfolgen mit strukturierten Metadaten (z. B. Produkttyp, Kundenschicht) unterstützt hochpräzise Ergebnisse innerhalb eines Support-Workflows.
05 In welchen Fällen Sie eine Spezialdatenbank verwenden könnten
Verschiedene Datenbanken bieten unterschiedliche Vektorsuchfunktionen. Beispielsweise decken die integrierten Vektorfunktionen von MariaDB das gängige „ANN-plus-SQL“-Muster für die meisten Produktions-Workloads ausreichend ab. Wenn Ihre Suchanforderungen IVF-PQ, HNSW mit dynamischem Kantenbeschneiden, Sub-Vektor-Produktquantisierung oder eine strenge Kontrolle über die Intervalle der Codebuch-Neu-Trainings erfordern, müssen Sie möglicherweise eine spezialisierte Datenbank in Betracht ziehen. Selbst in einem solchen Fall werden Sie wahrscheinlich eine Mischung aus einer allgemeinen Datenbank und einer spezialisierten Datenbank verwenden wollen. Die relationale Schicht kann weiterhin Metadaten, Joins und transaktionale Garantien verwalten, während die spezialisierte Datenbank Ihren speziellen Vektoralgorithmus handhaben kann.
06 Implementierung von Vektorsuche in SQL-Datenbanken
Das direkte Einbetten der Vektorsuche in eine SQL-Datenbank ermöglicht eine hybride Suche in vertrauten Datenumgebungen. Dies reduziert die Infrastrukturkomplexität und bringt KI-gestützte Funktionen näher an die Systeme, in denen operative Daten gespeichert sind. Eine erfolgreiche Implementierung erfordert das Management von Einbettungen, die Optimierung von Indizes und ein sorgfältiges Abfragedesign.
Speichern und Abfragen von Vektoren
Vektordaten werden typischerweise als Arrays fester Länge von 32-Bit-Floats gespeichert. SQL-Datenbanken mit integrierter Vektorunterstützung behandeln diese als eigenen Datentyp, was direkte Einfügung, Indizierung und Abfrage ermöglicht.
Beispiel
Einbetten eines Embeddings
in eine Tabelle
INSERT INTO knowledge_base (id, content, embedding)
VALUES (101, 'Wie man SSO aktiviert', VEC_FROM_TEXT('[0.13, 0.48, 0.91, ...]'));
Beispiel
Abfrage nach Ähnlichkeit
SELECT id, content
FROM knowledge_base
ORDER BY VEC_DISTANCE(embedding, VEC_FROM_TEXT('[0.12, 0.49, 0.90, ...]'))
LIMIT 3;
Einige Datenbanken unterstützen auch die direkte Integration mit Python oder API-generierten Einbettungen, wodurch die Anwendungslogik Vektoren zur Abfragezeit übergeben kann.
Indexierung für Leistung
Für groß angelegte Workloads ist die Vektorindizierung unerlässlich. Näherungsweise nächste Nachbarindizes wie HNSW bieten sublineare Suchleistung mit hoher Genauigkeit. Diese Indizes können basierend auf den Anforderungen der Anwendung konfiguriert werden – größere Graphen verbessern die Genauigkeit, erfordern jedoch mehr Speicher.
Bewährte Praktiken umfassen:
- Auswahl von Indexierungsparametern, die zu Ihrer Abfragelast passen
- Sicherstellen, dass ausreichend Speicher vorhanden ist, um Indizes im Speicher für schnellen Zugriff zu halten
- Periodisches Neuaufbauen von Indizes, wenn sich die Einbettungsverteilungen ändern
Berücksichtigung des Recalls
Viele Datenbanken rühmen sich ihrer Gesamtleistung bei der Vektorsuche, jedoch sollte ein wesentlicher Aspekt Ihrer Überlegungen zu jedem Benchmark oder Anspruch die verwendete Recall-Einstellung sein.
- 0,9 ist ein guter Ausgangspunkt für die meisten produktiven Anwendungsfälle.
- 0,95 ist in der Regel sicherer für Anwendungen im RAG-Stil (retrieval-augmented generation), um Halluzinationen zu reduzieren.
- 0,8 zur Anpassung der Reaktionsfähigkeit könnte für UI-Vorschauen, Empfehlungen usw. ausreichen.
Was „Recall“ in diesem Kontext tatsächlich bedeutet:
Beim Vektorsuchen bezieht sich „Recall“ normalerweise darauf, wie genau der ANN-Algorithmus die exakten nächsten Nachbarn (Ground Truth) trifft.
Zum Beispiel:
- Wenn die 10 nächsten Nachbarn der Ground-Truth {a, b, c, …, j} sind
- Und Ihr ANN-Algorithmus zurückgibt {a, b, c, d, f, h, i, j, k, l}
- Dann ist der Recall@10 = 8 / 10 = 0,8
Im Allgemeinen führt die Verwendung einer Einstellung von weniger als 0,8, obwohl sie beeindruckende Ergebnisse für Benchmarks liefern kann, zu Ergebnissen, die für reale, produktive Anwendungsfälle nicht akzeptabel sind.
Hybride Suche und SQL-Filterung
Einer der Hauptvorteile der Implementierung von Vektorsuche in SQL ist die Möglichkeit, Ähnlichkeitssuche mit strukturierten Filtern zu kombinieren.
Beispiel
Abrufen von Support-Tickets, die einem bestimmten Problem ähneln, gefiltert nach Produktversion und Priorität
SELECT id, title
FROM support_tickets
WHERE product_version = '2.1'
AND priority = 'High'
ORDER BY VEC_DISTANCE(embedding, VEC_FROM_TEXT('[...]'))
LIMIT 5;
Diese enge Integration unterstützt die kontextuelle KI-Abfrage, ohne dass eine Pipeline über mehrere Systeme erforderlich ist.
Einbettungsverwaltung
Effiziente Speicherung und Lebenszyklusverwaltung von Einbettungen sind entscheidend. Teams sollten Folgendes beachten:
Halten Sie die Vektordimensionen innerhalb jeder Modalität konsistent (z. B. 384-D für Text, 512-D für Bilder). Bei gemischten Modalitätsdatensätzen verwenden Sie separate Indizes oder füllen Sie auf bzw. verkürzen Sie nach Bedarf, um die Dimensionen vor der Ähnlichkeitssuche auszurichten (dies muss sorgfältig durchgeführt werden, um Informationsverlust oder Fehlanpassungen zu vermeiden)
Versionieren und Taggen von Einbettungen, wenn mehrere Modelltypen oder Quellen verwendet werden
Einbettungspipelines werden oft außerhalb der Datenbank von Data-Science- oder MLOps-Teams verwaltet, wobei die Vektorspeicherung über SQL-Einfügungen oder Batch-Jobs erfolgt.
Die Implementierung der Vektorsuche in SQL-Datenbanken ermöglicht KI-gesteuerte Funktionen, während die Konsistenz, Sicherheit und Erweiterbarkeit relationaler Systeme erhalten bleiben. Für Teams, die bereits mit SQL arbeiten, bietet dieser Ansatz einen schnellen, reibungslosen Weg zur Produktion und eine zukunftssichere Grundlage, die sich natürlich skalieren lässt, wenn Arbeitslasten, Datenvolumen und Einbettungsmodalitäten sowie Anwendungsfälle wachsen. Da Vektoren neben traditionellen Tabellen existieren, können Teams bewährte Sharding-, Replikations- und Governance-Muster wiederverwenden, anstatt später zu einem separaten Speicher zu migrieren.
Die Zukunft der KI-gestützten Suche in Unternehmensdatenbanken
Da die Einführung von KI in verschiedenen Branchen weiter zunimmt, wird die Fähigkeit, durch maschinelles Lernen gesteuerte Suche in zentrale Betriebssysteme zu integrieren, zu einer grundlegenden Fähigkeit – und nicht zu einem Nischenmerkmal.
Unternehmen setzen bereits semantische Suche in strukturierten Workflows wie Produktkatalogen, Supportfällen, Finanzprotokollen und Kundeninteraktionen ein. Was als Funktion spezialisierter Vektordatenbanken begann, bewegt sich nun in den relationalen Kern.
Integrierte Vektorunterstützung wird zum Standard
Genauso wie Datenbanken sich weiterentwickelt haben, um Volltextsuche, räumliche Daten und JSON zu unterstützen, folgt nun die integrierte Unterstützung für Vektoreinbettungen einem ähnlichen Weg. Anstatt Benutzer zu zwingen, separate Vektorsysteme zu verwalten, bieten moderne Datenbanken folgendes an:
Eingebaute Vektordatentypen für Speicherung und Indexierung
Native ANN-Indizes, optimiert für Ähnlichkeitssuche
Integration mit der standardmäßigen SQL-Abfrageplanung und -ausführung
Diese Konvergenz vereinfacht die Bereitstellung, reduziert die architektonische Komplexität und bringt KI-Workflows näher dorthin, wo Unternehmensdaten bereits vorhanden sind. Dieser Wandel erfordert das Einbetten und Abfragen vielfältiger Daten innerhalb eines einheitlichen Rahmens. Datenbanken, die Einbettungen und strukturierte Abfragen unterstützen können, werden in diesen Pipelines eine entscheidende Rolle spielen.
KI-Workflows innerhalb der Datenbank
Da Vektoroperationen immer häufiger werden, verringert sich der Unterschied zwischen KI-Workflows und operativen Datenbanken zunehmend. Bereits jetzt ermöglichen einige Plattformen, dass KI-Modelle Einbettungen direkt in die Datenbank generieren und einfügen. Andere unterstützen das Aufrufen externer APIs oder Einbettungsdienste innerhalb der Anwendungslogik.
In Zukunft können wir folgendes erwarten:
- Engere Kopplung von KI-Modellausgaben und Vektorspeicherung.
- Einbettungspipelines laufen innerhalb Ihrer bestehenden ETL- oder CDC-Jobs.Jede neue oder aktualisierte Zeile durchläuft das Modell, und der frische Vektor wird sofort zurückgeschrieben.
- Operative Inferenz wird durch Vektorabfragen zur Laufzeit unterstützt. Zum Beispiel kann ein E-Commerce-Händler, wenn ein Konkurrent den Preis eines Artikels aktualisiert, nicht nur den Preis für denselben Artikel aktualisieren – sondern auch für ähnliche Artikel (d. h. alle generischen Nudelmaschinen, die dem aktualisierten ähnlich sind).
Diese Fähigkeiten werden es Anwendungen ermöglichen, sich von der Suche-als-Funktion hin zu Suche-als-Intelligenz zu entwickeln, bei der die Ergebnisse personalisiert, kontextbezogen und tief in die Benutzererfahrung integriert sind.
KI-Workflows einschließlich der Datenbank
KI-Modelle wie OpenAIs GPT, Anthropics Claude und andere sind bereits hervorragende Werkzeuge zum Schreiben von Anwendungen. Mit Hilfe des Model Context Protocol (MCP) können KI-Modelle externe Dienste aufrufen und sogar Code ausführen, einschließlich Code, der in Ihrer Datenbank läuft. Dies ermöglicht es Entwicklern, den Datenbankzugriff für LLMs auf kontrollierte Weise zu öffnen. Natürliche Spracheingaben werden durch sichere Funktionsaufrufe in strukturiertes SQL abgebildet, wodurch es Modellen möglich wird, die Datenbank abzufragen, zu aktualisieren und mit ihr zu interagieren, indem sie sichere Funktionsaufrufe verwenden, die von einem MCP-Server bereitgestellt werden.
Im Allgemeinen stellt ein MCP-Server vordefinierte Funktionsaufrufe für Backend-Logik, APIs oder Datenbanken bereit. Am Beispiel von MariaDB veranschaulicht das folgende Diagramm das Konzept:

07 Fazit und strategische Empfehlungen
Die Vektorsuche ist nicht mehr nur eine experimentelle Fähigkeit, die spezialisierten KI-Teams vorbehalten ist. Sie entwickelt sich zu einer grundlegenden Komponente von Unternehmensanwendungen, die kontextuelle, semantische und personalisierte Erlebnisse hinzufügen.
Die Herausforderung für die meisten Organisationen besteht nicht darin, ob sie die Vektorsuche einführen sollen, sondern wie sie dies tun können, ohne unnötige Komplexität hinzuzufügen. In vielen Fällen liegt die Antwort darin, bestehende relationale Datenbanken zu erweitern, um Vektoreinbettungen und Ähnlichkeitsabfragen zu unterstützen.
SQL-Datenbanken mit integrierten Vektorfunktionen bieten einen praktischen Weg nach vorn. Sie ermöglichen hybride Suchmuster, unterstützen strukturiertes Filtern neben ANN-Indexierung und reduzieren den Aufwand für die Verwaltung mehrerer Datensysteme. Dies macht sie gut geeignet für Anwendungsfälle wie semantische Dokumentenabfrage, Produktempfehlungen und KI-unterstützten Support.
Unternehmen, die die Vektorsuche evaluieren, sollten Folgendes berücksichtigen:
- Nähe zu vorhandenen Daten: Kann die Vektorsuche dort durchgeführt werden, wo sich Ihre operativen Daten bereits befinden?
- Abfragekomplexität: Erfordern Ihre Workloads eine hybride strukturierte und semantische Filterung?
- Team-Workflows: Können Entwickler, DBAs und Datenwissenschaftler innerhalb einer einheitlichen Plattform einfacher zusammenarbeiten?
Indem sie die Sucharchitektur an diese praktischen Gegebenheiten anpassen, können Organisationen KI-gestützte Suchfunktionen schneller, effizienter und kostengünstiger einsetzen.
MariaDBs Vector Embedded Search: Sehen Sie die Suche in Aktion
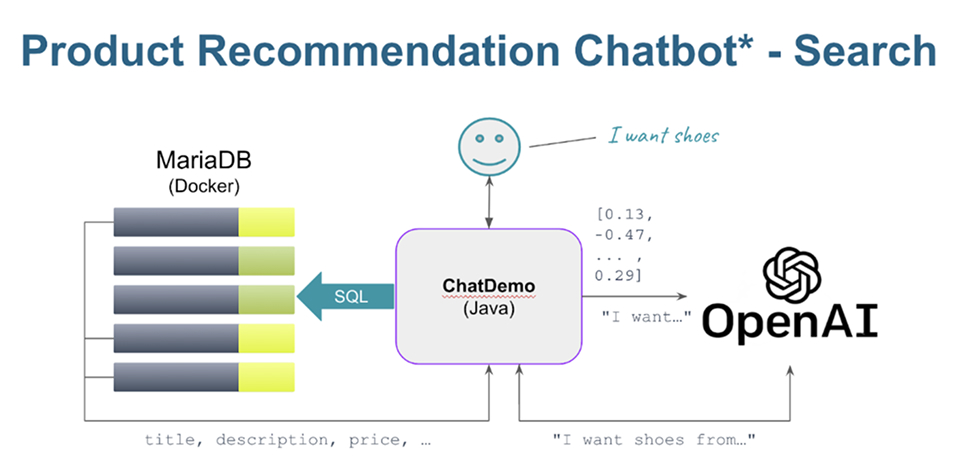
Entfesseln Sie die Leistungsfähigkeit der MariaDB Enterprise Platform und ihrer Vektorfunktionen mit einer vollständigen Vektorsuch-Demo. In dieser Demo chatten Sie mit der OpenAI API (dem programmatischen Modell hinter ChatGPT) und verbinden deren Ausgabe mit Produkten in einer lokalen MariaDB-Instanz. Um das auszuprobieren, klonen Sie: https://github.com/alejandro-du/mariadb-rag-demo-java und folgen Sie den Anweisungen.
08 MariaDB Enterprise Platform: Eine umfassende Lösung für moderne Datenanforderungen
MariaDB Enterprise Platform bietet eine End-to-End-Datenbanklösung, die für moderne Workloads entwickelt wurde. Sie unterstützt sowohl transaktionale als auch analytische Anwendungsfälle und vereint strukturierte und semi-strukturierte Daten (relational und JSON) in einer einzigen Plattform, die nahtlos in On-Premise-, Cloud- und Hybridumgebungen läuft. Organisationen können ihre Infrastruktur optimieren, den Wildwuchs reduzieren und Anwendungen schneller entwickeln, indem sie ein leistungsstarkes System für alle Workloads nutzen.
MariaDB Enterprise Platform ist für Hochverfügbarkeit, Notfallwiederherstellung und leistungsstarke Performance in Produktionsumgebungen konzipiert. Ob durch automatisches Failover, Lese-Skalierung oder Multi-Writer-Clustering – die Plattform hält Daten verfügbar und den Betrieb reibungslos am Laufen, selbst bei Ausfällen. Unternehmenskunden profitieren zudem von Ende-zu-Ende-Verschlüsselung, feinkörnigem Auditing und der Integration mit externen Sicherheitssystemen wie HashiCorp Vault.
MariaDB vereint Vektorsuche, transaktionale und analytische Workloads in einer Datenbank. Eingebaute Replikation, spaltenbasierte Speicherung und verteiltes Scale-out halten Ähnlichkeitsabfragen schnell und den Durchsatz hoch. Sie vermeiden die Lizenzgebühren geschlossener Datenbanken und umgehen die Komplexität, einen separaten Vektorspeicher zu betreiben. Ihr Team behält seine SQL-Kenntnisse und -Werkzeuge, während es KI-Workloads in eine unternehmensgerechte Plattform für Wachstum überführt.
Im Rahmen von MariaDBs Engagement für eine End-to-End-Plattform umfasst der MariaDB Enterprise Server, die zentrale Datenbank, die Teil der MariaDB Enterprise Platform ist, nun eine integrierte Vektorsuche, wodurch MariaDB zu einer relationalen + Vektor-Datenbank wird. Dies ermöglicht es Ihnen, eine Ähnlichkeitssuche direkt in derselben Datenbank durchzuführen, die Sie für Transaktionen und Analysen verwenden – keine zusätzliche Vektor-Engine ist erforderlich.
Mit MariaDB-Datenbanken können Entwickler semantische Suchen, Filterungen und hybride Abfragen (SQL + Vektor) mit vertrauten Tools und Schnittstellen ausführen. Da sie eingebettet ist, profitiert die Vektorsuche von der gesamten Zuverlässigkeit, Sicherheit und Skalierbarkeit der Plattform – und vermeidet die zusätzliche Komplexität, Latenz und Kosten externer Vektordatenbanken.
Praktische Anwendungen der Vektorsuche
Unternehmenswissenserfassung
Verbessern Sie die interne Suche und Entscheidungsfindung, indem Sie semantisch relevante Dokumentationen, Wikis und historische Kundendaten in großen Korpora finden.
Produktempfehlungen im E-Commerce
Verwenden Sie Echtzeit-Verhaltens- und Produktsimilaritätsvektoren, um hochgradig personalisierte Einkaufserlebnisse zu bieten und die Konversion zu steigern.
KI-Assistenten für den Kundensupport
Rufen Sie die relevantesten historischen Fälle oder Lösungen mithilfe der Vektorsuche ab, damit generative KI-Assistenten genauer und effizienter antworten können.
Durch die Einbettung der Vektorsuche direkt in seine Plattform ermöglicht MariaDB Unternehmen, KI-Anwendungen zu entwickeln, während die Leistung, Zuverlässigkeit und Einfachheit einer einzigen Datenbanklösung beibehalten werden. Es ist die KI-gestützte Datenbank, die reale Ergebnisse liefert – ohne den Preis für Unternehmen.
09 Über MariaDB
MariaDB möchte die Einschränkungen und Komplexität proprietärer Datenbanken beseitigen, damit Unternehmen wieder in das investieren können, was wirklich zählt – die schnelle Entwicklung innovativer, kundenorientierter Anwendungen. Unternehmen können sich auf eine einzige, vollständige Cloud-Datenbankplattform für alle ihre Anforderungen verlassen, die innerhalb weniger Minuten für Transaktions-, Analyse-, Hybrid- und KI-Anwendungsfälle bereitgestellt werden kann. MariaDB genießt das Vertrauen von Unternehmen wie der Deutschen Bank, der DBS Bank, Red Hat, ServiceNow und Samsung und bietet Kunden einen Mehrwert ohne die finanzielle Belastung wie bei herkömmlichen Datenbankanbietern.
Weitere Informationen finden Sie unter mariadb.com
Kontaktieren Sie uns, um mehr über MariaDB zu erfahren.